GLM 4.6V Open Source Multimodal Models with Native Tool Use
The race for the “finest AI mannequin” goes on, as Z.ai is the newest one to mark its entry with a brand new and developed mannequin. Calling it the GLM-4.6V, Z.ai has targeted on visible cues and illustration with this one. And therefore the “V” on the finish of its identify that resembles the present flagship mannequin by the corporate the GLM-4.6 (learn all about it right here).
So, in fact, this one isn’t just one other chat mannequin. It sees pictures, understands charts, writes code, and even causes like an actual teammate who really pays consideration. And the enjoyable half – no large setup is required to make use of it. GLM-4.6V is already obtainable on the Z.ai chats, with even a lighter model obtainable for native deployment and low-latency purposes.
On this weblog, we’ll discover what the brand new GLM-4.6V brings with it, and whether or not it’s particular sufficient so that you can use it or not. We are going to attempt to discover these solutions primarily based on a hands-on check with the brand new mannequin. So, let’s soar proper in and discover Z.ai’s new GLM-4.6V right here.
Key Options of Z.ai GLM-4.6V
Listed below are a few of the key options of the brand new GLM-4.6v.
Give it a PDF, a analysis paper, or a web page stuffed with pictures, tables, and formulation, and GLM-4.6V reads all of it like a human skilled. Which means that it doesn’t get confused by combined content material and may even create new paperwork that mix textual content and pictures completely.
In brief: In case your doc seems to be too messy, this mannequin can nonetheless learn it clearly and write a cleaner model for you.
2. Creates Picture-Wealthy Content material Routinely
It will possibly generate posts, studies, and visible write-ups that embrace each textual content and pictures. For this, the mannequin has been skilled sufficient to routinely determine the place footage match finest. That is nice for advertising and marketing, tutorials, or social content material.
In brief: You write much less > it codecs higher > your output seems to be able to publish.
3. Searches the Net Utilizing Photographs
Present it a photograph or screenshot, and it could search on-line to search out associated info. This helps with discovering the best product hyperlinks, rivals, model particulars, or extra pictures. It combines what it sees with what it is aware of.
In brief: Take a screenshot > ask something > and it finds actual solutions from the web.
4. Turns UI Screenshots into Working Code
Add a screenshot of a webpage or cell UI, and GLM-4.6V can generate clear HTML/CSS/JS for it. You’ll be able to spotlight components individually and inform the mannequin to change them, and it updates the code immediately.
In brief: Design > Screenshot > Code. No front-end abilities wanted in anyway.
5. Remembers Lengthy Inputs (128K Token Context)
You’ll be able to feed large PDFs, multi-page slides, and prolonged analysis notes to the GLM-4.6V, multi function shot. It retains observe of your entire doc, remembers references, and helps in-depth reasoning. To offer you a touch, Z.ai states in its weblog that the GLM-4.6V can precisely undergo “~150 pages of complicated paperwork, 200 slide pages, or a one-hour-long video in a single inference cross.”
In brief: As an alternative of splitting recordsdata into items, simply add as soon as and ask something about any half.
6. Performs Actually Nicely on Normal Benchmarks
GLM-4.6V is examined on many duties like visible understanding, logical reasoning, and studying lengthy paperwork. From the information shared by Z.ai, GLM 4.6V’s efficiency stands among the many finest open fashions.
Which brings us to our subsequent part – simply how good is the brand new GLM-4.6V on benchmarks?
GLM-4.6V Benchmark Efficiency
The desk beneath highlights the outcomes of the GLM-4.6V throughout a large set of benchmarks. These embrace visible reasoning, OCR, agentic duties, and long-context understanding.
GLM-4.6V Benchmark Efficiency
In nearly each main class, GLM-4.6V scores increased or stays very near the finest fashions obtainable at the moment, particularly in terms of reasoning over pictures, changing UI designs into code, and studying mixed-content paperwork. Its smaller Flash model additionally delivers spectacular accuracy whereas staying light-weight, making it a sensible selection for sooner and extra inexpensive deployments.
In brief, GLM-4.6V provides nice accuracy, robust reasoning, and dependable efficiency even on complicated visible duties. Precisely what you’d need from a next-generation multimodal AI.
Now let’s check this out in a real-world situation:
GLM-4.6V Arms-on
We examined the GLM-4.6V throughout 3 main duties – content material technology, deep internet search, and coding, primarily based on the strengths of the mannequin as outlined by Z.ai. Take a look at the check and its outcomes:
1. Multimodal Content material Era
Immediate: Undergo this PDF on Uber’s Elevate plans for eVTOLs. Produce a 500-word article explaining your entire idea, the place all it’s instructed to go reside, the way it will profit, and its limitations, if any. Complement the article with 1 or 2 diagrams explaining the idea, and a visible illustration of all of the cities marked for trial sooner or later
Output:
Our Take:
The mannequin was in a position to extract the best info from the intensive PDF and body an correct article primarily based on it, simply as instructed. A slight deviation I observed was with the eVTOL diagram that it made, which matched not one of the designs shared by Uber in its whitepaper. The remainder of the output was fairly good.
