

Unveiling the Limits: A Efficiency Evaluation of MongoDB Sharded Clusters with plgm
In any database atmosphere, assumptions are the enemy of stability. Understanding the purpose at which a system transitions from environment friendly to saturated is crucial for sustaining uptime and guaranteeing a constant and dependable person expertise. Figuring out these limits requires greater than estimation—it calls for rigorous, reproducible, and scalable load testing below reasonable circumstances.
To assist this effort, we launched you to plgm: Percona Load Generator for MongoDB Clusters.
PLGM is a high-performance benchmarking software written in Go and designed to simulate reasonable workloads towards MongoDB clusters. Its capability to simply accept the identical assortment constructions and question definitions used within the utility you need to take a look at, generate complicated BSON knowledge fashions, assist excessive ranges of concurrency, and supply detailed real-time telemetry makes it a super answer for the sort of evaluation
This text builds straight upon our preliminary weblog introducing PLGM, Introducing Percona Load Generator for MongoDB Clusters: The Benchmark Device That Simulates Your Precise Software.
As detailed in that put up, PLGM was created to handle the restrictions of recognized artificial benchmarking instruments like YCSB, sysbench, pocdriver, mgodatagen and others. Whereas these instruments are wonderful for measuring uncooked {hardware} throughput, they typically fail to foretell how a database will deal with particular, complicated and customized utility logic. PLGM differentiates itself by specializing in realism: it makes use of “configuration as code” to reflect your precise doc constructions and question patterns, guaranteeing that the benchmark site visitors is indistinguishable from actual person exercise. Please learn our weblog put up above for extra info and full comparability.
Utilizing PLGM, we executed a structured sequence of workloads to establish optimum concurrency thresholds, most throughput capability, and potential {hardware} saturation factors inside the cluster. The evaluation consists of a number of workload situations, together with a read-only baseline and a number of other variations of blended and read-only workload simulations.
In the end, these checks reinforce an vital actuality: efficiency will not be a hard and fast worth. It’s a shifting goal that relies upon fully on workload traits, system structure, and the way the atmosphere is configured and optimized.
Take a look at Surroundings Structure
The atmosphere we used for this take a look at consists of the next structure (all nodes have the identical {hardware} specs):
- Nodes: 4 vCPUs, 8 GB RAM
- Surroundings: Digital machines
- Topology: 1 Load Generator (working plgm), 2 Mongos Routers, 1 Sharded Reproduction Set.
- Storage: 40GB Digital Disk
Take a look at Workload
Percona Load Generator for MongoDB Clusters comes pre-configured with a pattern database, assortment, and workload, permitting you to begin benchmarking your atmosphere instantly while not having to design a workload from scratch.
That is notably helpful for rapidly understanding how PLGM operates and evaluating its conduct in your atmosphere. After all, you’ve gotten full flexibility to customise the workload to fit your particular wants, as detailed in our documentation.
The default workload used on this weblog put up is to showcase how PLGM works, highlighting its performance and advantages. The default workload has the next traits:
- Namespace: airline.flights
- Staff: 4
- Length: 10s
- Indexes: 4
- Sharded (in case you are working towards a sharded cluster)
- Question Distribution:
- Choose (54%)
- Replace (21%)
- Insert (5%)
- Delete (10%)
- Agg (5%)
- Approximate assortment measurement with the above settings
- Paperwork: 14600
- Dimension: 24MB
Observe on assortment measurement and doc rely:
The default workload performs solely 5% of its operations as inserts. To generate a bigger variety of paperwork, merely regulate the question distribution ratio, batch measurement and concurrency. You’ve gotten full management over the variety of paperwork and the dimensions of the database. For instance, you may set PLGM_INSERT_PERCENT=100 to carry out 100% inserts and PLGM_INSERT_BATCH_SIZE to extend the variety of paperwork per batch, this may after all improve the doc rely and assortment measurement accordingly.
Surroundings variables set for the take a look at workload proven under
- PLGM_PASSWORD
- PLGM_URI
- PLGM_REPLICASET_NAME
As soon as the above env vars have been set, all you want to do is run the applying:
|
./plgm_linux config_plgm.yaml |
Pattern Output:
Assortment stats:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[direct: mongos] airline> printjson(statsPick(“flights”)); { sharded: true, measurement: 28088508, rely: 14591, numOrphanDocs: 0, storageSize: 15900672, totalIndexSize: 4943872, totalSize: 20844544, indexSizes: { _id_: 659456, flight_id_hashed: 921600, ‘flight_id_1_equipment.plane_type_1’: 1163264, seats_available_1_flight_id_1: 712704, duration_minutes_1_seats_available_1_flight_id_1: 978944, ‘gear.plane_type_1’: 507904 }, avgObjSize: 1925, ns: ‘airline.flights’, nindexes: 6, scaleFactor: 1 } |
Pattern doc construction:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
[direct: mongos] airline> db.flights.findOne() { _id: ObjectId(‘695eca4be9d9322e2aae97eb’), duration_minutes: 841436202, flight_id: 1491473635, origin: ‘Greensboro’, gate: ‘F20’, seats_available: 2, passengers: [ { seat_number: ‘5E’, passenger_id: 1, name: ‘Janet Miller’, ticket_number: ‘TCK-15920051’ }, { name: ‘Keagan Reynolds’, ticket_number: ‘TCK-71064717’, seat_number: ‘8A’, passenger_id: 2 }, ... ommitted remaining passenger list for brevity .... ], agent_first_name: ‘Earnest’, agent_last_name: ‘Thompson’, flight_date: ISODate(‘2025-03-24T15:04:11.182Z’), vacation spot: ‘Chicago’, flight_code: ‘NM855’, gear: { plane_type: ‘Boeing 777’, total_seats: 43, facilities: [ ‘Priority boarding’, ‘Extra legroom’, ‘Power outlets’, ‘WiFi’, ‘Hot meals’ ] } } |
Benchmarks
Now that you’re conversant in use the applying, we are able to proceed with the benchmarks. I’ve run six completely different workloads (detailed under) and supplied an general evaluation demonstrating the advantages of utilizing Percona Load Generator for MongoDB to check your cluster.
