

{kind=link}
Introduction
AI in 2026 is shifting from uncooked textual content turbines to brokers that act and motive. Specialists predict a give attention to sustained reasoning and multi-step planning in AI brokers. In follow, this implies LLMs should suppose earlier than they communicate, breaking duties into steps and verifying logic earlier than outputting solutions. Certainly, latest analyses argue that 2026 will likely be outlined by reasoning-first LLMs-models that deliberately use inside deliberation loops to enhance correctness. These fashions will energy autonomous brokers, self-debugging code assistants, strategic planners, and extra.
On the similar time, real-world AI deployment now calls for rigor: “the query is now not ‘Can AI do that?’ however ‘How nicely, at what price, and for whom?’”. Thus, open fashions that ship high-quality reasoning and sensible effectivity are vital.
Reasoning-centric LLMs matter as a result of many rising applications- from superior QA and coding to AI-driven research-require multi-turn logical chains. For instance, agentic workflows depend on fashions that may plan and confirm steps over lengthy contexts. Benchmarks of 2025 present that specialised reasoning fashions now rival proprietary methods on math, logic, and tool-using duties. Briefly, reasoning LLMs are the engines behind next-gen AI brokers and decision-makers.
On this weblog, we’ll discover the highest 10 open-source reasoning LLMs of 2026, their benchmark efficiency, architectural improvements, and deployment methods.
What Is a Reasoning LLM?
Reasoning LLMs are fashions tuned or designed to excel at multi-step, logic-driven duties (puzzles, superior math, iterative problem-solving) slightly than one-shot Q&A. They sometimes generate intermediate steps or ideas of their outputs.
As an example, answering “If a practice goes 60 mph for 3 hours, how far?” requires computing distance = velocity×time earlier than answering-a easy reasoning process. A real reasoning mannequin would explicitly embody the computation step in its response. Extra advanced duties equally demand chain-of-thought. In follow, reasoning LLMs usually have considering mode: both they output their chain-of-thought in textual content, or they run hidden iterations of inference internally.
Fashionable reasoning fashions are these refined to excel at advanced duties finest solved with intermediate steps, corresponding to puzzles, math proofs, and coding challenges. They sometimes embody specific reasoning content material within the response. Importantly, not all LLMs have to be reasoning LLMs: easier duties like translation or trivia don’t require them. In actual fact, utilizing a heavy reasoning mannequin in all places might be wasteful and even “overthinking.” The secret is matching instruments to duties. However for superior agentic and STEM purposes, these reasoning-specialist LLMs are important.
Architectural Patterns of Reasoning-First Fashions
Reasoning LLMs usually make use of specialised architectures and coaching:
- Combination of Specialists (MoE): Many high-end reasoning fashions use MoE to pack trillions of parameters whereas activating solely a fraction per token. For instance, Qwen3-Subsequent-80B prompts solely 3B parameters through 512 specialists, and GLM-4.7 is 355B whole with ~32B energetic. Moonshot’s Kimi K2 makes use of ~1T whole parameters (32B energetic) throughout 384 specialists. Nemotron 3 Nano (NVIDIA) makes use of ~31.6B whole (3.2B energetic, through a hybrid MoE Transformer). MoE permits enormous mannequin capability for advanced reasoning with decrease per-token compute.
- Prolonged Context Home windows: Reasoning duties usually span lengthy dialogues or paperwork. Thus many fashions natively help enormous context sizes (128K-1M tokens). Kimi K2 and Qwen-coder fashions help 256K (extensible to 1M) contexts. LLaMA 3.3 extends to 128K tokens. Nemotron-3 helps as much as 1M context size. Lengthy context is essential for multi-step plan monitoring, instrument historical past, and doc understanding.
- Chain-of-Thought and Pondering Modes: Architecturally, reasoning LLMs usually have specific “considering” modes. For instance, Kimi K2 solely outputs in a “considering” format with
… blocks, imposing chain-of-thought. Qwen3-Subsequent-80B-Pondering routinely features atag in its immediate to pressure reasoning mode. DeepSeek-V3.2 exposes an endpoint that by default produces an inside chain of thought earlier than ultimate solutions. These modes might be toggled or managed at inference time, buying and selling off latency vs. reasoning depth. - Coaching Strategies: Past structure, many reasoning fashions bear specialised coaching. OpenAI’s gpt-oss-120B and NVIDIA’s Nemotron all use RL from suggestions (usually with math/programming rewards) to spice up problem-solving. For instance, DeepSeek-R1 and R1-Zero had been skilled with large-scale RL to straight optimize reasoning capabilities. Nemotron-3 was fine-tuned with a mixture of supervised fine-tuning (SFT) on reasoning information and multi-environment RL . Qwen3-Subsequent and GPT-OSS each undertake “considering” coaching the place the mannequin is explicitly skilled to generate reasoning steps. Such focused coaching yields markedly higher efficiency on reasoning benchmarks.
- Effectivity and Quantizations: To make these massive fashions sensible, many use aggressive quantization or distillation. Kimi K2 is natively INT4-quantized. Nemotron Nano was post-quantized to FP8 for quicker throughput. GPT-OSS-20B/120B are optimized to run on commodity GPUs. Moonshot’s MiniMax additionally emphasizes an “environment friendly design”: solely 10B activated parameters (with ~230B whole) to suit advanced agent duties.
