

{kind=link}
The subject of checkpoint tuning is incessantly mentioned in lots of blogs. Nevertheless, I preserve coming throughout circumstances the place it’s stored untuned, leading to enormous wastage of server assets, fighting poor efficiency and different points.
So it’s time to reiterate the significance once more with extra particulars, particularly for brand spanking new customers.
What’s a checkpoint?
A checkpoint is a point-in-time at which PostgreSQL ensures that every thing within the storage stage is constant. That is vital for knowledge recoverability. If I quote the PostgreSQL documentation
“Checkpoints are factors within the sequence of transactions at which it’s assured that the heap and index knowledge recordsdata have been up to date with all info written earlier than that checkpoint. Any modifications made to knowledge recordsdata earlier than that time are assured to be already on disk.”
A checkpoint wants to make sure that the database may be safely restored from the backup or within the occasion of a crash. A checkpoint is the purpose from which restoration begins by making use of WALs
That is achieved by following
- Figuring out “Soiled” Buffers. As a result of transactions go away the soiled buffers within the shared_buffer.
- Writing to the Working System To be able to keep away from a large spike in disk I/O, PostgreSQL spreads this writing course of over a time frame outlined by the
checkpoint_completion_targetsetting. - fsync() each file to which the writing occurred, this to ensure that every thing is unbroken and reached the storage
- Updating the Management File PostgreSQL updates a particular file known as
international/pg_controlwith redo location - Recycling WAL Segments
PostgreSQL will both delete these outdated recordsdata or rename/recycle the outdated WAL recordsdata (the “transaction logs”) are now not wanted for crash restoration
Sure, there’s fairly a bit of labor.
Why is it inflicting uneven efficiency?
If we carefully observe the response efficiency of PostgreSQL if we offer a gradual workload, we could observe a noticed tooth sample
Past the fsync() overhead, the post-checkpoint efficiency dip is basically attributable to Full-Web page Picture Writes (FPI), as defined in one in all my earlier weblog put up. These are crucial to forestall knowledge corruption from web page tearing. Based on the documentation, PostgreSQL should log the complete content material of a web page the primary time it’s modified after a checkpoint. This course of ensures that if a crash happens mid-write, the web page may be restored. Consequently, the excessive quantity of FPIs proper after a checkpoint creates vital I/O spikes.
Right here is the extract from documentation
“… the PostgreSQL server writes the complete content material of every disk web page to WAL in the course of the first modification of that web page after a checkpoint. That is wanted as a result of a web page write that’s in course of throughout an working system crash may be solely partially accomplished, resulting in an on-disk web page that accommodates a mixture of outdated and new knowledge …”
So instantly after the checkpoint, there shall be numerous candidate pages for this full-page write. This causes IO spike and drop in efficiency.
How a lot IO can we save if we tune ?
The truthful reply shall be : Relies on the workload and schema.
Nevertheless, nothing stopping us from learning the potential financial savings utilizing some artificial workload like pgbench
For this research, I created a take a look at database to run pgbench workload with a set variety of transactions, This can assist us to match the WAL era for that variety of transactions:
Right here a set variety of transactions (1110000) shall be despatched by means of two connections every.
