
{kind=link}

Picture by Writer
# Introduction
OCR (Optical Character Recognition) fashions are gaining new recognition daily. I’m seeing new open-source fashions pop up on Hugging Face which have crushed earlier benchmarks, providing higher, smarter, and smaller options.
Gone are the times when importing a PDF meant getting plain textual content with a lot of points. We now have full transformations, new AI fashions that perceive paperwork, tables, diagrams, sections, and totally different languages, changing them into extremely correct markdown format textual content. This creates a real 1-to-1 digital copy of your textual content.
On this article, we’ll evaluation the highest 7 OCR fashions that you would be able to run domestically with none points to parse your photographs, PDFs, and even photographs into good digital copies.
# 1. olmOCR 2 7B 1025

olmOCR-2-7B-1025 is a vision-language mannequin optimized for optical character recognition on paperwork.
Launched by the Allen Institute for Synthetic Intelligence, the olmOCR-2-7B-1025 mannequin is fine-tuned from Qwen2.5-VL-7B-Instruct utilizing the olmOCR-mix-1025 dataset and additional enhanced with GRPO reinforcement studying coaching.
The mannequin achieves an total rating of 82.4 on the olmOCR-bench analysis, demonstrating sturdy efficiency on difficult OCR duties together with mathematical equations, tables, and complicated doc layouts.
Designed for environment friendly large-scale processing, it really works greatest with the olmOCR toolkit which supplies automated rendering, rotation, and retry capabilities for dealing with thousands and thousands of paperwork.
Listed here are the highest 5 key options:
- Adaptive Content material-Conscious Processing: Mechanically classifies doc content material sorts together with tables, diagrams, and mathematical equations to use specialised OCR methods for enhanced accuracy
- Reinforcement Studying Optimization: GRPO RL coaching particularly enhances accuracy on mathematical equations, tables, and different troublesome OCR circumstances
- Wonderful Benchmark Efficiency: Scores 82.4 total on olmOCR-bench with sturdy outcomes throughout arXiv paperwork, outdated scans, headers, footers, and multi-column layouts
- Specialised Doc Processing: Optimized for doc photographs with longest dimension of 1288 pixels and requires particular metadata prompts for greatest outcomes
- Scalable Toolkit Assist: Designed to work with the olmOCR toolkit for environment friendly VLLM-based inference able to processing thousands and thousands of paperwork
# 2. PP OCR v5 Server Det

PaddleOCR VL is an ultra-compact vision-language mannequin particularly designed for environment friendly multilingual doc parsing.
Its core element, PaddleOCR-VL-0.9B, integrates a NaViT-style dynamic decision visible encoder with the light-weight ERNIE-4.5-0.3B language mannequin to realize state-of-the-art efficiency whereas sustaining minimal useful resource consumption.
Supporting 109 languages together with Chinese language, English, Japanese, Arabic, Hindi, and Thai, the mannequin excels at recognizing advanced doc parts resembling textual content, tables, formulation, and charts.
By complete evaluations on OmniDocBench and in-house benchmarks, PaddleOCR-VL demonstrates superior accuracy and quick inference speeds, making it extremely sensible for real-world deployment situations.