Collectively, these patterns – MoE scaling, enormous contexts, chain-of-thought coaching, and cautious tuning – outline right this moment’s reasoning LLM architectures.
1. GPT-OSS-120B
GPT-OSS-120B is a production-ready open-weight mannequin launched in 2025. It makes use of a Combination-of-Specialists (MoE) design with 117B whole / 5.1B energetic parameters.
GPT-OSS-120B achieves near-parity with OpenAI’s o4-mini on core reasoning benchmarks, whereas working on a single 80GB GPU. It additionally outperforms different open fashions of comparable measurement on reasoning and gear use.
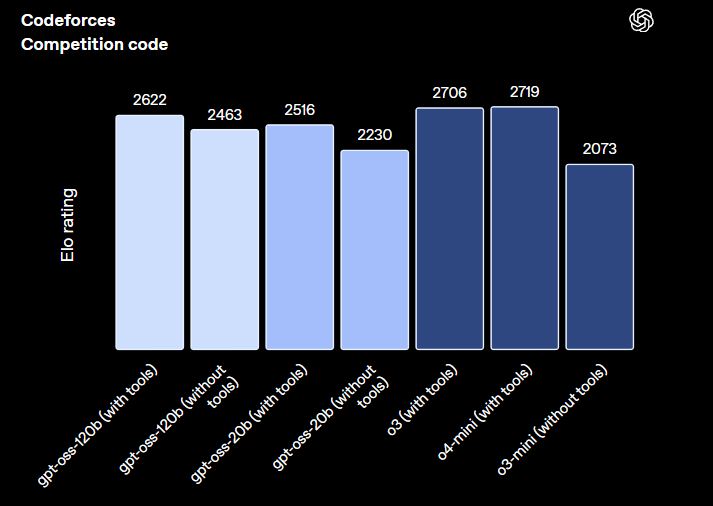
It additionally is available in a 20B model optimized for effectivity: the 20B mannequin matches o3-mini and may run on simply 16GB of RAM, making it ultimate for native or edge use. Each fashions help chain-of-thought with
Key specs:
|
Variant |
Complete Params |
Lively Params |
Min VRAM (quantized) |
Goal {Hardware} |
Latency Profile |
|
gpt-oss-120B |
117B |
5.1B |
80GB |
1x H100/A100 80GB |
180-220 t/s |
|
gpt-oss-20B |
21B |
3.6B |
16GB |
RTX 4070/4060 Ti |
45-55 t/s |
Strengths and Limits
- Execs: Close to-proprietary reasoning (AIME/GPQA parity), single-GPU viable, full CoT/instrument APIs for brokers.
- Cons: 120B deploy nonetheless wants tensor-parallel for <80GB setups; neighborhood fine-tunes nascent; no native picture/imaginative and prescient.
Optimized for latency
- GPT-OSS-120B can run on 1×A100/H100 (80GB), and OSS-20B on a 16GB GPU.
- Sturdy chain-of-thought & instrument use help.
2. GLM-4.7
GLM-4.7 is a 355B-parameter open mannequin with task-oriented reasoning enhancements. It was designed not only for Q&A however for end-to-end agentic coding and problem-solving. GLM-4.7 introduces “think-before-acting” and multi-turn reasoning controls to stabilize advanced duties. For instance, it implements “Interleaved Reasoning”, which means it performs a chain-of-thought earlier than each instrument name or response. It additionally has “Retention-Based mostly” and “Spherical-Degree” reasoning modes to maintain or skip interior monologue as wanted. These options let it adaptively commerce latency for accuracy.
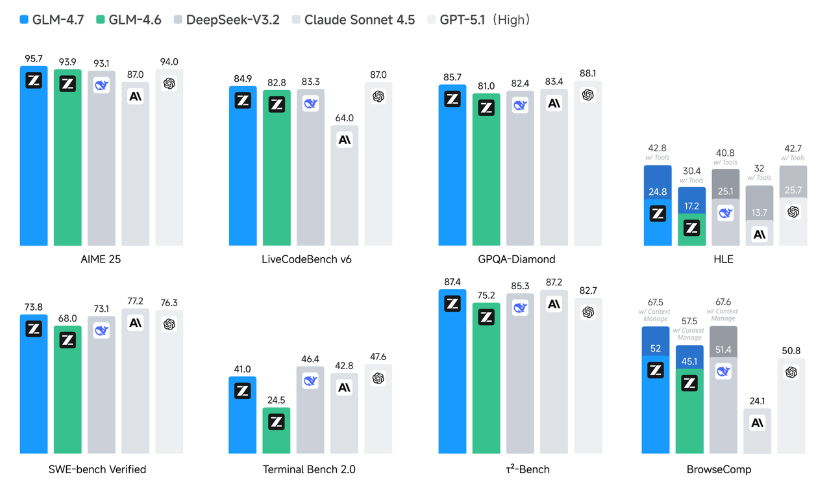
Efficiency‑sensible, GLM‑4.7 leads open-source fashions throughout reasoning, coding, and agent duties. On the Humanity’s Final Examination (HLE) benchmark with instrument use, it scores ~42.8 %, a major enchancment over GLM‑4.6 and aggressive with different high-performing open fashions. In coding, GLM‑4.7 achieves ~84.9 % on LiveCodeBench v6 and ~73.8 % on SWE-Bench Verified, surpassing earlier GLM releases.
