

{kind=link}
Embedding mannequin inference usually struggles with effectivity when serving massive volumes of brief requests—a typical sample in search, retrieval, and advice programs. At Voyage AI by MongoDB, we name these brief requests queries, and different requests are referred to as paperwork. Queries sometimes should be served with very low latency (sometimes 100–300 ms).
Queries are sometimes brief, and their token-length distribution is very skewed. Because of this, question inference tends to be memory-bound quite than compute-bound. Question visitors is fairly spiky, so autoscaling is simply too gradual. In sum, serving many brief requests sequentially is very inefficient.
On this weblog submit, we discover how batching can be utilized to serve queries extra effectively. We first focus on padding elimination in fashionable inference engines, a key approach that permits efficient batching. We then current sensible methods for forming batches and deciding on an acceptable batch measurement. Lastly, we stroll by the implementation particulars and share the ensuing efficiency enhancements: a 50% discount in GPU inference latency—regardless of utilizing 3X fewer GPUs.
Padding elimination makes efficient batching potential
Given the patterns of question visitors, one easy thought is: can we batch them to enhance inference effectivity? Padding elimination, supported in inference engines like vLLM and SGLang, makes environment friendly batching potential.
Most inference engines settle for requests within the kind (B, S), the place B is the sequence quantity within the batch, and S is the utmost sequence size. Sequences needs to be padded to the max sequence size in order that tensors line up. However that comfort comes at a price: padding tokens do no helpful work however nonetheless devour compute and reminiscence bandwidth, so latency scales with B × S as an alternative of the particular token rely. With serving massive volumes of brief requests, this wastes a big share of compute and may inflate tail latency.Padding elimination and variable-length processing repair this by concatenating all energetic sequences into one lengthy “tremendous sequence” of size T = Σtoken_count_i, the place token_count_i is the token rely in sequence i. Inference engines like vLLM and SGLang can course of this mixed sequence. Consideration masks and place indices be certain that every sequence solely attends to its personal tokens. Because of this, inference time now tracks T quite than B × S, aligning GPU work with what issues.
Proposal: token-count-based batching
In Voyage AI, we proposed and constructed token-count-based batching, batching queries (brief requests) by complete token rely within the batch (Σtoken_count_i), quite than by complete request rely or arbitrary time home windows.
Time-window batching is inefficient when serving many brief requests. Time-window batching swings between under- and over-filled batches relying on visitors. A brief window retains latency low however produces small, under-filled batches; an extended window improves utilization however provides queueing delay. Site visitors is bursty, so a single window measurement oscillates between under- and over-filling. Time-window batching introduces variability in useful resource utilization, inflicting the system to shift between memory-bound and compute-bound operations. Request-count batching has comparable issues.
Token-count batching aligns the batch measurement (complete token rely within the batch) with the precise compute required. When many queries arrive shut collectively, we group them by token counts so the GPU processes a bigger mixed workload in a single ahead cross. Based mostly on our experiment, token-count-based batching amortizes mounted prices, reduces per-request latency and price, and will increase throughput and mannequin flops utilization (MFU).
What’s the optimum batch measurement?
Our inference-latency-vs-token-count profiling of question inference exhibits a transparent sample: latency is roughly flat as much as a threshold (saturation level) after which turns into roughly linear. For small requests, mounted per-request overheads (like GPU scheduling, reminiscence motion, pooling and normalization, and so on.) dominate, and latency stays almost fixed; past that time, latency scales with token rely. The brink (saturation level) depends upon components just like the mannequin structure, inference engines, and GPU. For our voyage-3 mannequin operating on A100, the brink is about 600 tokens.