Workload #1
We started with a read-only workload to determine the theoretical most throughput of the cluster. We configured plgm to execute 100% discover() operations focusing on a particular shard key, guaranteeing environment friendly, index-optimized queries (this was outlined in our customized queries.json file, you may see the readme for additional particulars).
|
for x in 4 8 16 32 48 64 80 96 128; do PLGM_PASSWORD=**** PLGM_CONCURRENCY=${x} PLGM_QUERIES_PATH=queries.json PLGM_FIND_PERCENT=100 PLGM_REPLICASET_NAME=“” PLGM_URI=“mongodb://dan-ps-lab-mongos00.tp.int.percona.com:27017,dan-ps-lab-mongos01.tp.int.percona.com:27017” ./plgm_linux config_plgm.yaml ; sleep 15; finished |
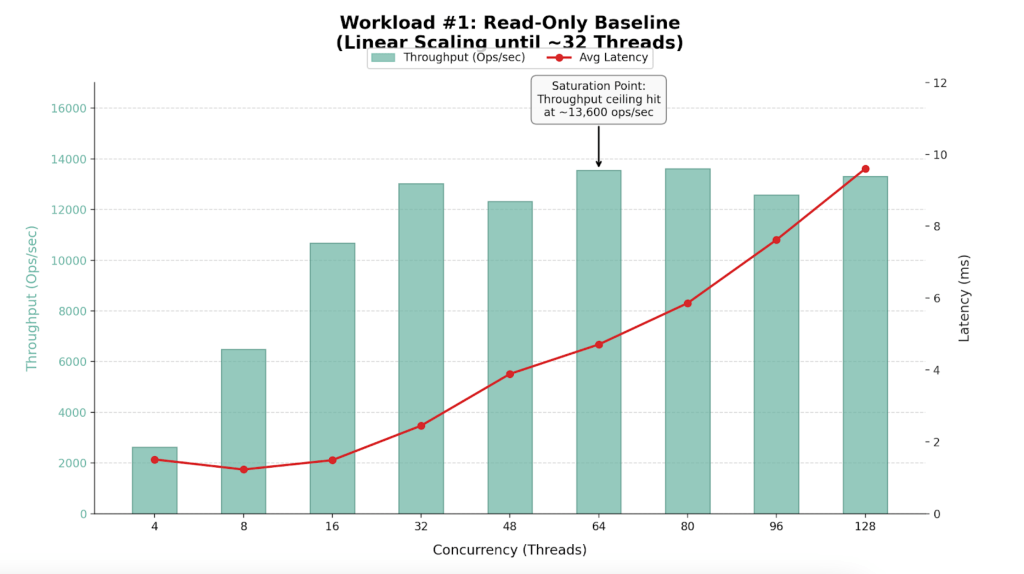
Efficiency Outcomes
| Staff (Threads) | Throughput (Ops/Sec) | Avg Latency (ms) | Effectivity Verdict |
| 4 | 2,635 | 1.51 | Underutilized |
| 8 | 6,493 | 1.23 | Environment friendly Scaling |
| 16 | 10,678 | 1.49 | Environment friendly Scaling |
| 32 | 13,018 | 2.45 | Candy Spot |
| 48 | 12,322 | 3.89 | Saturation Begins |
| 64 | 13,548 | 4.71 | Max Throughput |
| 80 | 13,610 | 5.86 | Excessive Latency / No Acquire |
| 96 | 12,573 | 7.62 | Degraded Efficiency |
| 128 | 13,309 | 9.60 | Oversaturated |
Findings
- The cluster performs greatest with 32 to 64 concurrent employees.
- The cluster hits a “efficiency wall” at roughly 13,600 Ops/Sec.
- Latency stays wonderful (<5ms) as much as 64 threads however degrades considerably (spiking to >200ms) at 96+ threads with out yielding further throughput.
- The ceiling at ~13.5k ops/sec suggests a CPU bottleneck on the only node
Evaluation
- Linear Scaling (4-32 Threads): The cluster demonstrates near-perfect scalability. The {hardware} handles requests virtually immediately.
- Saturation (48-64 Threads): Shifting from 32 to 64 threads will increase throughput by solely ~4%, however latency doubles. The CPU is reaching capability.
- Degradation (80+ Threads): That is traditional “Useful resource Rivalry.” Requests spend extra time ready within the CPU queue than executing.