The mannequin additionally demonstrates sturdy agent functionality on benchmarks corresponding to BrowseComp and τ²‑Bench, showcasing multi-step reasoning and gear integration. Collectively, these outcomes replicate GLM-4.7’s broad functionality throughout logic, coding, and agent workflows, in an open-weight mannequin launched beneath the MIT license.
Key Specs
- Structure: Sparse Combination-of-Specialists
- Complete parameters: ~355B (reported)
- Lively parameters: ~32B per token (reported)
- Context size: As much as ~200K tokens
- Main use instances: Coding, math reasoning, agent workflows
- Availability: Open-weight; business use permitted (license varies by launch)
Strengths
- Sturdy efficiency in multi-step reasoning and coding
- Designed for agent-style execution loops
- Lengthy-context help for advanced duties
- Aggressive with main open reasoning fashions
Weaknesses
- Excessive inference price on account of scale
- Superior reasoning will increase latency
- Restricted English-first documentation
3. Kimi K2 Pondering
Kimi K2 Pondering is a trillion-parameter Combination-of-Specialists mannequin designed particularly for deep reasoning and gear use. It options roughly 1 trillion whole parameters however prompts solely 32 billion per token throughout 384 specialists. The mannequin helps a local context window of 256K tokens, which extends to 1 million tokens utilizing Yarn. Kimi K2 was skilled in INT4 precision, delivering as much as 2x quicker inference speeds.
The structure is absolutely agentic and all the time thinks first. Based on the mannequin card, Kimi K2-Pondering solely helps considering mode, the place the system immediate routinely inserts a
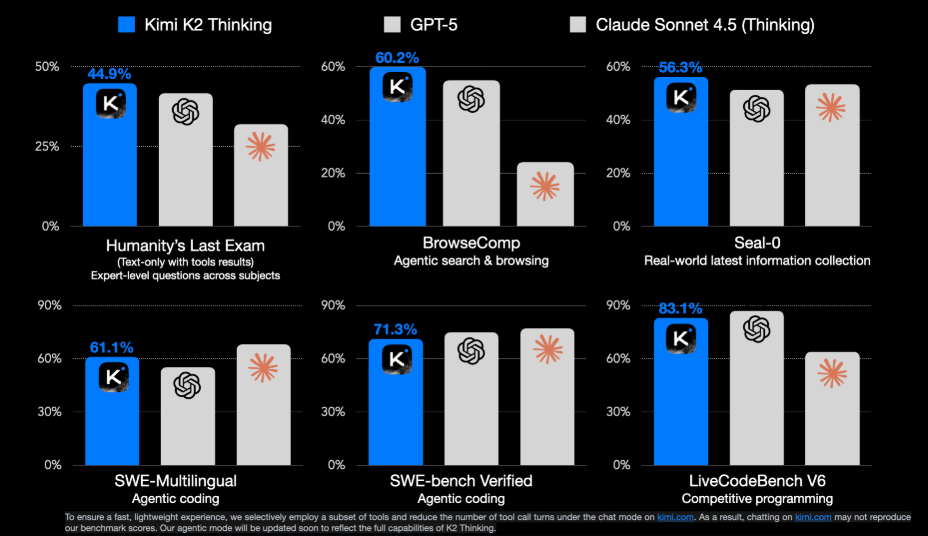
Kimi K2 Pondering leads throughout the proven benchmarks, scoring 44.9% on Humanity’s Final Examination, 60.2% on BrowseComp, and 56.3% on Seal-0 for real-world info assortment. It additionally performs strongly in agentic coding and multilingual duties, reaching 61.1% on SWE-Multilingual, 71.3% on SWE-bench Verified, and 83.1% on LiveCodeBench V6.
Total, these outcomes present Kimi K2 Pondering outperforming GPT-5 and Claude Sonnet 4.5 throughout reasoning, agentic, and coding evaluations.
Key Specs
- Structure: Giant-scale MoE
- Complete parameters: ~1T (reported)
- Lively parameters: ~32B per token
- Specialists: 384
- Context size: 256K (as much as ~1M with scaling)
- Main use instances: Deep reasoning, planning, long-context brokers
- Availability: Open-weight; business use permitted
Strengths
- Wonderful long-horizon reasoning
- Very massive context window
- Sturdy tool-use and planning functionality
- Environment friendly inference relative to whole measurement
Weaknesses:
- Really monumental scale (1T) means daunting coaching/inference overhead.
- Nonetheless early (new launch), so real-world adoption/tooling is nascent.
4. MiniMax-M2.1
MiniMax-M2.1 is one other agentic LLM geared towards tool-interactive reasoning. It makes use of a 230B whole param design with solely 10B activated per token, implying a big MoE or related sparsity.