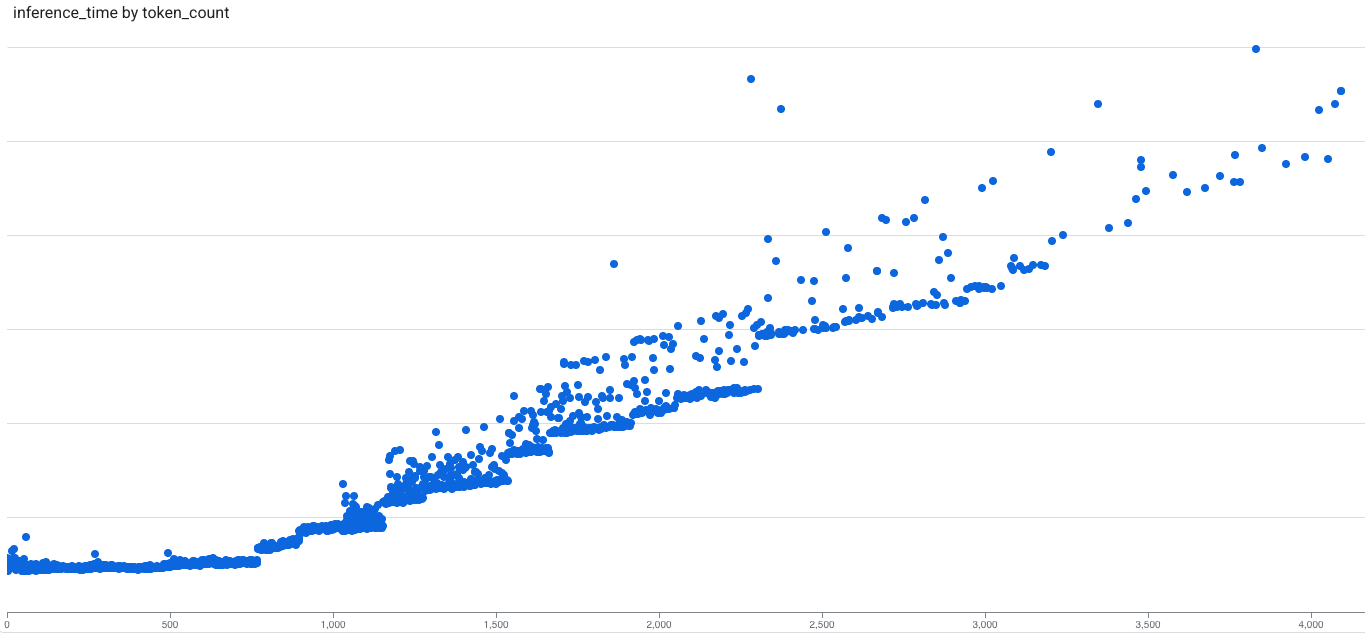
Based mostly on the info of inference latency vs token rely, we are able to analyze FLOPs Utilization (MFU) vs. token rely and throughput vs. token rely, that are proven within the following graph. We observe that Mannequin FLOPs Utilization (MFU) and throughput scale roughly linearly with token rely till reaching a saturation level. Most of our queries inferences are within the memory-bound zone, distant from the saturation level.
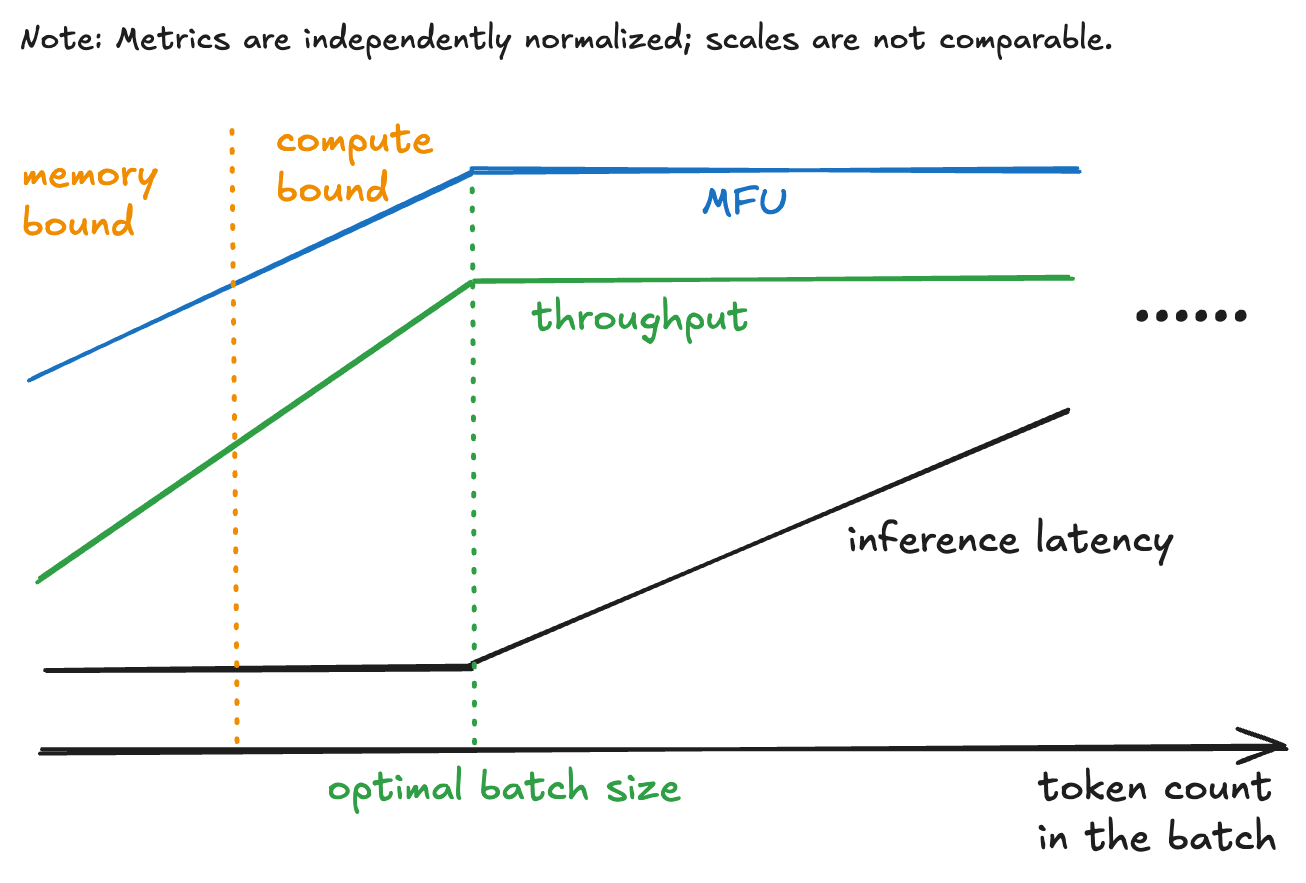
Batching brief requests can transfer the inference from memory-bound to compute-bound. If we select the saturation level in Determine 3 because the batch measurement (complete token rely within the batch), the latency and throughput/MFU may be balanced and optimized.