For comparability, I’m taking 4 completely different period of checkpoints, each 5 minutes (300s), quarter-hour (900s), half-an-hour (1800s) and 1 hour (3600s)
Following is my remark
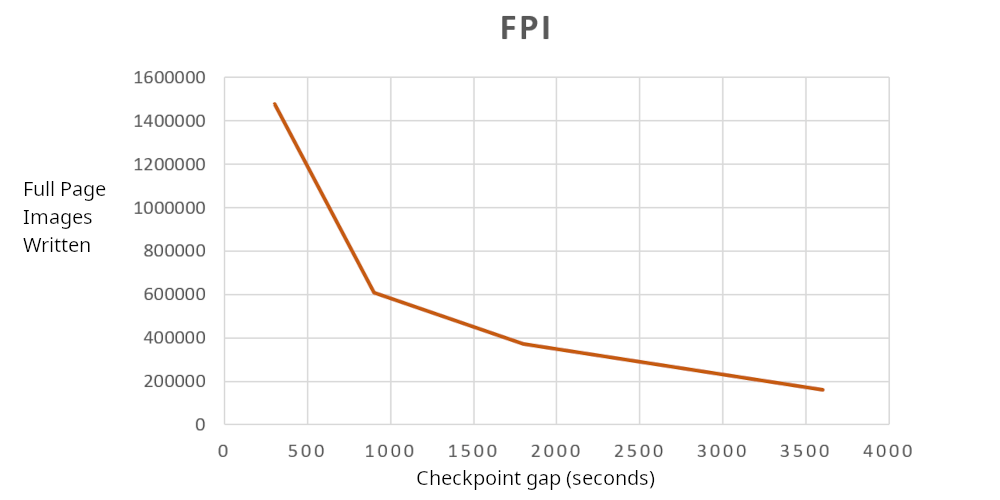
| CheckPoint hole (s) | WAL GB | WAL FPI |
| 300 | 11.93793559 | 1476817 |
| 900 | 5.382575691 | 608279 |
| 1800 | 3.611122672 | 372899 |
| 3600 | 2.030713106 | 161776 |
By spreading checkpoints, WAL Era drops from 12GB to 2GB, 6 occasions financial savings! That is very vital.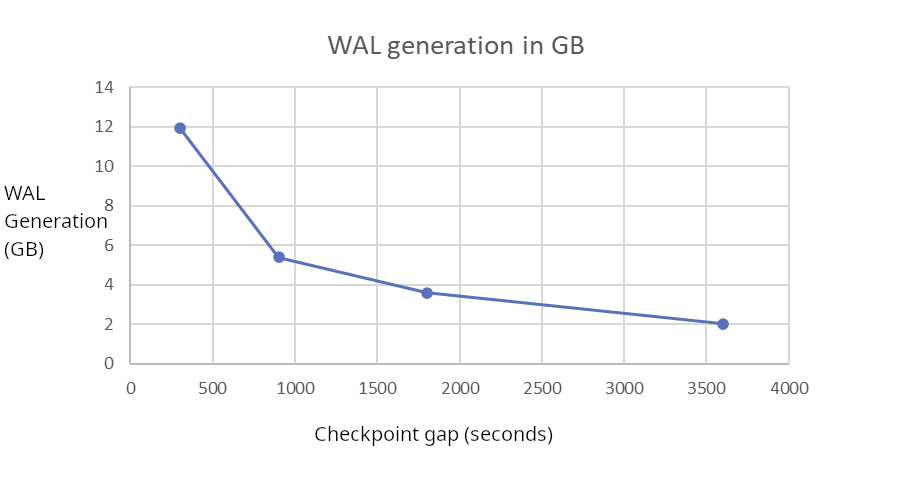
Full Web page Picture (FPI) writes diminished from 1.47 million to 161 thousand ranges, 9 occasions financial savings. Once more very vital
But One other issue which I wish to take into account is what’s the share of Full Pages in WAL. Sadly, it isn’t straightforward to get that info in present PostgreSQL variations until we use pg_waldump or pg_walinspect to extract this info.
The knowledge obtainable although pg_stat_wal will give us solely the variety of full web page photographs (wal_fpi). However these photographs will get compressed earlier than writing to WAL recordsdata.
The excellent news is that this function shall be obtainable within the upcoming launch : PostgreSQL 19. This function is already dedicated and a brand new area : wal_fpi_bytes is added to pg_stat_wal view
So for the aim of this weblog, I’m going to contemplate the uncompressed FPIs (wal_fpi * BLCKSZ). The proportion was diminished from 48.5% to 37.8% . So WAL recordsdata include extra share of transaction knowledge somewhat than Full Web page Pictures.
The advantages aren’t coming from FPI financial savings alone, If checkpoints are frequent, there’s a excessive probability of the identical buffer pages getting flushed time and again to recordsdata. If the checkpoints are sufficiently aside, the soiled pages can keep in shared_buffers, until there’s reminiscence stress.
Along with all of the useful resource financial savings, Its quite common customers report round 10% efficiency acquire simply by tuning the checkpoint.