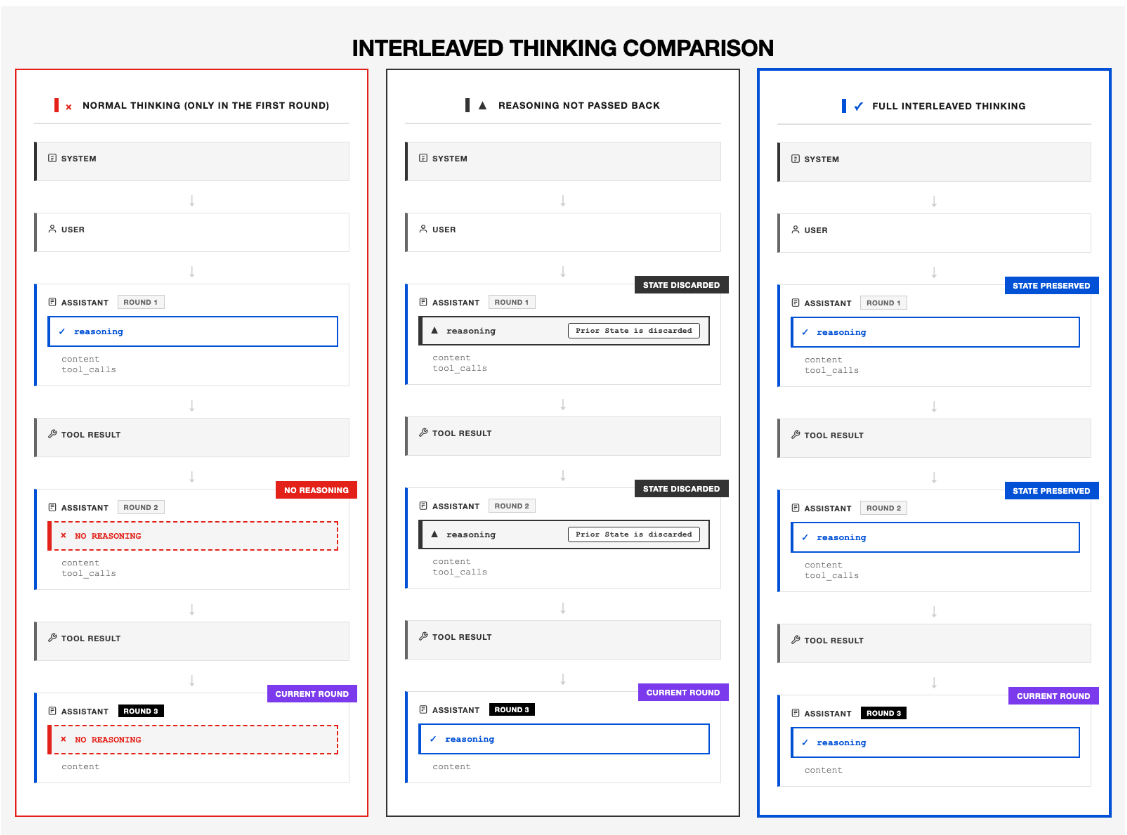
The mannequin helps interleaved reasoning and motion, permitting it to motive, name instruments, and react to observations throughout prolonged agent loops. This makes it well-suited for duties involving lengthy sequences of actions, corresponding to internet navigation, multi-file coding, or structured analysis duties.
MiniMax stories robust inside outcomes on agent benchmarks corresponding to SWE-Bench, BrowseComp, and xBench. In follow, M2.1 is commonly paired with inference engines like vLLM to help perform calling and multi-turn agent execution.
Key Specs
- Structure: Sparse, agent-optimized LLM
- Complete parameters: ~230B (reported)
- Lively parameters: ~10B per token
- Context size: Lengthy context (precise measurement not publicly specified)
- Main use instances: Software-based brokers, lengthy workflows
- Availability: Open-weight (license particulars restricted)
Strengths
- Objective-built for agent workflows
- Excessive reasoning effectivity per energetic parameter
- Sturdy long-horizon process dealing with
Weaknesses
- Restricted public benchmarks and documentation
- Smaller ecosystem than friends
- Requires optimized inference setup
5. DeepSeek-R1-Distill-Qwen3-8B
DeepSeek-R1-Distill-Qwen3-8B represents probably the most spectacular achievements in environment friendly reasoning fashions. Launched in Might 2025 as a part of the DeepSeek-R1-0528 replace, this 8-billion parameter mannequin demonstrates that superior reasoning capabilities might be efficiently distilled from large fashions into compact, accessible codecs with out important efficiency degradation.
The mannequin was created by distilling chain-of-thought reasoning patterns from the total 671B parameter DeepSeek-R1-0528 mannequin and making use of them to fine-tune Alibaba’s Qwen3-8B base mannequin. This distillation course of used roughly 800,000 high-quality reasoning samples generated by the total R1 mannequin, specializing in mathematical problem-solving, logical inference, and structured reasoning duties. The result’s a mannequin that achieves state-of-the-art efficiency amongst 8B-class fashions whereas requiring solely a single GPU to run.
Efficiency-wise, DeepSeek-R1-Distill-Qwen3-8B delivers outcomes that defy its compact measurement. It outperforms Google’s Gemini 2.5 Flash on AIME 2025 mathematical reasoning duties and almost matches Microsoft’s Phi 4 reasoning mannequin on HMMT benchmarks. Maybe most remarkably, this 8B mannequin matches the efficiency of Qwen3-235B-Pondering on sure reasoning duties—a 235B parameter mannequin. The R1-0528 replace considerably improved reasoning depth, with accuracy on AIME 2025 leaping from 70% to 87.5% in comparison with the unique R1 launch.
The mannequin runs effectively on a single GPU with 40-80GB VRAM (corresponding to an NVIDIA H100 or A100), making it accessible to particular person researchers, small groups, and organizations with out large compute infrastructure. It helps the identical superior options as the total R1-0528 mannequin, together with system prompts, JSON output, and performance calling—capabilities that make it sensible for manufacturing purposes requiring structured reasoning and gear integration.