Listed here are the highest 5 key options:
- Extremely-Compact 0.9B Structure: Combines a NaViT-style dynamic decision visible encoder with ERNIE-4.5-0.3B language mannequin for resource-efficient inference whereas sustaining excessive accuracy
- State-of-the-Artwork Doc Parsing: Achieves main efficiency on OmniDocBench v1.5 and v1.0 for total doc parsing, textual content recognition, system extraction, desk understanding, and studying order detection
- Intensive Multilingual Assist: Acknowledges 109 languages overlaying main world languages and various scripts together with Cyrillic, Arabic, Devanagari, and Thai for actually world doc processing
- Complete Factor Recognition: Excels at figuring out and extracting textual content, tables, mathematical formulation, and charts together with advanced layouts and difficult content material like handwritten textual content and historic paperwork
- Versatile Deployment Choices: Helps a number of inference backends together with native PaddleOCR toolkit, transformers library, and vLLM server for optimized efficiency throughout totally different deployment situations
# 3. OCRFlux 3B
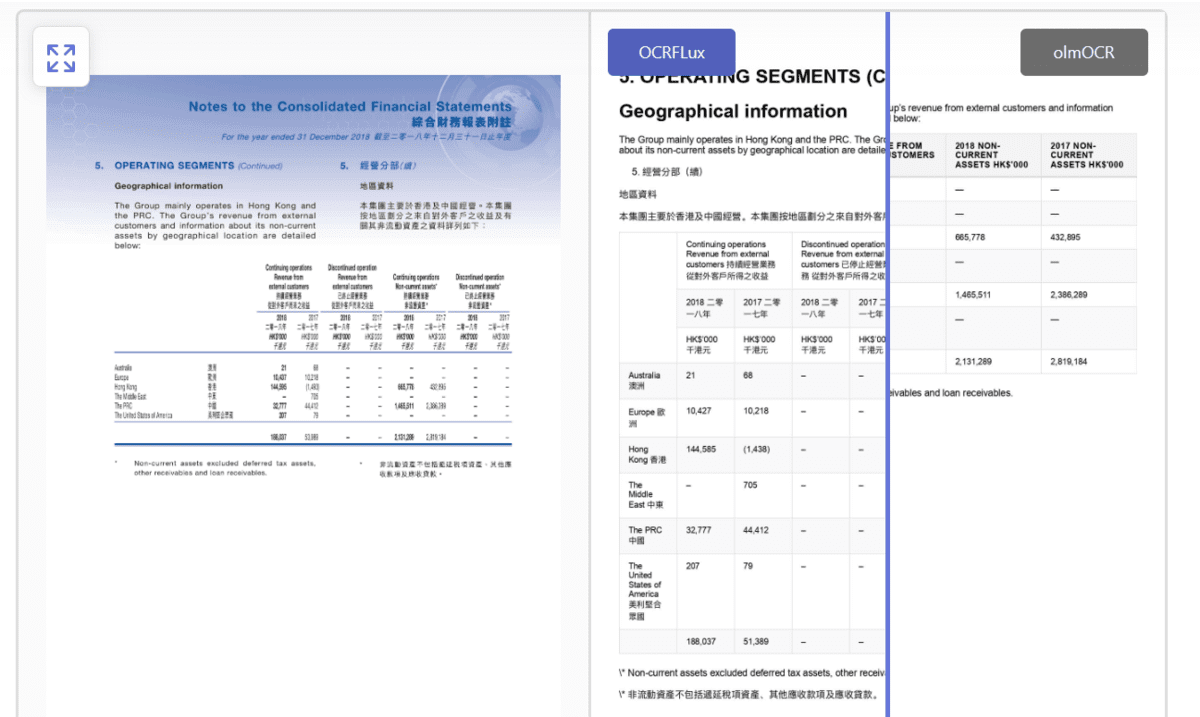
OCRFlux-3B is a preview launch of a multimodal massive language mannequin fine-tuned from Qwen2.5-VL-3B-Instruct for changing PDFs and pictures into clear, readable Markdown textual content.
The mannequin leverages personal doc datasets and the olmOCR-mix-0225 dataset to realize superior parsing high quality.
With its compact 3 billion parameter structure, OCRFlux-3B can run effectively on shopper {hardware} just like the GTX 3090 whereas supporting superior options like native cross-page desk and paragraph merging.
The mannequin achieves state-of-the-art efficiency on complete benchmarks and is designed for scalable deployment by way of the OCRFlux toolkit with vLLM inference help.