Workload #2
Following our baseline situation, we performed a blended workload take a look at (54% Reads, 46% Writes), utilizing the identical question definitions as the primary workload.
|
for x in 4 8 16 32 48 64 80 96 128; do PLGM_PASSWORD=**** PLGM_CONCURRENCY=${x} PLGM_QUERIES_PATH=queries.json PLGM_REPLICASET_NAME=“” PLGM_URI=“mongodb://dan-ps-lab-mongos00.tp.int.percona.com:27017,dan-ps-lab-mongos01.tp.int.percona.com:27017” ./plgm_linux config_plgm.yaml ; sleep 15; finished |
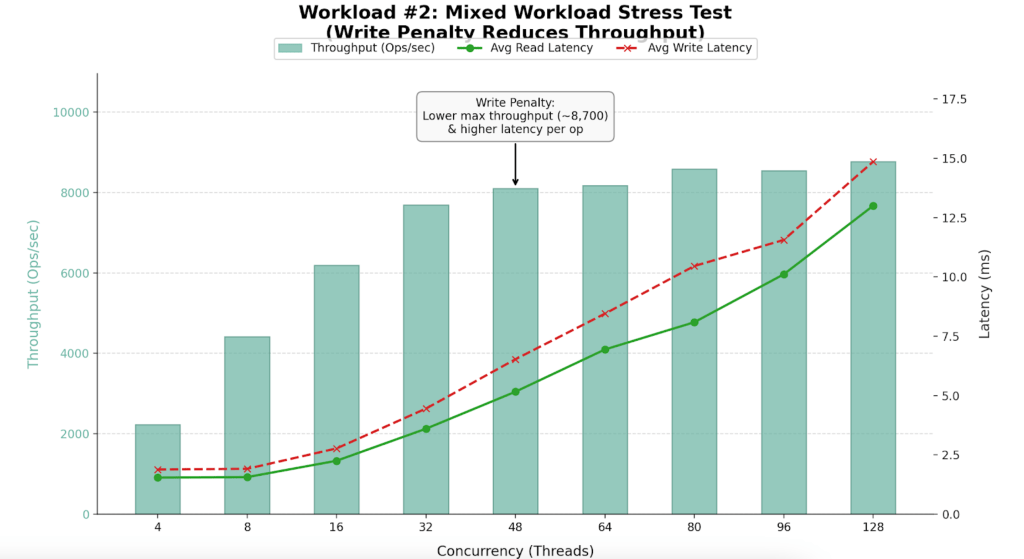
Efficiency Outcomes
| Staff (Threads) | Throughput (Ops/Sec) | Avg Learn Latency (ms) | Avg Write Latency (ms) | Effectivity Verdict |
| 4 | 2,225 | 1.54 | 1.88 | Underutilized |
| 16 | 6,195 | 2.25 | 2.77 | Excessive Effectivity |
| 32 | 7,689 | 3.60 | 4.45 | Candy Spot |
| 48 | 8,096 | 5.16 | 6.53 | Saturation Begins |
| 64 | 8,174 | 6.94 | 8.45 | Max Stability |
| 96 | 8,545 | 10.11 | 11.56 | Diminishing Returns |
| 128 | 8,767 | 13.00 | 14.86 | Oversaturated |
{kind=link}
Findings
- Most sustained throughput dropped to ~8,700 Ops/Sec.
- Introducing 46% writes lowered capability by ~35% in comparison with the read-only benchmark.
- Efficiency peaks between 32 and 64 threads.
Evaluation
- Throughput drops from 13.5k to eight.7k because of the overhead of locking, Oplog replication, and journaling required for writes.
- The Saturation Level: As much as 32 threads, throughput scales linearly. Past 64 threads, including employees yields virtually no additional throughput however causes latency to spike to 13-15ms.
Workload #3
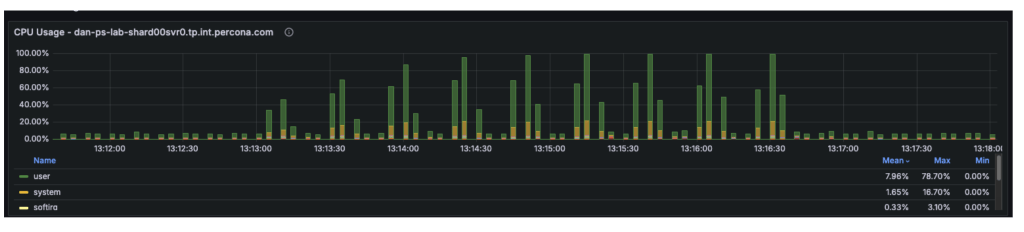
The third workload was executed utilizing a special workload definition (the default), in distinction to the earlier two checks that used queries.json. This workload was additionally a blended workload take a look at (54% reads and 46% writes). We performed an evaluation to establish the purpose at which {hardware} limitations started introducing scalability constraints within the system. By correlating plgm’s granular throughput knowledge with system telemetry, we have been capable of pinpoint the particular useful resource bottleneck liable for the efficiency plateau.