Queue design: enabling token-count-based batching
Token-count–based mostly batching wants an information system that does greater than easy FIFO supply. The system has to connect an estimated token_count to every request, peek throughout pending requests, after which atomically declare a subset whose complete tokens match the optimum batch measurement (Σtoken_count_i ≤ optimal_batch_size). With out these primitives, we both underfill the GPU—losing mounted overheads—or overfill it and spike tail latency.
Normal-purpose brokers like RabbitMQ and Kafka are wonderful at sturdiness, fan-out, and supply, however their batching knobs are message rely/bytes, not tokens. RabbitMQ’s prefetch is request-count-based, and messages are pushed to shoppers, so there’s no environment friendly technique to peek and batch requests by Σtoken_count_i. Kafka batches by bytes/messages inside a partition; token rely varies with textual content and tokenizer, so there isn’t any environment friendly technique to batch requests by Σtoken_count_i.
So there are two sensible paths to make token-count-based batching work. One is to put a light-weight aggregator in entrance of Kafka/RabbitMQ that consumes batches by token counts after which dispatches batches to mannequin servers. The opposite is to make use of a retailer that naturally helps quick peek + conditional batching—for instance, Redis with Lua script. In our implementation, we use Redis as a result of it lets us atomically “pop as much as the optimum batch measurement” and set per-item TTLs inside a single lua script name. No matter we select, the important requirement is similar: the queue should let our system see a number of pending gadgets, batch by Σtoken_count_i, and declare them atomically to maintain utilization steady and latency predictable.
Our system enqueues every embedding question request right into a Redis checklist as:
Mannequin servers name lua script atomically to fetch a batch of requests till the optimum batch measurement is reached. The likelihood of Redis dropping information could be very low. Within the uncommon case that it does occur, customers might obtain 503 Service Unavailable errors and may merely retry. When QPS is low, batches are solely partially stuffed and GPU utilization stays low, however latency nonetheless improves.

Outcomes
We ran a manufacturing experiment on the Voyage-3-Massive mannequin serving, evaluating our new pipeline (question batching + vLLM) in opposition to our previous pipeline (no batching + Hugging Face Inference). We noticed a 50% discount in GPU inference latency—regardless of utilizing 3X fewer GPUs.
We regularly onboarded 7+ fashions to the above question batching resolution, and noticed the next outcomes (be aware that these outcomes are based mostly on our particular implementations of the “new” and “previous” pipelines, and will not be essentially generalizable):
-
vLLM reduces GPU inference time by as much as ~20 ms for many of our fashions.
-
GPU utilization and MFU improve, reflecting diminished padding, higher amortization of per-batch overhead, and inference transferring nearer to the compute-bound regime.
-
Throughput improves by as much as 8× by way of token-count–based mostly batching.
-
Some mannequin servers see P90 end-to-end latency drop by 60+ ms as queuing time is diminished below useful resource rivalry.
-
P90 end-to-end latency is extra steady throughout visitors spikes, even with fewer GPUs.
In abstract, combining padding removals with token-count-based batching improves throughput and reduces latency, whereas enhancing useful resource utilization and decreasing operational prices throughout brief question embedding inference.
Subsequent Steps
To study extra about how Voyage AI’s state-of-the-art embedding fashions and rerankers may help you construct correct, dependable semantic search and AI purposes, see the Voyage AI by MongoDB web page.
Many due to Tengyu Ma, Andrew Whitaker, Ken Hong, Angel Lim, and Andrew Gaut for a lot of useful discussions alongside the best way, and to Akshat Vig, Murat Demirbas, and Stan Halka for considerate evaluations and suggestions.