Listed here are the highest 5 key options:
- Distinctive Single-Web page Parsing Accuracy: Achieves an Edit Distance Similarity of 0.967 on OCRFlux-bench-single, considerably outperforming olmOCR-7B-0225-preview, Nanonets-OCR-s, and MonkeyOCR
- Native Cross-Web page Construction Merging: First open-source mission to natively help detecting and merging tables and paragraphs that span a number of pages, attaining 0.986 F1 rating on cross-page detection
- Environment friendly 3B Parameter Structure: Compact mannequin design permits deployment on GTX 3090 GPUs whereas sustaining excessive efficiency by vLLM-optimized inference for processing thousands and thousands of paperwork
- Complete Benchmarking Suite: Supplies intensive analysis frameworks together with OCRFlux-bench-single and cross-page benchmarks with manually labeled floor fact for dependable efficiency measurement
- Scalable Manufacturing-Prepared Toolkit: Contains Docker help, Python API, and an entire pipeline for batch processing with configurable employees, retries, and error dealing with for enterprise deployment
# 4. MiniCPM-V 4.5
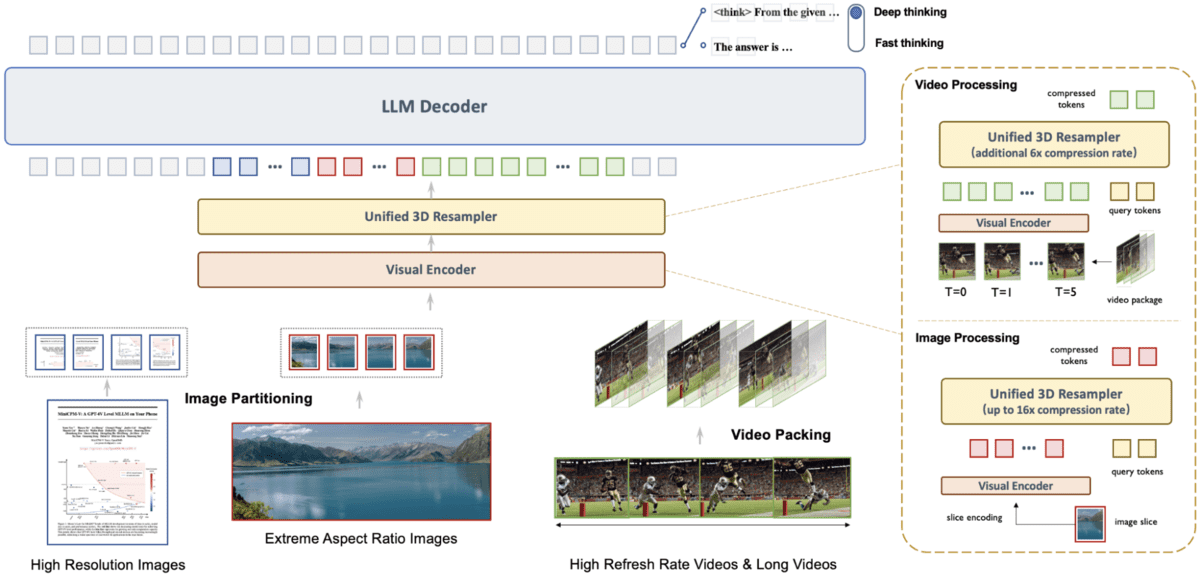
MiniCPM-V 4.5 is the newest mannequin within the MiniCPM-V sequence, providing superior optical character recognition and multimodal understanding capabilities.
Constructed on Qwen3-8B and SigLIP2-400M with 8 billion parameters, this mannequin delivers distinctive efficiency for processing textual content inside photographs, paperwork, movies, and a number of photographs instantly on cellular units.
It achieves state-of-the-art outcomes throughout complete benchmarks whereas sustaining sensible effectivity for on a regular basis purposes.