|
for x in 4 8 16 32 48 64 80 96 128; do PLGM_PASSWORD=**** PLGM_CONCURRENCY=${x} PLGM_REPLICASET_NAME=“” PLGM_URI=“mongodb://dan-ps-lab-mongos00.tp.int.percona.com:27017,dan-ps-lab-mongos01.tp.int.percona.com:27017” ./plgm_linux config_plgm.yaml ; sleep 15; finished |
Efficiency Outcomes
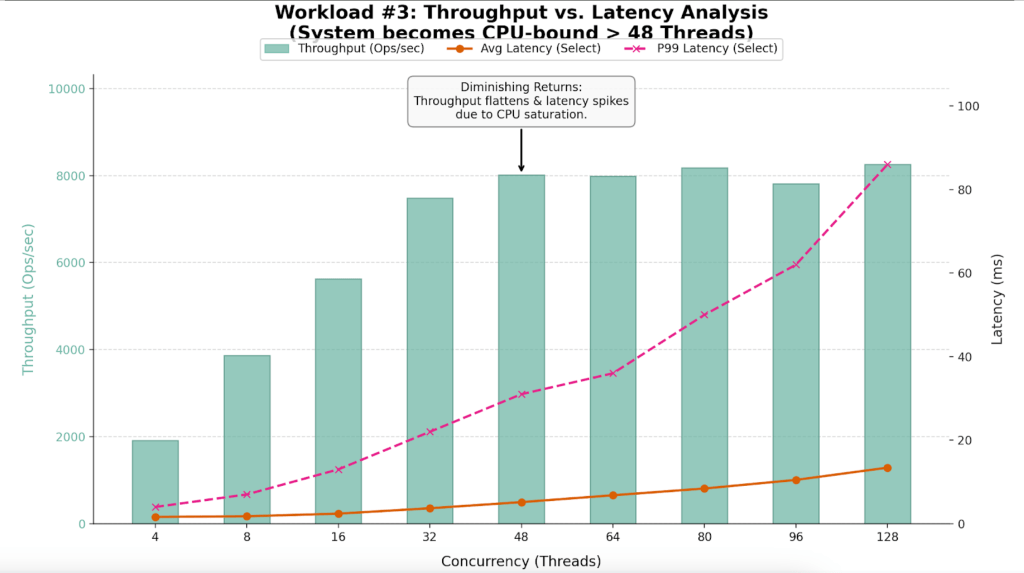
The desk under highlights the “Diminishing Returns” section clearly seen on this run.
| Staff (Threads) | Throughput (Ops/Sec) | Avg Latency (ms) | P99 Latency (ms) | Effectivity Verdict |
| 4 | 1,909 | 1.62 | 4.00 | Underutilized |
| 16 | 5,631 | 2.40 | 13.00 | Linear Scaling |
| 32 | 7,488 | 3.69 | 22.00 | Candy Spot |
| 48 | 8,014 | 5.16 | 31.00 | Saturation Level |
| 64 | 7,991 | 6.80 | 36.00 | Plateau |
| 80 | 8,179 | 8.42 | 50.00 | Latency Spike |
| 96 | 7,811 | 10.48 | 62.00 | Efficiency Loss |
| 128 | 8,256 | 13.41 | 86.00 | Extreme Queuing |
Findings
- The system saturates between 32 and 48 threads.
- At 32 threads, the system is environment friendly (7,488 Ops/Sec). By 48 threads, throughput positive aspects flatten (8,014 Ops/Sec), however latency degrades by 40%.
- Whereas common latency seems manageable, P99 (Tail) Latency triples at excessive load, ruining the person expertise.
Evaluation
- Throughput successfully flatlines round 8,000 Ops/Sec after 48 threads. The variance between 48 threads (8,014 Ops) and 128 threads (8,256 Ops) is negligible, but the associated fee in latency is huge.
- The P99 column reveals the hidden value of oversaturation. At 128 threads, 1% of customers are ready practically 100ms for a response, in comparison with simply 22ms on the optimum 32-thread degree.
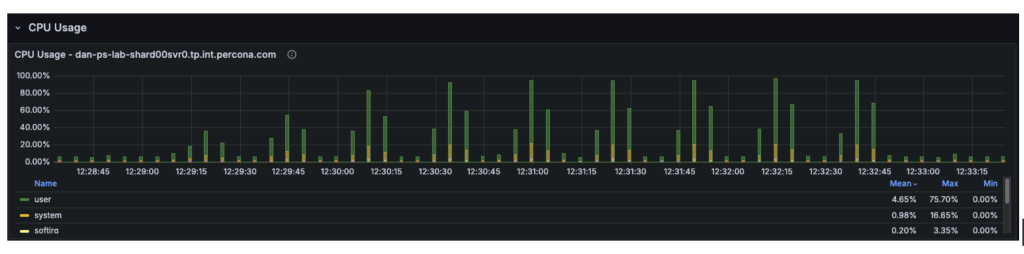
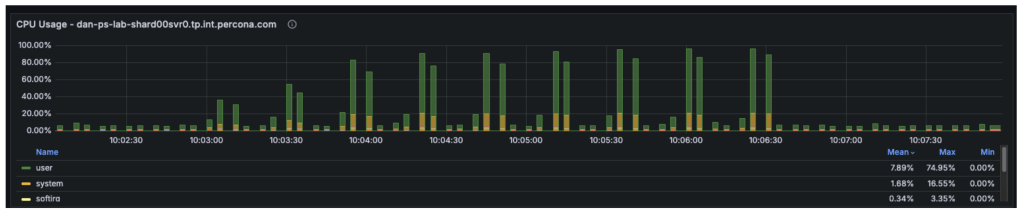
- Telemetry confirmed that at 48+ threads, the Consumer CPU utilization hit 80% and System CPU hit 16%. With the entire CPU utilization at 96%, the 4 vCPUs have been absolutely saturated, leaving requests ready within the run queue.
Potential Enhancements
Enabling secondary reads could possibly be one of the crucial impactful “fast wins” for sure workload configurations. The sections under clarify why this modification could possibly be useful, how a lot enchancment it will probably present, and the trade-offs concerned.