Key Specs
- Mannequin kind: Distilled reasoning mannequin
- Base structure: Qwen3-8B (dense transformer)
- Complete parameters: 8B
- Coaching strategy: Distillation from DeepSeek-R1-0528 (671B) utilizing 800K reasoning samples
- {Hardware} necessities: Single GPU with 40-80GB VRAM
- License: MIT License (absolutely permissive for business use)
- Main use instances: Mathematical reasoning, logical inference, coding help, resource-constrained deployments
Strengths
- Distinctive performance-to-size ratio: matches 235B fashions on particular reasoning duties at 8B measurement
- Runs effectively on single consumer-grade GPU, dramatically decreasing deployment obstacles
- Outperforms a lot bigger fashions like Gemini 2.5 Flash on mathematical reasoning
- Absolutely open-source with permissive MIT licensing allows unrestricted business use
- Helps fashionable options: system prompts, JSON output, perform calling for manufacturing integration
- Demonstrates profitable distillation of superior reasoning from large fashions to compact codecs
Weaknesses
- Whereas spectacular for its measurement, nonetheless trails the total 671B R1 mannequin on essentially the most advanced reasoning duties
- 8B parameter restrict constrains multilingual capabilities and broad area data
- Requires particular inference configurations (temperature 0.6 advisable) for optimum efficiency
- Nonetheless comparatively new (Might 2025 launch) with restricted manufacturing battle-testing in comparison with extra established fashions
6. DeepSeek-V3.2 Terminus
DeepSeek’s V3 sequence (codename “Terminus”) builds on the R1 fashions and is designed for agentic AI workloads. It makes use of a Combination-of-Specialists transformer with ~671B whole parameters and ~37B energetic parameters per token.
DeepSeek-V3.2 introduces a Sparse Consideration structure for long-context scaling. It replaces full consideration with an indexer-selector mechanism, lowering quadratic consideration price whereas sustaining accuracy near dense consideration.
As proven within the beneath determine, the eye layer combines Multi-Question Consideration, a Lightning Indexer, and a Prime-Okay Selector. The indexer identifies related tokens, and a spotlight is computed solely over the chosen subset, with RoPE utilized for positional encoding.
The mannequin is skilled with large-scale reinforcement studying on duties corresponding to math, coding, logic, and gear use. These expertise are built-in right into a shared mannequin utilizing Group Relative Coverage Optimization.
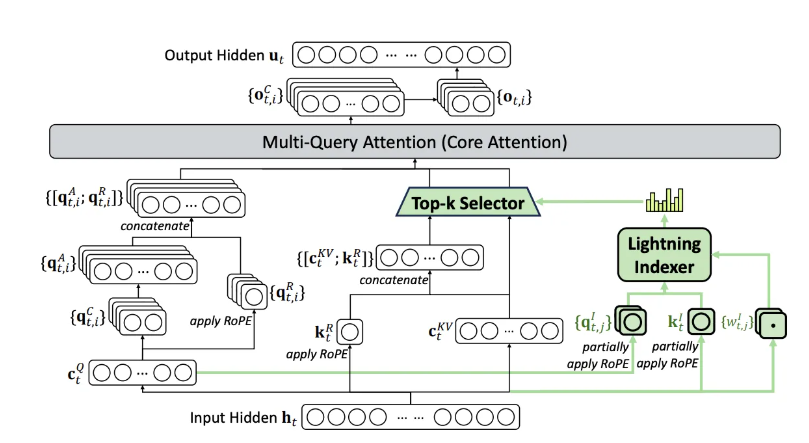
Fig- Consideration-architecture of deepseek-v3.2
DeepSeek stories that V3.2 achieves reasoning efficiency corresponding to main proprietary fashions on public benchmarks. The V3.2-Speciale variant is additional optimized for deep multi-step reasoning.
DeepSeek-V3.2 is MIT-licensed, accessible through manufacturing APIs, and outperforms V3.1 on combined reasoning and agent duties.
Key specs
- Structure: MoE transformer with DeepSeek Sparse Consideration
- Complete parameters: ~671B (MoE capability)
- Lively parameters: ~37B per token
- Context size: Helps prolonged contexts as much as ~1M tokens with sparse consideration
- License: MIT (open-weight)
- Availability: Open weights + manufacturing API through DeepSeek.ai
Strengths
- State-of-the-art open reasoning: DeepSeek-V3.2 constantly ranks on the high of open-source reasoning and agent duties.
- Environment friendly long-context inference: DeepSeek Sparse Consideration (DSA) reduces price development on very lengthy sequences relative to plain dense consideration with out considerably hurting accuracy.
- Agent integration: Constructed-in help for considering modes and mixed instrument/chain-of-thought workflows makes it well-suited for autonomous methods.
- Open ecosystem: MIT license and API entry through internet/app ecosystem encourage adoption and experimentation.
Weaknesses
- Giant compute footprint: Regardless of sparse inference financial savings, the general mannequin measurement and coaching price stay important for self-hosting.
- Advanced tooling: Superior considering modes and full agent workflows require experience to combine successfully.
- New launch: As a comparatively latest era, broader neighborhood benchmarks and tooling help proceed to mature.
