
 Prompting?")
{kind=link}
The core thought behind Chain of Thought (CoT) is to encourage an AI mannequin to cause step-by-step earlier than producing a solution. Whereas the idea itself shouldn’t be new and is actually a structured approach of asking fashions to elucidate their reasoning, it stays extremely related right this moment. Curiosity in CoT elevated once more after OpenAI launched a preview of its o1 mannequin, which renewed give attention to reasoning-first approaches. On this article, I’ll clarify what CoT is, discover the completely different methods which are publicly out there, and take a look at whether or not these strategies really enhance the efficiency of contemporary AI fashions. Let’s dive in.
The Analysis Behind Chain of Thought Prompting
During the last 2 years, many analysis papers have been printed on this subject. What just lately caught my eye is that this repository that brings collectively key analysis associated to Chain of Thought (CoT).
The completely different step-by-step reasoning methods mentioned in these papers are illustrated within the picture beneath. A big portion of this influential work has come instantly from analysis teams at DeepMind and Princeton.
The thought of COT was first launched by DeepMind in 2022. Since then, newer analysis has explored extra superior methods, reminiscent of combining Tree of Ideas (ToT) with Monte Carlo Search, in addition to utilizing CoT with none preliminary immediate, generally known as zero-shot CoT.
Baseline Rating of LLMs: How Mannequin Efficiency Is Measured
Earlier than we discuss enhancing Giant Language Fashions (LLMs), we first want a method to measure how properly they carry out right this moment. This preliminary measurement is known as the baseline rating. A baseline helps us perceive a mannequin’s present capabilities and offers a reference level for evaluating any enchancment methods, reminiscent of Chain-of-Thought prompting.
LLMs are normally evaluated utilizing standardized benchmarks. Some generally used ones embody:
- MMLU: Assessments language understanding
- BigBench: Evaluates reasoning skills
- HellaSwag: Measures commonsense reasoning
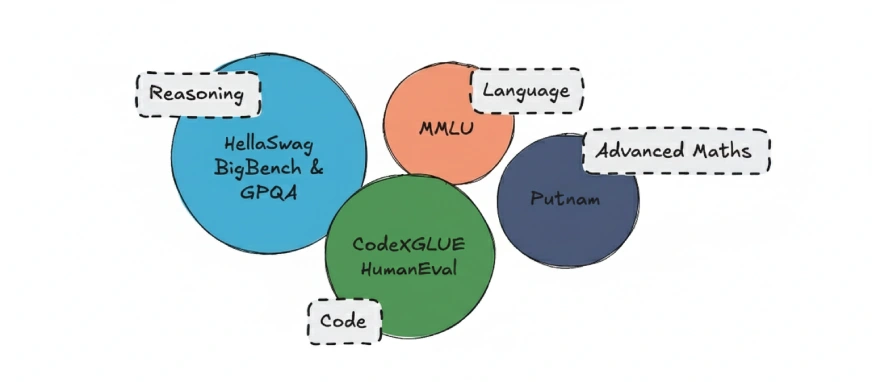
Nevertheless, not all benchmark scores must be taken at face worth. Many well-liked analysis datasets are a number of years previous and will undergo from information contamination, which means fashions might have not directly seen components of the take a look at information throughout coaching. This will inflate reported scores and provides a deceptive image of true mannequin efficiency.
To deal with this, newer analysis efforts have emerged. For instance, Hugging Face launched an up to date LLM leaderboard that depends on more energizing, less-contaminated take a look at units. On these newer benchmarks, most fashions rating noticeably decrease than they did on older datasets, highlighting how delicate evaluations are to benchmark high quality.
For this reason understanding how LLMs are evaluated is simply as vital as trying on the scores themselves. In lots of real-world settings, organizations select to construct personal, inner analysis units tailor-made to their use circumstances, which regularly present a extra dependable and significant baseline than public benchmarks alone.
Additionally Learn: 14 In style LLM Benchmarks to Know in 2026
Excessive-Degree View of Chain of Thought (CoT)
Chain of Thought was launched by the Mind Crew at DeepMind of their 2022 paper Chain of Thought Prompting Elicits Reasoning in Giant Language Fashions.
Whereas the thought of step-by-step reasoning shouldn’t be new, CoT gained renewed consideration after the discharge of OpenAI’s o1 mannequin, which introduced reasoning-first approaches again into focus. The DeepMind paper explored how rigorously designed prompts can encourage massive language fashions to cause extra explicitly earlier than producing a solution.