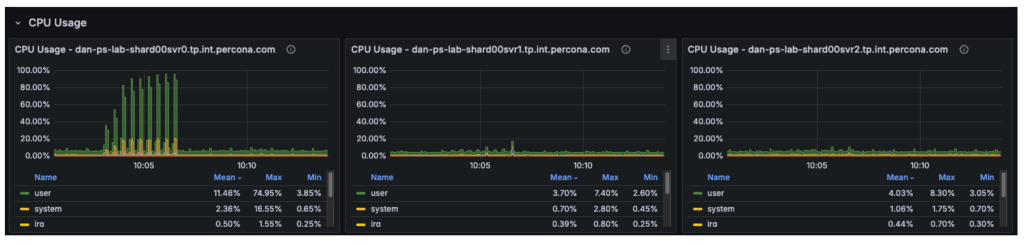
The cluster is a three-node reproduction set, and our observations have been as follows:
- Node 1 (Major): Operating at 100% CPU, dealing with all writes (insert/replace/delete) and all reads (choose).
- Node 2 (Secondary): Largely idle, solely making use of replication logs.
- Node 3 (Secondary): Largely idle, solely making use of replication logs.
Though the cluster has 12 vCPUs in whole, the workload is constrained by solely 4 vCPUs on the first. The remaining 8 vCPUs on the secondary nodes are underutilized.
Assumptions
With secondary reads enabled:
- The 54% learn workload (choose operations) is moved off the first and distributed throughout the 2 secondary nodes.
- The first is freed to focus its CPU assets virtually fully on write operations.
- Learn capability will increase considerably, as two nodes at the moment are devoted to serving reads reasonably than one.
- The first not processes roughly 4,700 reads per second, recovering roughly 50% of its CPU capability for write operations.
Total cluster throughput ought to improve from roughly 8,700 ops/sec to 12,000+ ops/sec, with the remaining restrict decided primarily by the first node’s write capability.
The graph under illustrates that in earlier checks, the secondary nodes carried virtually no workload, whereas the first was absolutely saturated.
Commerce-offs: Eventual Consistency
The “catch” is stale reads. MongoDB replication is asynchronous. There’s a delay (often milliseconds) between knowledge being written to the Major and showing on the Secondary.
- State of affairs: A person books a flight (Insert). The web page instantly refreshes to indicate “My Bookings” (Choose).
- Danger: If the Choose hits a Secondary that hasn’t caught up but, the brand new flight gained’t seem for a couple of milliseconds.
- Mitigation: For a flight search/reserving system, looking for flights (secondaryPreferred) is often wonderful, however checking your individual confirmed reserving ought to often keep on the first (primaryPreferred)
- This strategy will not be really useful for such workloads the place constant reads are a requirement
Workload #4
To validate our assumptions, we are able to reconfigure PLGM, reasonably than making any adjustments to the infrastructure. This is likely one of the key benefits of utilizing a benchmarking software like plgm: you may modify workload conduct via configuration as a substitute of altering the atmosphere.
PLGM helps offering further URI parameters both via its configuration file or through atmosphere variables. We’ll use an atmosphere variable in order that no configuration information should be modified. (For extra particulars on obtainable choices, you may run ./plgm_linux –assist or confer with the documentation)
We’ll run the identical blended workload as above and examine the outcomes utilizing the next setting:
|
PLGM_READ_PREFERENCE=secondaryPreferred |
|
for x in 4 8 16 32 48 64 80 96 128; do PLGM_PASSWORD=**** PLGM_CONCURRENCY=${x} PLGM_REPLICASET_NAME=“” PLGM_READ_PREFERENCE=“secondaryPreferred” PLGM_URI=“mongodb://dan-ps-lab-mongos00.tp.int.percona.com:27017,dan-ps-lab-mongos01.tp.int.percona.com:27017” ./plgm_linux config_plgm.yaml ; sleep 15; finished |
Evaluation
The introduction of readPreference=secondaryPreferred yielded virtually no efficiency enchancment. In reality, it barely degraded efficiency at excessive concurrency.
| Metric | Major Solely | Secondary Most popular | Change |
| Max Throughput | ~8,700 Ops/Sec | ~8,700 Ops/Sec | 0% (No Acquire) |
| Saturation Level | ~48 Threads | ~48 Threads | Equivalent |
| P99 Latency (128 Threads) | 86 ms | 65 ms | ~24% Higher |
| Avg Choose Latency (128 Threads) | 13.41 ms | 12.59 ms | Marginal Acquire |
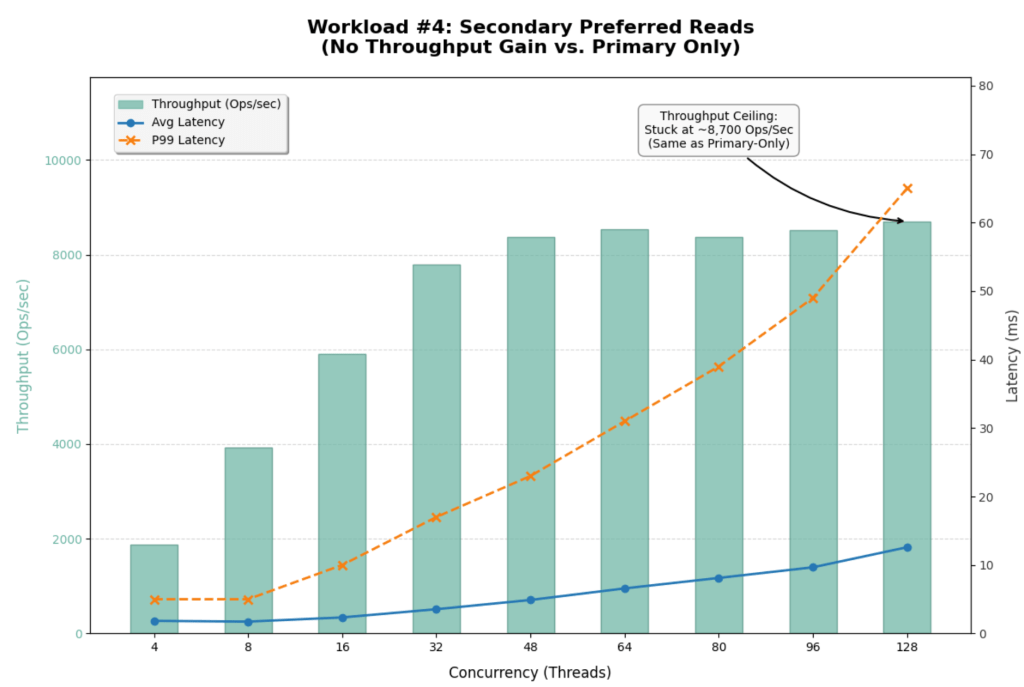
This end result strongly means that the Secondaries have been already busy or that the bottleneck will not be purely CPU on the Major.