Be aware : The above talked about take a look at outcomes are on PostgreSQL 18 and knowledge is collected from pg_stat_wal
Counter Arguments and fears
The commonest concern relating to spreading checkpoints over an extended period is the potential influence on crash restoration time. Since PostgreSQL should replay all WAL recordsdata generated because the final profitable checkpoint, an extended interval between checkpoints naturally will increase the amount of information that must be processed throughout restoration.
However the actuality is that a lot of the vital methods can have standby with HA Resolution like Patroni. If there’s a crash, nobody wants to attend for crash restoration. There shall be speedy failover to standby. So the time it takes for a crash restoration doesn’t actually matter for database availability. So wherever switchover to standby if the first crashes or goes unavailable (HA), the time it takes for crash restoration turns into irrelevant.
One other issue is, even when the PostgreSQL occasion is standalone with none standby to failover, there’s significantly much less WAL era after the checkpoint tuning, so it turns into straightforward for PostgreSQL to use these few WAL recordsdata. So part of the issue attributable to spreading the checkpoint will get solved by its personal constructive results.
One more false impression I heard a couple of database with no standby to failover is : if checkpoints are 1 hour aside, restoration will take 1 hour. Undoubtedly Not. The restoration charge is on no account associated to the hole between checkpoints. Usually it takes just a few seconds or minutes to get better an hour value of WAL. However, Sure it depends upon the the quantity of WAL recordsdata to be utilized, Lets validate this utilizing info from PostgreSQL logs.
Following are two examples of crash restoration of typical databases, the place the infrastructure is beneath common.
|
LOG: database system was not correctly shut down; computerized restoration in progress LOG: redo begins at 14/EB49CB90 LOG: redo completed at 15/6BEECAD8 system utilization: CPU: person: 18.60 s, system: 6.98 s, elapsed: 25.59 s |
One more
|
LOG: redo begins at 15/6BEECB78 LOG: redo completed at 16/83686B48 system utilization: CPU: person: 47.79 s, system: 14.05 s, elapsed: 69.08 s |
If we take into account the primary case:
The restoration is ready to apply WAL from LSN 14/EB49CB90 to fifteen/6BEECAD8 in 25.19 seconds
|
postgres=# SELECT pg_wal_lsn_diff( ’15/6BEECAD8′,’14/EB49CB90′ )/25.19; ?column? ———————————– 85680702.818578801112 (1 row) |
85680702 Bytes/sec = 81.71 MB/sec
On a median we frequently see restoration simply archiving 64MB/Sec or above, even on a sluggish system. Because of this a lot of the cases shall be finishing the restoration in a few minutes even when the checkpoint is one hour aside. Effectively, it depends upon the WALs to be utilized which depends upon WAL era charge.
Learn how to Tune Checkpointing
PostgreSQL supplies primarily three parameters to tune the check-pointer behaviour
- checkpoint_timeout : This parameter permit us to plan for separating the checkpoints. As a result of on each checkpoint_timout, a checkpoint shall be triggered. So successfully that is the utmost time between two checkpoints. If we’re planning to have computerized checkpoints separated by 1 hour, that is the primary parameter which we ought to be adjusting. I usually desire a price of half-hour (1800s) minimal for manufacturing methods with Bodily standbys.
- max_wal_size : That is the utmost dimension goal for PostgreSQL to let the WAL develop between computerized checkpoints. So if a small worth of this parameter can set off frequent checkpoints. Such frequent checkpoints will additional amplify the WAL era as a consequence of FPI as talked about earlier, inflicting additional knock-down impact. So this worth ought to be set such that the PostgreSQL holds ample WAL recordsdata between two deliberate checkpoints.