Listed here are the highest 5 key options:
- Distinctive Benchmark Efficiency: State-of-the-art imaginative and prescient language efficiency with a 77.0 common rating on OpenCompass, surpassing bigger fashions like GPT-4o-latest and Gemini-2.0 Professional
- Revolutionary Video Processing: Environment friendly video understanding utilizing a unified 3D-Resampler that compresses video tokens 96 occasions, enabling high-FPS processing as much as 10 frames per second
- Versatile Reasoning Modes: Controllable hybrid quick and deep pondering modes for switching between fast responses and complicated reasoning
- Superior Textual content Recognition: Robust OCR and doc parsing that processes excessive decision photographs as much as 1.8 million pixels, attaining main scores on OCRBench and OmniDocBench
- Versatile Platform Assist: Simple deployment throughout platforms with llama.cpp and ollama help, 16 quantized mannequin sizes, SGLang and vLLM integration, advantageous tuning choices, WebUI demo, iOS app, and on-line internet demo
# 5. InternVL 2.5 4B
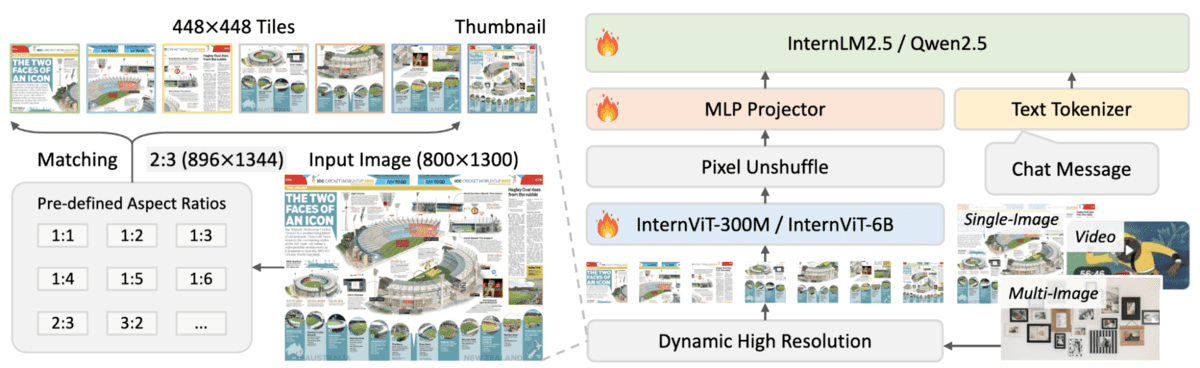
InternVL2.5-4B is a compact multimodal massive language mannequin from the InternVL 2.5 sequence, combining a 300 million parameter InternViT imaginative and prescient encoder with a 3 billion parameter Qwen2.5 language mannequin.
With 4 billion whole parameters, this mannequin is particularly designed for environment friendly optical character recognition and complete multimodal understanding throughout photographs, paperwork, and movies.
It employs a dynamic decision technique that processes visible content material in 448 by 448 pixel tiles whereas sustaining sturdy efficiency on textual content recognition and reasoning duties, making it appropriate for useful resource constrained environments.
Listed here are the highest 5 key options:
- Dynamic Excessive Decision Processing: Handles single photographs, a number of photographs, and video frames by dividing them into adaptive 448 by 448 pixel tiles with clever token discount by pixel unshuffle operations
- Environment friendly Three Stage Coaching: Encompasses a rigorously designed pipeline with MLP warmup, non-compulsory imaginative and prescient encoder incremental studying for specialised domains, and full mannequin instruction tuning with strict knowledge qc
- Progressive Scaling Technique: Trains the imaginative and prescient encoder with smaller language fashions first earlier than transferring to bigger ones, utilizing lower than one tenth of the tokens required by comparable fashions
- Superior Information High quality Filtering: Employs a complete pipeline with LLM based mostly high quality scoring, repetition detection, and heuristic rule based mostly filtering to take away low high quality samples and forestall mannequin degradation
- Robust Multimodal Efficiency: Delivers aggressive outcomes on OCR, doc parsing, chart understanding, multi picture comprehension, and video evaluation whereas preserving pure language capabilities by improved knowledge curation
# 6. Granite Imaginative and prescient 3.3 2b

Granite Imaginative and prescient 3.3 2b is a compact and environment friendly vision-language mannequin launched on June eleventh, 2025, designed particularly for visible doc understanding duties.
Constructed upon the Granite 3.1-2b-instruct language mannequin and SigLIP2 imaginative and prescient encoder, this open-source mannequin permits automated content material extraction from tables, charts, infographics, plots, and diagrams.
It introduces experimental options together with picture segmentation, doctags era, and multi-page doc help whereas providing enhanced security in comparison with earlier variations.