- Replication Lag / Oplog Rivalry:
- Since our workload is 46% Writes, the Secondaries are busy simply making use of the Oplog to maintain up with the Major.
- MongoDB replication is single-threaded (or restricted concurrency) for making use of writes in lots of variations.
- By forcing reads to the Secondaries, you might be competing with the replication thread. If the Secondary falls behind, it has to work more durable, and skim latency suffers.
- Sharding Router Overhead (mongos):
- The bottleneck may be the mongos routers or the community bandwidth between the mongos and the shards, reasonably than the shard nodes themselves.
- If mongos is CPU saturated, it doesn’t matter what number of backend nodes you’ve gotten; the throughput gained’t improve.
- World Lock / Latch Rivalry:
- At 46% writes, you could be hitting collection-level or document-level lock competition that no quantity of read-replica scaling can repair.
Offloading reads to secondaries didn’t unlock hidden capability for this particular write-heavy workload. The cluster is essentially restricted by its capability to course of the 46% write quantity.
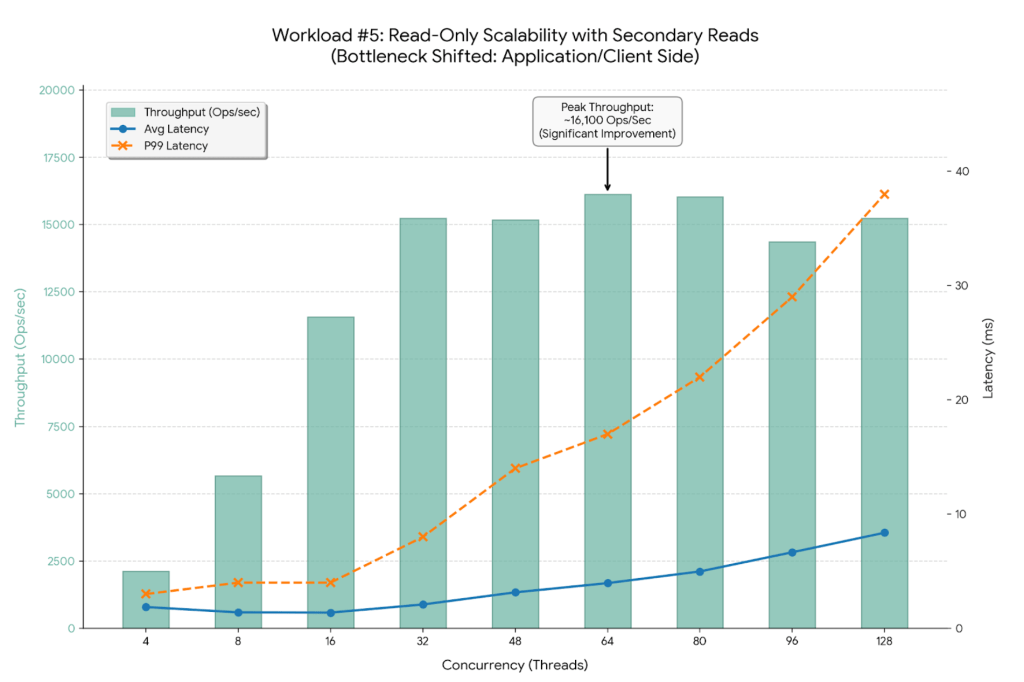
Workload #5
By switching to 100% Reads (PLGM_FIND_PERCENT=100) mixed with Secondary Reads (PLGM_READ_PREFERENCE=secondaryPreferred), now we have efficiently shifted the bottleneck away from the only Major node. The development is dramatic.
|
for x in 4 8 16 32 48 64 80 96 128; do PLGM_FIND_PERCENT=100 PLGM_PASSWORD=**** PLGM_CONCURRENCY=${x} PLGM_REPLICASET_NAME=“” PLGM_READ_PREFERENCE=“secondaryPreferred” PLGM_URI=“mongodb://dan-ps-lab-mongos00.tp.int.percona.com:27017,dan-ps-lab-mongos01.tp.int.percona.com:27017” ./plgm_linux config_plgm.yaml ; sleep 15; finished |
Evaluation
The graph under visualizes this new “unlocked” scalability. Discover how the latency strains (Blue and Orange) keep a lot flatter for for much longer in comparison with earlier checks.