Chain of Thought is a prompting method that prompts a mannequin’s inherent reasoning potential by encouraging it to interrupt an issue into smaller, logical steps as a substitute of answering instantly. This makes it particularly helpful for duties that require multi-step reasoning, reminiscent of math, logic, and commonsense understanding.
On the time this analysis was launched, most prompting approaches relied primarily on one-shot or few-shot prompting with out explicitly guiding the mannequin’s reasoning course of.
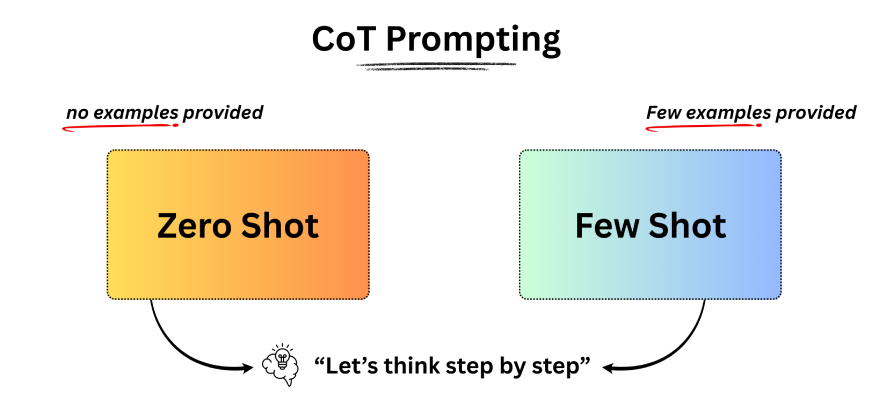
Understanding Zero-Shot Prompting
Zero-shot prompting means asking a mannequin to carry out a job with out offering any examples or prior context. For instance, you open ChatGPT or one other reasoning mannequin and instantly ask a query. The mannequin depends completely on its present data to generate a solution.
On this setup, the immediate doesn’t embody any examples, but the LLM can nonetheless perceive the duty and produce a significant response. This potential displays the mannequin’s zero-shot functionality. A pure query then arises: can we enhance zero-shot efficiency? The reply is sure, by means of a way referred to as instruction tuning. Discover extra abut it right here.
Instruction tuning entails coaching a mannequin not solely on uncooked textual content but additionally on datasets formatted as directions and corresponding responses. This helps the mannequin discover ways to observe directions extra successfully, even for duties it has by no means explicitly seen earlier than. Because of this, instruction-tuned fashions carry out considerably higher in zero-shot settings.
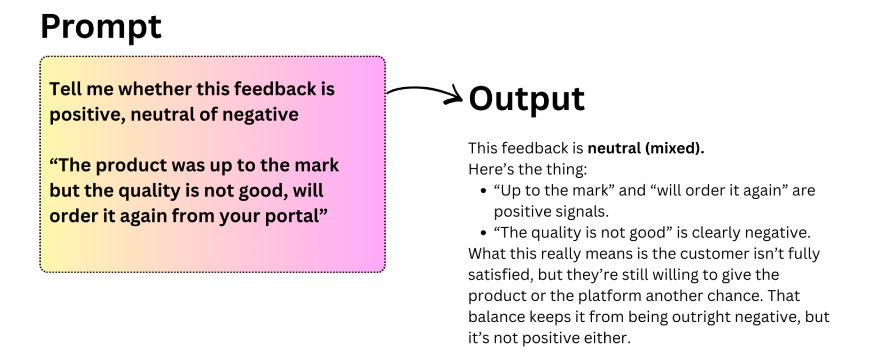
Reinforcement Studying from Human Suggestions (RLHF) additional enhances this course of by aligning mannequin outputs with human preferences. In easy phrases, instruction tuning teaches the mannequin how to reply to directions, whereas RLHF teaches it find out how to reply in methods people discover helpful and applicable.
In style fashions reminiscent of ChatGPT, Claude, Mistral, and Phi-3 use a mix of instruction tuning and RLHF. Nevertheless, there are nonetheless circumstances the place zero-shot prompting might fall quick. In such conditions, offering a number of examples within the immediate, often known as few-shot prompting, can result in higher outcomes.
Additionally Learn: Base LLM vs Instruction-Tuned LLM
Understanding Few-Shot Prompting
Few-shot prompting is beneficial when zero-shot prompting produces inconsistent outcomes. On this strategy, the mannequin is given a small variety of examples throughout the immediate to information its conduct. This permits in-context studying, the place the mannequin infers patterns from examples and applies them to new inputs. Analysis by Kaplan et al. (2020) and Touvron et al. (2023) exhibits that this functionality emerges as fashions scale.