Listed here are the highest 5 key options:
- Superior Doc Understanding Efficiency: Achieves improved scores throughout key benchmarks together with ChartQA, DocVQA, TextVQA, and OCRBench, outperforming earlier granite-vision variations
- Enhanced Security Alignment: Options improved security scores on RTVLM and VLGuard datasets, with higher dealing with of political, racial, jailbreak, and deceptive content material
- Experimental Multipage Assist: Educated to deal with query answering duties utilizing as much as 8 consecutive pages from a doc, enabling lengthy context processing
- Superior Doc Processing Options: Introduces novel capabilities together with picture segmentation and doctags era for parsing paperwork into structured textual content codecs
- Environment friendly Enterprise-Targeted Design: Compact 2 billion parameter structure optimized for visible doc understanding duties whereas sustaining 128 thousand token context size
# 7. Trocr Giant Printed

The TrOCR large-sized mannequin fine-tuned on SROIE is a specialised transformer-based optical character recognition system designed for extracting textual content from single-line photographs.
Based mostly on the structure launched within the paper “TrOCR: Transformer-based Optical Character Recognition with Pre-trained Fashions,” this encoder-decoder mannequin combines a BEiT-initialized picture Transformer encoder with a RoBERTa-initialized textual content Transformer decoder.
The mannequin processes photographs as sequences of 16 by 16 pixel patches and autoregressively generates textual content tokens, making it notably efficient for printed textual content recognition duties.
Listed here are the highest 5 key options:
- Transformer Based mostly Structure: Encoder-decoder design with picture Transformer encoder and textual content Transformer decoder for end-to-end optical character recognition
- Pretrained Element Initialization: Leverages BEiT weights for picture encoder and RoBERTa weights for textual content decoder for higher efficiency
- Patch Based mostly Picture Processing: Processes photographs as fixed-size 16 by 16 patches with linear embedding and place embeddings
- Autoregressive Textual content Technology: Decoder generates textual content tokens sequentially for correct character recognition
- SROIE Dataset Specialization: Advantageous-tuned on the SROIE dataset for enhanced efficiency on printed textual content recognition duties
# Abstract
Here’s a comparability desk that rapidly summarizes main open-source OCR and vision-language fashions, highlighting their strengths, capabilities, and optimum use circumstances.
| Mannequin | Params | Major Power | Particular Capabilities | Finest Use Case |
|---|---|---|---|---|
| olmOCR-2-7B-1025 | 7B | Excessive-accuracy doc OCR | GRPO RL coaching, equation and desk OCR, optimized for ~1288px doc inputs | Giant-scale doc pipelines, scientific and technical PDFs |
| PaddleOCR v5 / PaddleOCR-VL | 1B | Multilingual parsing (109 languages) | Textual content, tables, formulation, charts; NaViT-based dynamic visible encoder | World multilingual OCR with light-weight, environment friendly inference |
| OCRFlux-3B | 3B | Markdown-accurate parsing | Cross-page desk and paragraph merging; optimized for vLLM | PDF-to-Markdown pipelines; runs nicely on shopper GPUs |
| MiniCPM-V 4.5 | 8B | State-of-the-art multimodal OCR | Video OCR, help for 1.8MP photographs, quick and deep-thinking modes | Cellular and edge OCR, video understanding, multimodal duties |
| InternVL 2.5-4B | 4B | Environment friendly OCR with multimodal reasoning | Dynamic 448×448 tiling technique; sturdy textual content extraction | Useful resource-limited environments; multi-image and video OCR |
| Granite Imaginative and prescient 3.3 (2B) | 2B | Visible doc understanding | Charts, tables, diagrams, segmentation, doctags, multi-page QA | Enterprise doc extraction throughout tables, charts, and diagrams |
| TrOCR Giant (Printed) | 0.6B | Clear printed-text OCR | 16×16 patch encoder; BEiT encoder with RoBERTa decoder | Easy, high-quality printed textual content extraction |
Abid Ali Awan (@1abidaliawan) is a licensed knowledge scientist skilled who loves constructing machine studying fashions. At the moment, he’s specializing in content material creation and writing technical blogs on machine studying and knowledge science applied sciences. Abid holds a Grasp’s diploma in know-how administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college kids scuffling with psychological sickness.