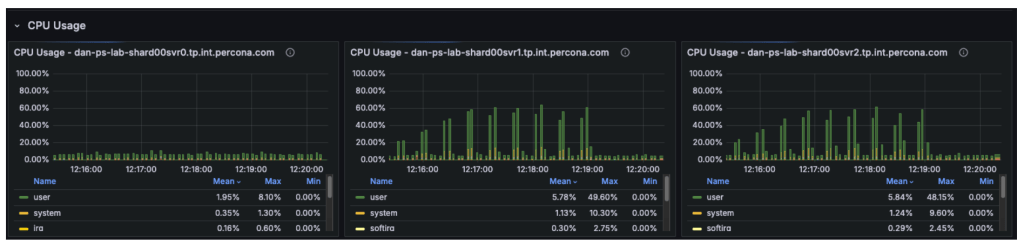
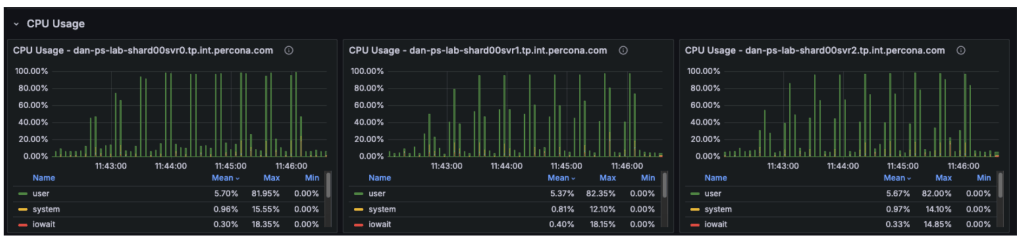
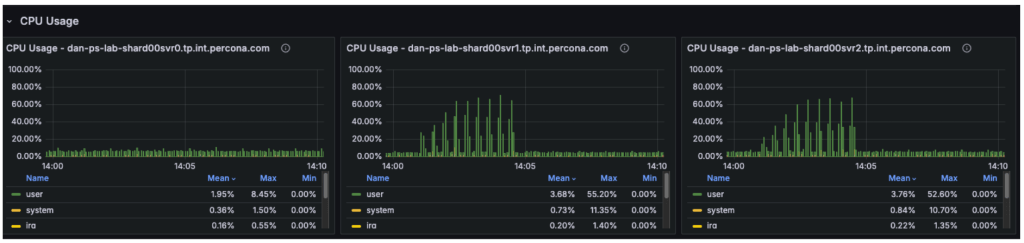
The CPU metrics and “Command Operations” charts verify our speculation concerning the shift in useful resource utilization:
- Major Node (svr0): CPU utilization has dropped considerably. With learn operations offloaded, the first node is now basically idle, dealing with solely metadata updates and the replication oplog.
- Secondary Nodes (svr1, svr2): These nodes have taken over the heavy lifting, with CPU utilization rising to roughly 50-60%.
- The New Bottleneck: For the reason that backend secondary nodes are working at solely ~50% capability, the database cluster itself is not saturated. The noticed throughput plateau at ~16,000 Ops/Sec signifies the bottleneck has moved upstream. Potential candidates for this new restrict embrace:
- Shopper-Facet Saturation: The machine working the plgm load generator could have reached its personal CPU or community limits.
- mongos Router Limits: The 2 router nodes could be hitting their limits for concurrent connections or packet processing.
- Community Bandwidth: The atmosphere could also be hitting the packet-per-second (PPS) ceiling of the digital community interface.
This represents the best consequence of a scaling train: the database has been tuned so successfully that it’s not the weak hyperlink within the utility stack.
Efficiency Beneficial properties Abstract
By optimizing the workload configuration, we achieved important enhancements throughout all key metrics:
- Throughput Improve:
- Earlier Baseline (Major Solely): Maxed out at ~13,600 Ops/Sec.
- New Configuration (Secondary Most popular): Maxed out at ~16,132 Ops/Sec.
- Complete Enchancment: A ~19% improve in peak throughput.
- Latency Stability:
- Common Latency: At peak throughput (64 threads), common latency improved to three.96ms, down from 4.71ms within the Major-Solely take a look at.
- P99 (Tail) Latency: Stability has improved dramatically. Even at 128 threads, P99 latency is just 38ms, an enormous discount from the 320ms noticed within the Major-Solely take a look at.
Workload #6
This workload represents the best situation for a read-heavy utility. It makes use of the identical workload because the baseline take a look at, with the one distinction being the implementation of the secondaryPreferred choice. By shifting 100% of the learn site visitors to the 2 secondary nodes, the system successfully triples its learn capability in comparison with the single-primary-node baseline.
|
for x in 4 8 16 32 48 64 80 96 128; do PLGM_READ_PREFERENCE=secondaryPreferred PLGM_PASSWORD=**** PLGM_CONCURRENCY=${x} PLGM_QUERIES_PATH=queries.json PLGM_FIND_PERCENT=100 PLGM_REPLICASET_NAME=“” PLGM_URI=“mongodb://dan-ps-lab-mongos00.tp.int.percona.com:27017,dan-ps-lab-mongos01.tp.int.percona.com:27017” ./plgm_linux config_plgm.yaml ; sleep 15; finished |
Evaluation
The graph under reveals how the throughput bars proceed to climb steadily all the way in which to 80-96 threads. The system is not hitting a tough “wall” at 48 threads.
