
?")
{kind=link}
Giant language fashions are nice. All of us can comply with that. They’ve been a cornerstone of recent business and are more and more impacting increasingly more domains.
With fixed upgrades and enhancements to the structure and capabilities of language fashions, one would possibly assume – That’s it! Alas… A latest improvement underneath the title of RLM or Recursive language fashions, have taken the centerstage now.
What’s it? How does it relate to LLMs? And the way does it push the frontier of AI? We’ll discover out on this article which dissects this newest expertise in an accessible method. Let’s start by going over the problems that plague present LLMs.
A Elementary Downside
LLMs have an architectural restrict. It’s known as Token Window. That is the utmost variety of tokens the mannequin can bodily learn in a single ahead cross, decided by the transformer’s positional embeddings + reminiscence. If the enter is longer than this restrict, the mannequin can’t course of it. It’s like making an attempt to load a 5GB file right into a 500MB RAM program. It results in an overflow! Listed here are the token home windows of among the fashionable fashions:
| Mannequin | Max Token Window |
| Google Gemini (newest) | 1,000,000 |
| OpenAI GPT-5 (newest) | 400,000 |
| Anthropic Claude (newest) | 200,000 |
Often, the larger the quantity, the higher the mannequin… Or is it?
Context Rot: The Hidden Failure Earlier than the Restrict
Right here’s the catch. Even when a immediate matches contained in the token window, mannequin high quality quietly degrades because the enter grows longer. Consideration turns into diffuse, earlier info loses affect, and the mannequin begins lacking connections throughout distant elements of the textual content. This phenomenon is named context rot.
So though a mannequin could technically settle for 1 million tokens, it typically can’t purpose reliably throughout all of them. In apply, efficiency collapses lengthy earlier than the token window is reached.
Context Window
Context window is how a lot info the mannequin can truly use properly earlier than efficiency collapses. This quantity modifications primarily based on the complexity of the immediate and the kind of knowledge that’s processed. The efficient context window of an LLM is far smaller than the token window. And in contrast to the token window, which is kind of particular, the context window modifications with the complexity of the immediate. That is demonstrated by poor efficiency of huge token window LLMs in reasoning duties, because it requires retaining virtually all the info being fed concurrently.
This can be a drawback. Lengthy context home windows and consequently token home windows are fascinating, however lack of context (as a consequence of their size) is unavoidable…or at the least it was.
Recursive Language Fashions: To the rescue
Regardless of the title, RLMs aren’t a brand new mannequin class like LLM, VLM, SLM and many others. As an alternative it’s an inference technique. An answer to the issue of context rot in lengthy prompts. RLMs deal with lengthy prompts as a part of an exterior surroundings and permits the LLM to programmatically look at, decompose, and recursively name itself over snippets of the immediate.
This successfully makes the context window a number of occasions larger than standard. It does so similarly:
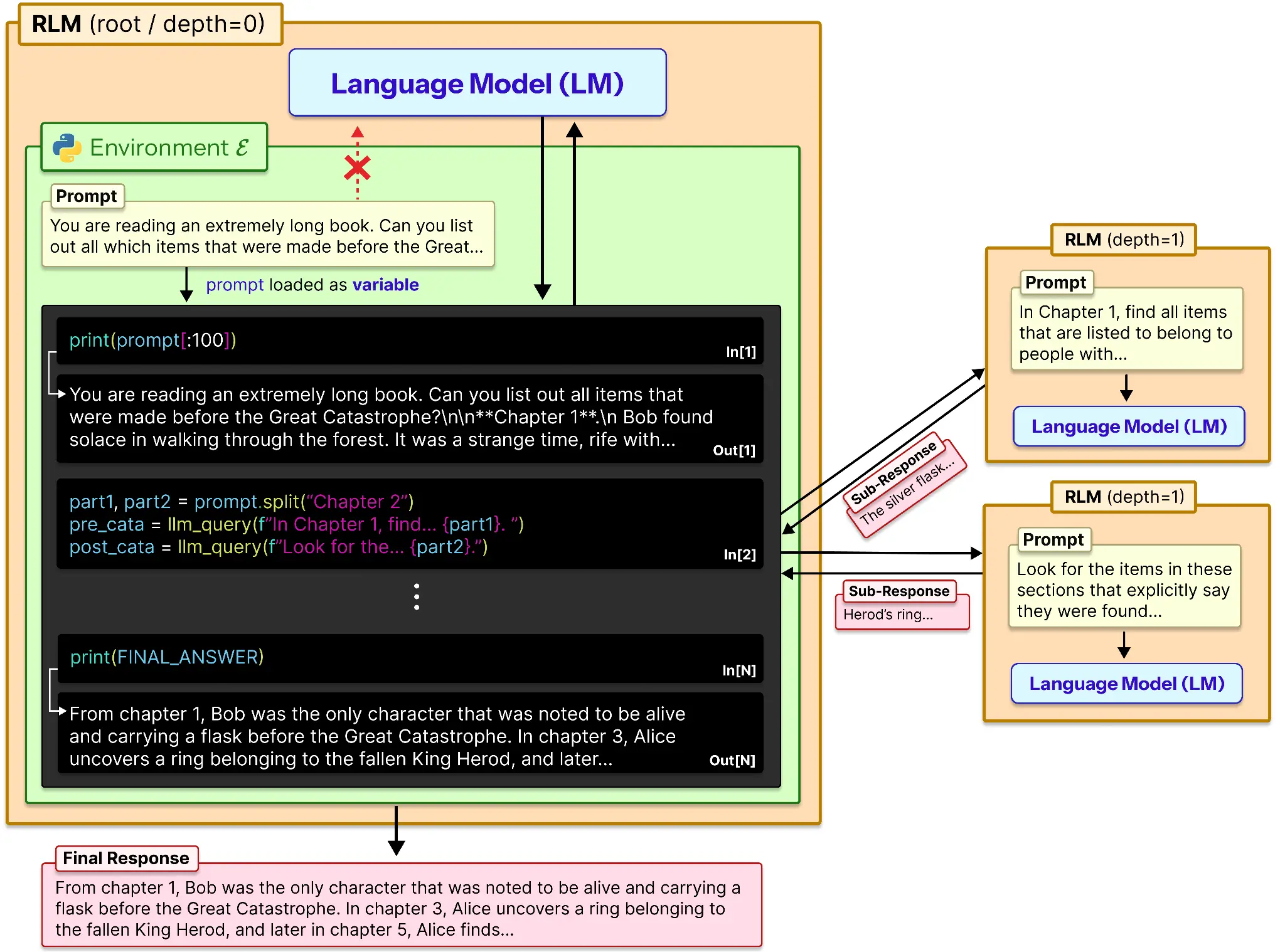