2. Deep Net Search
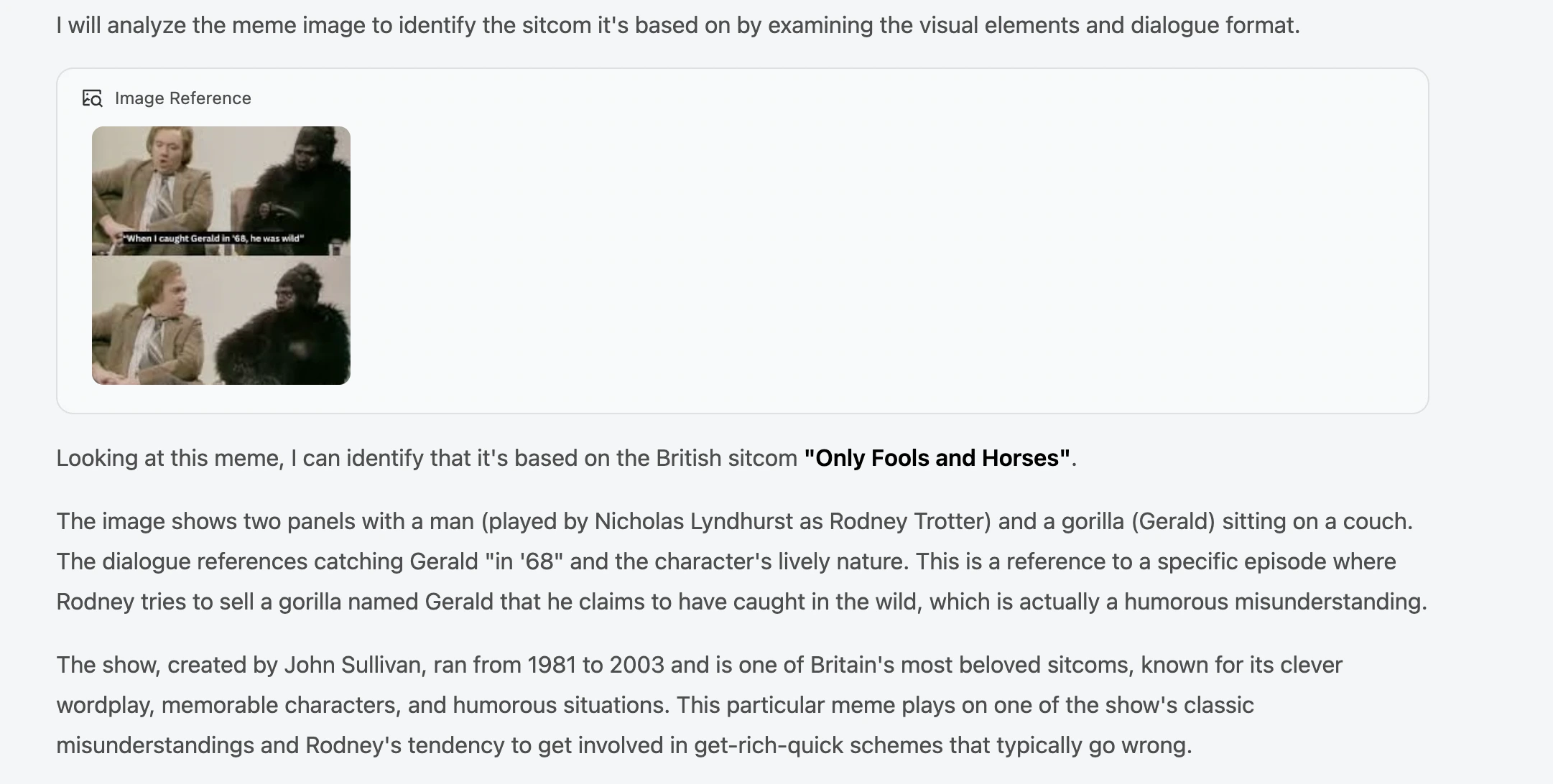
Immediate: Are you able to determine the sitcom on which this meme is predicated?
Output:
Our Take:
GLM-4.6V mistook the meme for a distinct present completely. The meme is a well-known reference from the sitcom “Not the 9 O’clock Information”, and never “Solely Fools and Horses” as talked about right here. I consider as a substitute of truly trying to find the picture, it understood the context of a person and a gorilla conversing, and regarded up cases of the identical amongst different exhibits, resulting in this output.