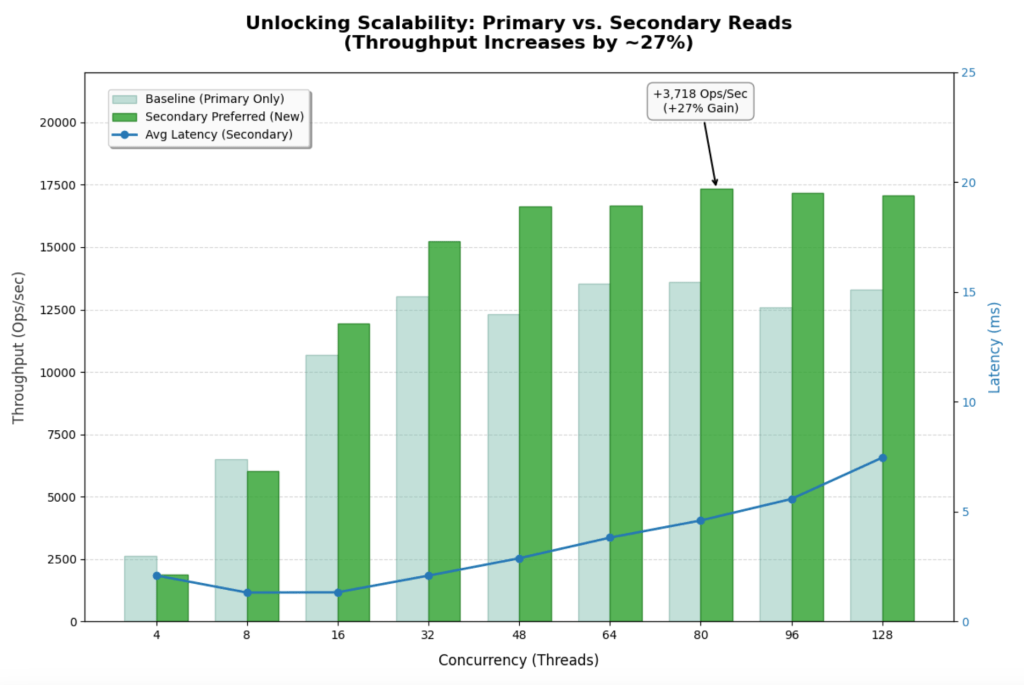
- Earlier Baseline (Major Solely): Maxed out at ~13,600 Ops/Sec.
- New Configuration (Secondary Most popular): Maxed out at ~17,328 Ops/Sec.
- Enchancment: ~27% improve in peak throughput.
Latency Stability
- Common latency stays extremely low (<5ms) even at very excessive concurrency. At 64 threads, it’s 3.82ms vs 4.71ms within the baseline.
- Tail Latency (P99) is probably the most spectacular stat. At 128 threads, P99 latency is just 32ms. Within the Major-Solely take a look at, it was 320ms. That could be a 10x enchancment in person expertise stability below load.
Bottleneck
- The flatlining of throughput round 17k-18k ops/sec suggests you might be not certain by database CPU. You’re seemingly hitting limits on the shopper facet (PLGM) or the community layer. The database nodes are fortunately processing all the pieces you throw at them.
Conclusion: The Artwork of Precision Benchmarking
By utilizing PLGM (Percona Load Generator for MongoDB) and telemetry, we have been capable of do excess of simply “stress take a look at” the database. We have been capable of isolate variables and incrementally step up concurrency. This precision allowed us to check completely different situations and inform a greater story:
- We recognized the uncooked CPU ceiling of a single Major node at 13.5k Ops/Sec.
- We revealed how a sensible “Combined Workload” (46% writes) slashes that capability by 35%, proving that write-heavy methods can’t merely be scaled by including extra learn replicas.
- By isolating a read-heavy situation on Secondaries, we shifted the bottleneck fully. We moved the constraint from the database {hardware} to the applying layer, unlocking a 20%+ throughput achieve and drastically stabilizing tail latency.
The Subsequent Frontier: Software-Facet Tuning
Our last take a look at revealed an vital shift in system conduct: the database is not the first bottleneck. Whereas backend nodes have been working at solely ~50% utilization, general throughput plateaued at roughly ~18k Ops/Sec, indicating the constraint has moved upstream. The efficiency restrict now seemingly resides within the utility server, the community layer, or the load generator itself, and future optimization efforts ought to deal with the next areas:
- Analyzing the applying code for thread competition or inefficient connection dealing with.
- Question optimization
- Investigating packet limits and community bandwidth saturation
- Vertical scaling of the applying servers to make sure they will drive the high-performance database cluster now we have now optimized.
That is the final word purpose of database benchmarking: to tune the information layer so successfully that it turns into invisible, forcing you to look elsewhere for the subsequent leap in efficiency.
Concerning the Writer
 Daniel Almeida
Daniel AlmeidaWith over 15 years of expertise in database administration and consulting, I concentrate on open supply applied sciences together with MongoDB, MySQL, MariaDB and CockroachDB. My work spans efficiency tuning, excessive availability, catastrophe restoration, cloud migrations, and automation. I’ve supported a variety of industries by delivering hands-on technical experience, architectural steerage, and proactive troubleshooting. Whether or not optimizing queries, designing HA options, or contributing to inside tooling, I deal with constructing resilient, environment friendly, and scalable database infrastructures.