Conceptually, RLM provides an LLM exterior reminiscence and a option to function on it. Right here is the way it works:
- The immediate will get loaded in a variable.
- This variable is spliced relying upon the reminiscence or a hard-coded quantity.
- That knowledge will get despatched to the LLM and its output is saved for reference.
- Equally all of the chunks of the immediate are processed individually and their outputs are recorded.
- This record of outputs is used to provide the ultimate response of the mannequin.
A sub-model like o3-mini or another mannequin which is useful, may very well be used for serving to the mannequin to summarize or reason-locally in a sub-prompt.
Isn’t this…Chunking?
At first look, this would possibly seem like glorified chunking. But it surely’s basically completely different. Conventional chunking forces the mannequin to neglect earlier items because it strikes ahead. RLM retains all the pieces alive exterior the mannequin and lets the LLM selectively revisit any half at any time when wanted. It’s not summarizing reminiscence — it’s navigating it.
What Issues RLM Lastly Solves
RLM unlocks issues regular LLMs persistently fail at:
- Reasoning over huge knowledge: As an alternative of forgetting earlier elements, the mannequin can revisit any part of giant inputs.
- Multi-document synthesis: It pulls proof from scattered sources with out hitting context limits.
- Data-dense duties: Works even when solutions depend upon almost each line of the enter.
- Lengthy structured outputs: Builds outcomes exterior the token window and stitches them collectively cleanly.
Briefly: RLM lets LLMs deal with scale, density, and construction that break conventional prompting.
The Tradeoffs
With all that RLM solves, there are just a few downsides to it as properly:
| Limitation | Impression |
| Immediate mismatch throughout fashions | Identical RLM immediate results in unstable conduct and extreme recursive calls |
| Requires sturdy coding means | Weaker fashions fail to govern context reliably within the REPL |
| Output token exhaustion | Lengthy reasoning chains exceed output limits and truncate trajectories |
| No async sub-calls | Sequential recursion considerably will increase latency |
Briefly: RLM trades uncooked velocity and stability for scale and depth.
Conclusion
Scaling LLMs used to imply extra parameters and bigger token home windows. RLM introduces a 3rd axis: inference construction. As an alternative of constructing larger brains, we’re educating fashions easy methods to use reminiscence exterior their brains — identical to people do.
It’s a holistic view. It isn’t extra of what was earlier than like standard. Somewhat a brand new tackle the standard approaches of mannequin operation.
Ceaselessly Requested Questions
A. They overcome token window limits and context rot, permitting LLMs to purpose reliably over extraordinarily lengthy and information-dense prompts.
A. No. RLMs are an inference technique that lets LLMs work together with lengthy prompts externally and recursively question smaller chunks.
A. Conventional chunking forgets earlier elements. RLM retains the complete immediate exterior the mannequin and revisits any part when wanted.
I concentrate on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, knowledge evaluation, and data retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and revel in expert-curated content material.