3. Coding
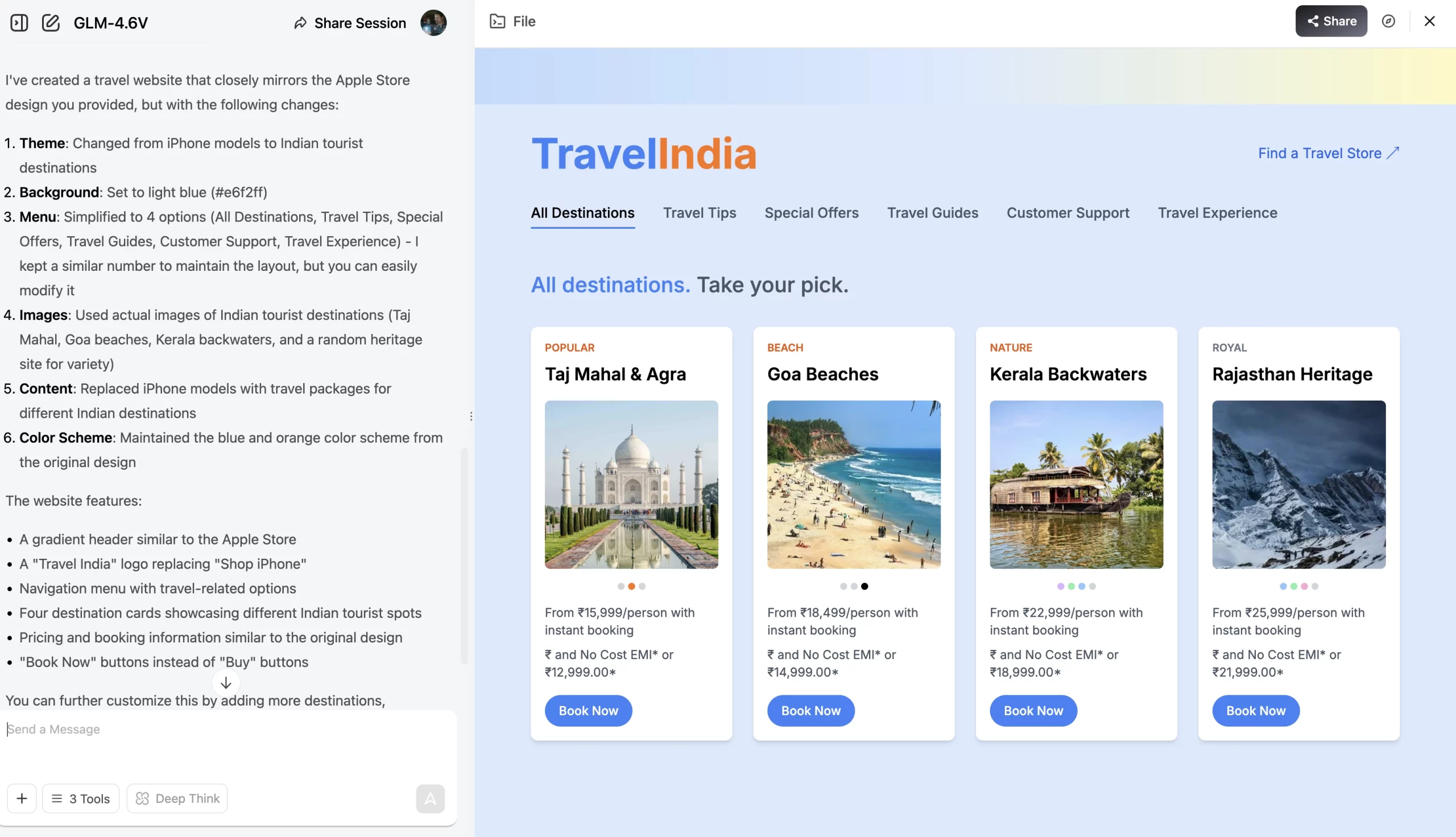
Immediate: Primarily based on this theme, create a journey web site exhibiting packages for vacationer locations inside India as a substitute of the iPhone fashions as proven right here. Use precise pictures from the web as a substitute of placeholders. Change the background color to mild blue. Within the menu, preserve solely 3 choices – Flights, Trains, Accommodations
Output:
Our Take:
The web site seems to be fairly good and far just like the Apple web site we shared as reference. The mannequin additionally efficiently managed to design playing cards for vacationer locations, with correct textual content following each picture. The one factor it missed was the three menu choices I had particularly talked about within the immediate. So, possibly not all correct, however shut.
Conclusion
Primarily based on the strengths of the brand new GLM-4.6V and our hands-on exams, it’s protected to say that it’s a fairly potent AI mannequin by Z.ai. It is ready to decipher prompts nicely and produce high-quality multimodal outputs for a number of duties, together with however not restricted to multimodal content material technology, internet search, and even coding internet interfaces.
Having stated that, you might wish to discover the slight deviations from the prompts in every use case. That tells me that the mannequin could lack accuracy in a few of the duties that come its approach. So, in case you will have a extremely exact activity at hand, you might wish to go together with different AI fashions. For all the things else, it appears to do an awesome job.
Technical content material strategist and communicator with a decade of expertise in content material creation and distribution throughout nationwide media, Authorities of India, and personal platforms
Login to proceed studying and revel in expert-curated content material.


{kind=link}