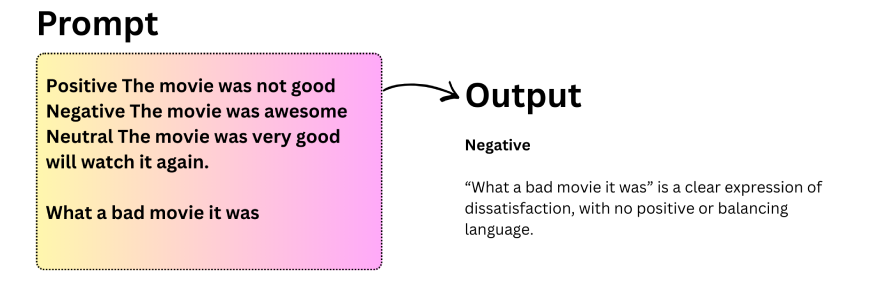
Key observations about few-shot prompting:
- LLMs can generalize properly even when instance labels are randomized.
- Fashions stay sturdy to adjustments or distortions in enter format.
- Few-shot prompting typically improves accuracy in comparison with zero-shot prompting.
- It struggles with duties requiring multi-step reasoning, reminiscent of complicated arithmetic.
When zero-shot and few-shot prompting should not ample, extra superior methods like Chain of Thought prompting are required to deal with deeper reasoning duties.
Understanding Chain of Thought (CoT)
Chain of Thought (CoT) prompting allows complicated reasoning by encouraging a mannequin to generate intermediate reasoning steps earlier than arriving at a ultimate reply. By breaking issues into smaller, logical steps, CoT helps LLMs deal with duties that require multi-step reasoning. It may also be mixed with few-shot prompting for even higher efficiency.
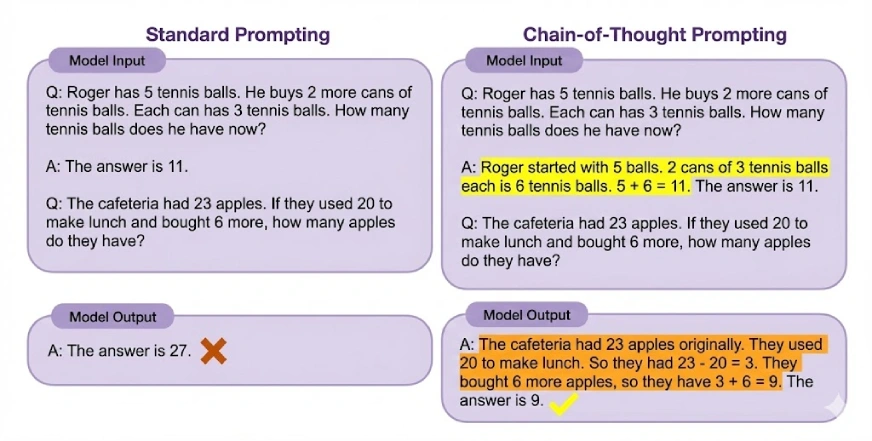
Let’s experiment with Chain of Thought prompting:
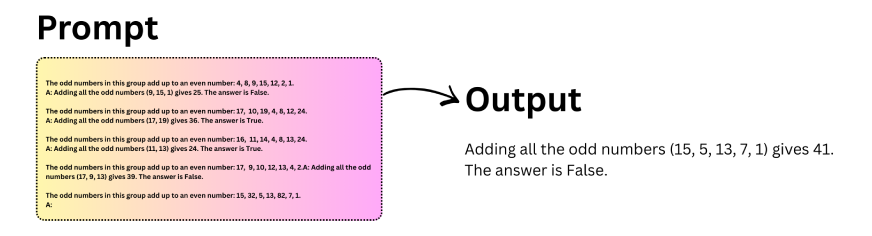
A extensively used variant of this strategy is zero-shot Chain of Thought. As an alternative of offering examples, you merely add a brief instruction reminiscent of “Let’s suppose step-by-step” to the immediate. This small change is usually sufficient to set off structured reasoning within the mannequin.