7. Qwen3-Subsequent-80B-A3B
Qwen3-Subsequent is Alibaba’s next-gen open mannequin sequence emphasizing each scale and effectivity. The 80B-A3B-Pondering variant is specifically designed for advanced reasoning: it combines hybrid consideration (linearized + sparse mechanisms) with a high-sparsity MoE. Its specs are placing: 80B whole parameters, however solely ~3B energetic (512 specialists with 10 energetic). This yields very quick inference. Qwen3-Subsequent additionally makes use of multi-token prediction (MTP) throughout coaching for velocity.
Benchmarks present Qwen3-Subsequent-80B performing excellently on multi-hop duties. The mannequin card highlights that it outperforms earlier Qwen-30B and Qwen-32B considering fashions, and even outperforms the proprietary Gemini-2.5-Flash on a number of benchmarks. For instance, it will get ~87.8% on AIME25 (math) and ~73.9% on HMMT25, higher than Gemini-2.5-Flash’s 72.0% and 73.9% respectively. It additionally reveals robust efficiency on MMLU and coding checks.
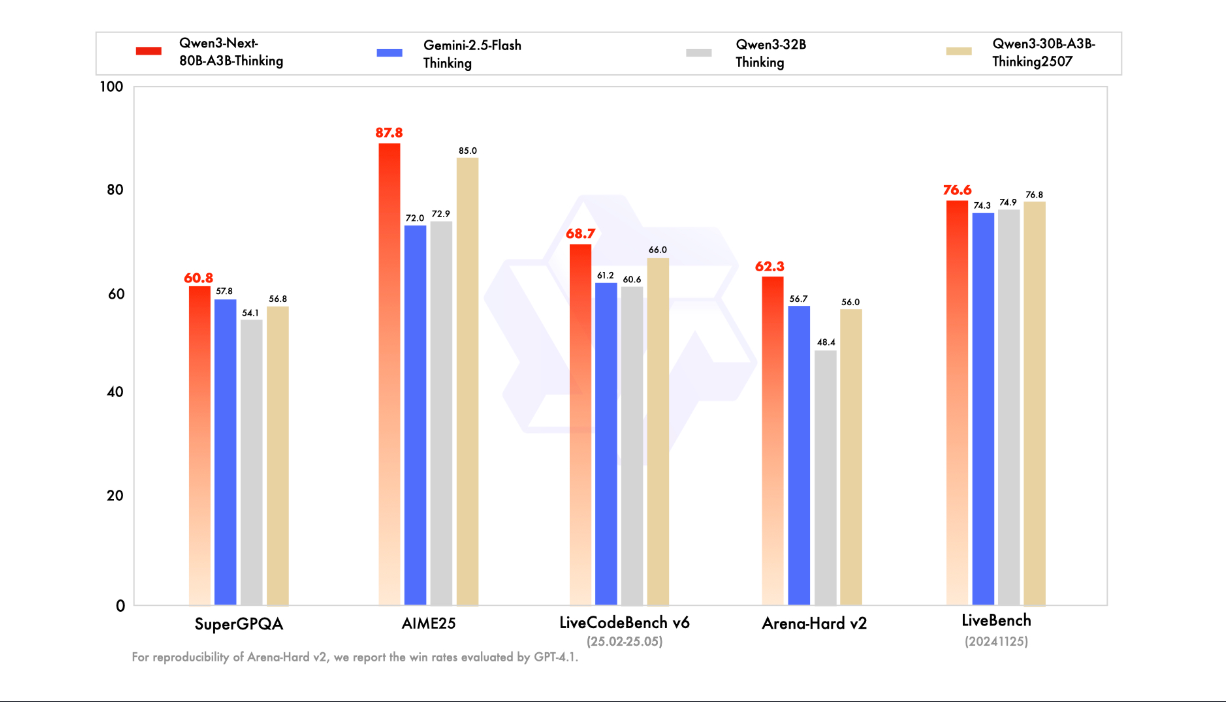
Key specs: 80B whole, 3B energetic. 48 layers, hybrid format with 262K native context. Absolutely Apache-2.0 licensed.
Strengths: Wonderful reasoning & coding efficiency per compute (beats bigger fashions on many duties); enormous context; extraordinarily environment friendly (10× velocity up for >32K context vs older Qwens).
Weaknesses: As a MoE mannequin, it could require particular runtime help; “Pondering” mode provides complexity (all the time generates a
8. Qwen3-235B-A22B
Qwen3-235B-A22B represents Alibaba’s most superior open reasoning mannequin up to now. It makes use of a large Combination-of-Specialists structure with 235 billion whole parameters however prompts solely 22 billion per token, reaching an optimum steadiness between functionality and effectivity. The mannequin employs the identical hybrid consideration mechanism as Qwen3-Subsequent-80B (combining linearized and sparse consideration) however scales it to deal with much more advanced reasoning chains.
The “A22B” designation refers to its 22B energetic parameters throughout a extremely sparse professional system. This design permits the mannequin to take care of reasoning high quality corresponding to a lot bigger dense fashions whereas retaining inference prices manageable. Qwen3-235B-A22B helps dual-mode operation: it could actually run in normal mode for fast responses or swap to “considering mode” with specific chain-of-thought reasoning for advanced duties.