- checkpoint_completion_target : which is given as a fraction of the checkpoint interval (configured by utilizing checkpoint_timeout). The I/O charge is adjusted in order that the checkpoint finishes when the given fraction of checkpoint_timeout seconds have elapsed, (or earlier than max_wal_size is exceeded, whichever is sooner). The default and customarily beneficial worth is 0.9, Which implies that the checkpointer can make the most of the 90% of the time between two checkpoints to unfold the I/O load. However one of the best advice I ever noticed, if the checkpoint_timeouts is large enough; like half an hour or an hour is :
|
checkpoint_completion_target = (checkpoint_timeout – 2min) / checkpoint_timeout |
Learn how to Monitor
If the parameter log_checkpoints is enabled, Particulars of every checkpoint shall be logged into PostgreSQL log, For instance, following is an log entry from a database with checkpoint_timeout of 60 minutes and checkpoint_completion_target of 0.9 (90%)
|
2026–01–14 16:16:48.181 UTC [226618] LOG: checkpoint beginning: time 2026–01–14 17:10:51.463 UTC [226618] LOG: checkpoint full: wrote 4344 buffers (1.7%), wrote 381 SLRU buffers; 0 WAL file(s) added, 0 eliminated, 549 recycled; write=3239.823 s, sync=0.566 s, complete=3243.283 s; sync recordsdata=28, longest=0.156 s, common=0.021 s; distance=8988444 kB, estimate=11568648 kB; lsn=26/2E954A50, redo lsn=24/1514C308 |
This pattern log entry tells us {that a} timed checkpoint (as a consequence of checkpoint_timeout ) is began at 16:16:48.181 and accomplished at 17:10:51.463. Meaning 3243282 milliseconds. That is showing as “complete” within the checkpoint completion entry. The checkpointer needed to write solely 4344 buffers (8kB every), which is roughly 34MB.
We are able to see that writing of this 34MB occurred over 3239.823 s (54minutes). So the checkpointer may be very mild on I/O. This 54 minutes is as a result of
|
checkpoint_timout * checkpoint_completion_arget = 60 * 0.9 = 54 |
The distance=8988444 kB tells us how a lot WAL is generated between checkpoints (Distance from earlier checkpoint). This tells us the WAL era charge in the course of the time.
The estimate=11568648 kB (≈11.5 GB) represents PostgreSQL’s prediction of WAL era between THIS checkpoint and the NEXT checkpoint. PostgreSQL controls the throttle of IO to easy the IO load such that examine pointing completes earlier than reaching max_wal_size
Along with this, PostgreSQL presents the cumulative statistics of WAL era although stats view pg_stat_wal (From PostgreSQL 14 onwards). Checkpointer abstract info is obtainable although pg_stat_bgwriter (until PostgreSQL 16) and there’s a devoted pg_stat_checkpointer view obtainable from PostgreSQL 17 onward.
Abstract
Verify-pointing causes a lot of WAL era, which has direct influence on total IO subsystem within the server, which in flip impacts the efficiency, backup and WAL retention. Tuning checkpointer has many advantages
- Saves tons by way of costly WAL IO which is synchronous by nature
- Related efficiency advantages as a consequence of significantly much less IO is implicit and apparent. The distinction shall be very seen in these methods the place IO efficiency and cargo are the constraints.
- It helps to cut back the load of WAL archiving and financial savings in backup infra and storage
- Much less WAL era means much less probability of the system operating out of area
- Much less probability of standby lags.
- Saves community bandwidth, as a consequence of much less knowledge to transmitted for each replication and backups (WAL archiving).
General it is among the first steps each DBA ought to take as a part of tuning the database. Its completely OK to unfold the checkpoint over 1hour or extra if there’s HA framework like Patroni.
Concerning the Creator
 Jobin Augustine
Jobin AugustineJobin Augustine is a PostgreSQL professional and Open Supply advocate and has greater than 21 years of working expertise as a advisor, architect, administrator, author, and coach in PostgreSQL, Oracle and different database applied sciences. He has at all times been an lively participant within the Open Supply communities, and his major focus space is database efficiency and optimization. Jobin is a daily face in lots of the PostgreSQL conferences and has introduced at numerous conferences for the final 6+ years. He’s a contributor to a number of Open Supply Initiatives, an lively blogger, and loves coding in C++ and Python. Jobin holds a Grasp’s in Laptop Purposes; At the moment, he’s the PostgreSQL Escalation Specialist for Percona. Beforehand, he labored at OpenSCG for 2 years as an architect and was a part of the BigSQL core staff. Earlier to his work at OpenSCG, Jobin labored at Dell as Database Senior Advisor for ten years and one other 5 years with TCS/CMC.