Let’s perceive this with the assistance of an instance:
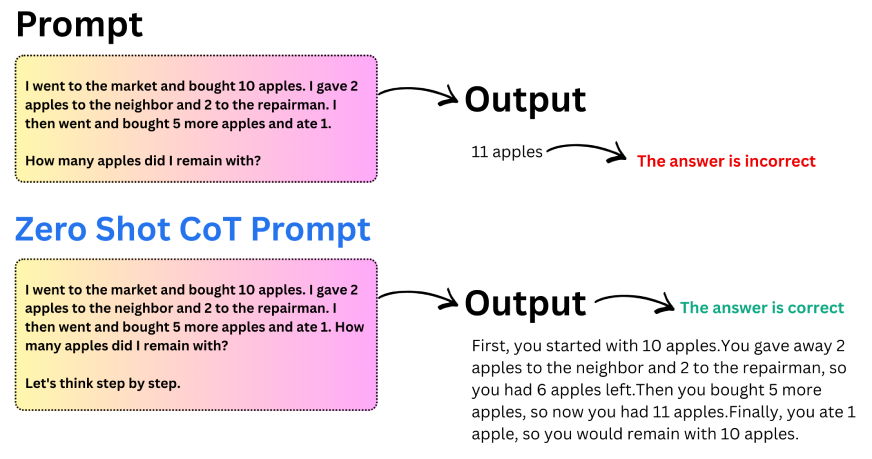
Key takeaways from Zero-Shot CoT:
- Including a single reasoning instruction can considerably enhance accuracy.
- Fashions produce extra structured and logical solutions.
- Zero-shot CoT is beneficial when examples are unavailable.
- It really works particularly properly for arithmetic and logical reasoning duties.
This easy but highly effective method demonstrates how minor adjustments in prompting can result in significant enhancements in mannequin reasoning.
Computerized Chain-of-Thought (Auto-CoT)
Commonplace Chain-of-Thought prompting requires people to manually create reasoning examples, which is time-consuming and liable to errors. Earlier makes an attempt to automate this course of typically struggled with noisy or incorrect reasoning. Auto-CoT addresses this drawback by emphasizing variety within the reasoning examples it generates, lowering the affect of particular person errors.
nstead of counting on rigorously written prompts, Auto-CoT robotically selects consultant questions from a dataset and generates reasoning chains for them. This makes the strategy extra scalable and fewer depending on human effort.
Auto-CoT works in two levels:
- Stage 1 – Clustering: Questions from the dataset are grouped into clusters based mostly on similarity. This ensures protection throughout several types of issues.
- Stage 2 – Sampling: One consultant query is chosen from every cluster, and a reasoning chain is generated for it. Easy heuristics, reminiscent of preferring shorter questions, are used to keep up reasoning high quality.
By specializing in variety and automation, Auto-CoT allows scalable Chain-of-Thought prompting with out the necessity for manually crafted examples.
Additionally Learn: 17 Prompting Methods to Supercharge Your LLMs
Conclusion
Chain-of-Thought prompting adjustments how we work with massive language fashions by encouraging step-by-step reasoning as a substitute of one-shot solutions. That is vital as a result of even sturdy LLMs typically wrestle with duties that require multi-step reasoning, regardless of having the mandatory data.
By making the reasoning course of specific, Chain-of-Thought persistently improves efficiency on duties like math, logic, and commonsense reasoning. Computerized Chain-of-Thought builds on this by lowering handbook effort, making structured reasoning simpler to scale.
The important thing takeaway is straightforward: higher reasoning doesn’t at all times require bigger fashions or retraining. Usually, it comes down to higher prompting. Chain-of-Thought stays a sensible and efficient approach to enhance reliability in fashionable LLMs.
Often Requested Questions
A. Chain of Thought prompting is a way the place you ask an AI mannequin to elucidate its reasoning step-by-step earlier than giving the ultimate reply. This helps the mannequin break complicated issues into smaller, logical steps.
A. In TCS-style solutions, Chain of Thought prompting means writing clear intermediate steps to point out how an answer is reached. It focuses on logical reasoning, structured rationalization, and readability reasonably than leaping on to the ultimate reply.
A. Chain of Thought prompting is efficient as a result of it guides the mannequin to cause step-by-step. This reduces errors, improves accuracy on complicated duties, and helps the mannequin deal with math, logic, and multi-step reasoning issues higher.
A. Chain of Thought exhibits reasoning steps inside a single response, whereas immediate chaining splits a job into a number of prompts. CoT focuses on inner reasoning, whereas immediate chaining manages workflows throughout a number of mannequin calls.
A. The important thing steps in Chain of Thought embody understanding the issue, breaking it into smaller components, reasoning by means of every step logically, after which combining these steps to succeed in a ultimate, well-justified reply.
A. Utilizing CoT improves reasoning accuracy, reduces logical errors, and makes AI responses extra clear. It really works particularly properly for complicated duties like arithmetic, logical puzzles, and decision-making issues that require a number of reasoning steps.
Development Hacker | Generative AI | LLMs | RAGs | FineTuning | 62K+ Followers https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/
Login to proceed studying and revel in expert-curated content material.