Efficiency-wise, Qwen3-235B-A22B excels throughout mathematical reasoning, coding, and multi-step logical duties. On AIME 2025, it achieves roughly 89.2%, outperforming many proprietary fashions. It scores 76.8% on HMMT25 and maintains robust efficiency on MMLU-Professional (78.4%) and coding benchmarks like HumanEval (91.5%). The mannequin’s long-context functionality extends to 262K tokens natively, with optimized dealing with for prolonged reasoning chains.
The structure incorporates multi-token prediction throughout coaching, which improves each coaching effectivity and the mannequin’s skill to anticipate reasoning paths. This makes it notably efficient for duties requiring ahead planning, corresponding to advanced mathematical proofs or multi-file code refactoring.
Key Specs
- Structure: Hybrid MoE with dual-mode (normal/considering) operation
- Complete parameters: ~235B
- Lively parameters: ~22B per token
- Context size: 262K tokens native
- License: Apache-2.0
- Main use instances: Superior mathematical reasoning, advanced coding duties, multi-step downside fixing, long-context evaluation
Strengths
- Distinctive mathematical and logical reasoning efficiency, surpassing many bigger fashions
- Twin-mode operation permits flexibility between velocity and reasoning depth
- Extremely environment friendly inference relative to reasoning functionality (22B energetic vs. 235B whole)
- Native long-context help with out requiring extensions or particular configurations
- Complete Apache-2.0 licensing allows business deployment
Weaknesses
- Requires MoE-aware inference runtime (vLLM, DeepSpeed, or related)
- Pondering mode provides latency and token overhead for easy queries
- Much less mature ecosystem in comparison with LLaMA or GPT variants
- Documentation primarily in Chinese language, with English supplies nonetheless creating
9. MiMo-V2-Flash
MiMo-V2-Flash represents an aggressive push towards ultra-efficient reasoning by a 309 billion parameter Combination-of-Specialists structure that prompts solely 15 billion parameters per token. This 20:1 sparsity ratio is among the many highest in manufacturing reasoning fashions, enabling inference speeds of roughly 150 tokens per second whereas sustaining aggressive efficiency on mathematical and coding benchmarks.
The mannequin makes use of a sparse gating mechanism that dynamically routes tokens to specialised professional networks. This structure permits MiMo-V2-Flash to realize exceptional price effectivity, working at simply 2.5% of Claude’s inference price whereas delivering comparable efficiency on particular reasoning duties. The mannequin was skilled with a give attention to mathematical reasoning, coding, and structured problem-solving.
MiMo-V2-Flash delivers spectacular benchmark outcomes, reaching 94.1% on AIME 2025, inserting it among the many high performers for mathematical reasoning. In coding duties, it scores 73.4% on SWE-Bench Verified and demonstrates robust efficiency on normal programming benchmarks. The mannequin helps a 128K token context window and is launched beneath an open license allowing business use.
Nonetheless, real-world efficiency reveals some limitations. Group testing signifies that whereas MiMo-V2-Flash excels on mathematical and coding benchmarks, it could actually battle with instruction following and general-purpose duties outdoors its core coaching distribution. The mannequin performs finest when duties carefully match mathematical competitions or coding challenges however reveals inconsistent high quality on open-ended reasoning duties.
Key Specs
- Structure: Extremely-sparse MoE (309B whole, 15B energetic)
- Complete parameters: ~309B
- Lively parameters: ~15B per token (20:1 sparsity)
- Context size: 128K tokens
- License: Open-weight, business use permitted
- Inference velocity: ~150 tokens/second
- Main use instances: Mathematical competitions, coding challenges, cost-sensitive deployments
Strengths
- Distinctive effectivity with 15B energetic parameters delivering robust math and coding efficiency
- Excellent price profile at 2.5% of Claude’s inference price
- Quick inference at 150 t/s allows real-time purposes
- Sturdy mathematical reasoning with 94.1% AIME 2025 rating
- Latest launch represents cutting-edge MoE effectivity methods
Weaknesses
- Instruction-following might be inconsistent on general-purpose duties
- Efficiency is strongest inside math and coding domains, much less dependable on various workloads
- Restricted ecosystem maturity with sparse neighborhood tooling and documentation
- Greatest suited to slim, well-defined use instances slightly than basic reasoning brokers
10. Ministral 14B Reasoning
Mistral AI’s Ministral 14B Reasoning represents a breakthrough in compact reasoning fashions. With solely 14 billion parameters, it achieves reasoning efficiency that rivals fashions 5-10× its measurement, making it essentially the most environment friendly mannequin on this top-10 listing. Ministral 14B is a part of the broader Mistral 3 household and inherits architectural improvements from Mistral Giant 3 whereas optimizing for deployment in resource-constrained environments.
The mannequin employs a dense transformer structure with specialised reasoning coaching. In contrast to bigger MoE fashions, Ministral achieves its effectivity by cautious dataset curation and reinforcement studying centered particularly on mathematical and logical reasoning duties. This focused strategy permits it to punch nicely above its weight class on reasoning benchmarks.
Remarkably, Ministral 14B achieves roughly 85% accuracy on AIME 2025, a number one end result for any mannequin beneath 30B parameters and aggressive with fashions a number of instances bigger. It additionally scores 68.2% on GPQA Diamond and 82.7% on MATH-500, demonstrating broad reasoning functionality throughout totally different downside sorts. On coding benchmarks, it achieves 78.5% on HumanEval, making it appropriate for AI-assisted growth workflows.
The mannequin’s small measurement allows deployment situations not possible for bigger fashions. It might probably run successfully on a single shopper GPU (RTX 4090, A6000) with 24GB VRAM, and even on high-end laptops with quantization. Inference speeds attain 40-60 tokens per second on shopper {hardware}, making it sensible for real-time interactive purposes. This accessibility opens reasoning-first AI to a much wider vary of builders and use instances.
Key Specs
- Structure: Dense transformer with reasoning-optimized coaching
- Complete parameters: ~14B
- Lively parameters: ~14B (dense)
- Context size: 128K tokens
- License: Apache-2.0
- Main use instances: Edge reasoning, native growth, resource-constrained environments, real-time interactive AI
Strengths
- Distinctive reasoning efficiency relative to mannequin measurement (~85% AIME 2025 at 14B)
- Runs on shopper {hardware} (single RTX 4090 or related) with robust efficiency
- Quick inference speeds (40-60 t/s) allow real-time interactive purposes
- Decrease operational prices make reasoning AI accessible to smaller groups and particular person builders
- Apache-2.0 license with minimal deployment obstacles
Weaknesses
- Decrease absolute ceiling than 100B+ fashions on essentially the most troublesome reasoning duties
- Restricted context window (128K) in comparison with million-token fashions
- Dense structure means no parameter effectivity beneficial properties from sparsity
- Might battle with extraordinarily lengthy reasoning chains that require sustained computation
- Smaller mannequin capability limits multilingual and multimodal capabilities
Mannequin Comparability Abstract
|
Mannequin |
Structure |
Params (Complete / Lively) |
Context Size |
License |
Notable Strengths |
|
GPT-OSS-120B |
Sparse / MoE-style |
~117B / ~5.1B |
~128K |
Apache-2.0 |
Environment friendly GPT-level reasoning; single-GPU feasibility; agent-friendly |
|
GLM-4.7 (Zhipu AI) |
MoE Transformer |
~355B / ~32B |
~200K enter / 128K output |
MIT |
Sturdy open coding + math reasoning; built-in instrument & agent APIs |
|
Kimi K2 Pondering (Moonshot AI) |
MoE (≈384 specialists) |
~1T / ~32B |
256K (as much as 1M through Yarn) |
Apache-2.0 |
Distinctive deep reasoning and long-horizon instrument use; INT4 effectivity |
|
MiniMax-M2.1 |
MoE (agent-optimized) |
~230B / ~10B |
Lengthy (not publicly specified) |
MIT |
Engineered for agentic workflows; robust long-horizon reasoning |
|
DeepSeek-R1 (distilled) |
Dense Transformer (distilled) |
8B / 8B |
128K |
MIT |
Matches 235B fashions on reasoning; runs on single GPU; 87.5% AIME 2025 |
|
DeepSeek-V3.2 (Terminus) |
MoE + Sparse Consideration |
~671B / ~37B |
As much as ~1M (sparse) |
MIT |
State-of-the-art open agentic reasoning; long-context effectivity |
|
Qwen3-Subsequent-80B-Pondering |
Hybrid MoE + hybrid consideration |
80B / ~3B |
~262K native |
Apache-2.0 |
Extraordinarily compute-efficient reasoning; robust math & coding |
|
Qwen3-235B-A22B |
Hybrid MoE + dual-mode |
~235B / ~22B |
~262K native |
Apache-2.0 |
Distinctive math reasoning (89.2% AIME); dual-mode flexibility |
|
Ministral 14B Reasoning |
Dense Transformer |
~14B / ~14B |
128K |
Apache-2.0 |
Greatest-in-class effectivity; 85% AIME at 14B; runs on shopper GPUs |
|
MiMo-V2-Flash |
Extremely-sparse MoE |
~309B / ~15B |
128K |
MIT |
Extremely-efficient (2.5% Claude price); 150 t/s; 94.1% AIME 2025 |
Conclusion
Open-source reasoning fashions have superior shortly, however working them effectively stays an actual problem. Agentic and reasoning workloads are essentially token-intensive. They contain lengthy contexts, multi-step planning, repeated instrument calls, and iterative execution. In consequence, they burn by tokens quickly and turn into costly and sluggish when run on normal inference setups.
The Clarifai Reasoning Engine is constructed particularly to deal with this downside. It’s optimized for agentic and reasoning workloads, utilizing optimized kernels and adaptive methods that enhance throughput and latency over time with out compromising accuracy. Mixed with Compute Orchestration, Clarifai dynamically manages how these workloads run throughout GPUs, enabling excessive throughput, low latency, and predictable prices whilst reasoning depth will increase.
These optimizations are mirrored in actual benchmarks. In evaluations printed by Synthetic Evaluation on GPT-OSS-120B, Clarifai achieved industry-leading outcomes, exceeding 500 tokens per second with a time to first token of round 0.3 seconds. The outcomes spotlight how execution and orchestration selections straight impression the viability of huge reasoning fashions in manufacturing.
In parallel, the platform continues so as to add and replace help for high open-source reasoning fashions within the neighborhood. You can strive these fashions straight within the Playground or entry them by the API and combine them into their very own purposes. The identical infrastructure additionally helps deploying customized or self-hosted fashions, making it simple to guage, evaluate, and run reasoning workloads beneath constant circumstances.
As reasoning fashions proceed to evolve in 2026, the flexibility to run them effectively and affordably would be the actual differentiator.