

{kind=link}
The rise of highly effective massive language fashions (LLMs) that may be consumed through API calls has made it remarkably simple to combine synthetic intelligence (AI) capabilities into purposes. But regardless of this comfort, a major variety of enterprises are selecting to self-host their very own fashions—accepting the complexity of infrastructure administration, the price of GPUs within the serving stack, and the problem of protecting fashions up to date. The choice to self-host typically comes down to 2 crucial components that APIs can’t tackle. First, there may be knowledge sovereignty: the necessity to make it possible for delicate data doesn’t depart the infrastructure, whether or not resulting from regulatory necessities, aggressive issues, or contractual obligations with prospects. Second, there may be mannequin customization: the power to fantastic tune fashions on proprietary knowledge units for industry-specific terminology and workflows or create specialised capabilities that general-purpose APIs can’t supply.
Amazon SageMaker AI addresses the infrastructure complexity of self-hosting by abstracting away the operational burden. By means of managed endpoints, SageMaker AI handles the provisioning, scaling, and monitoring of GPU assets, permitting groups to deal with mannequin efficiency moderately than infrastructure administration. The system gives inference-optimized containers with common frameworks like vLLM pre-configured for max throughput and minimal latency. As an example, the Giant Mannequin Inference (LMI) v16 container picture makes use of vLLM v0.10.2, which makes use of the V1 engine and comes with assist for brand new mannequin architectures and new {hardware}, such because the Blackwell/SM100 technology. This managed strategy transforms what usually requires devoted machine studying operations (MLOps) experience right into a deployment course of that takes only a few strains of code.
Reaching optimum efficiency with these managed containers nonetheless requires cautious configuration. Parameters like tensor parallelism diploma, batch dimension, most sequence size, and concurrency limits can dramatically impression each latency and throughput—and discovering the correct steadiness to your particular workload and value constraints is an iterative course of that may be time-consuming.
BentoML’s LLM-Optimizer addresses this problem by enabling systematic benchmarking throughout totally different parameter configurations, changing handbook trial-and-error with an automatic search course of. The instrument means that you can outline constraints resembling particular latency targets or throughput necessities, making it simple to establish configurations that meet your service degree targets. You should use LLM-Optimizer to search out optimum serving parameters for vLLM regionally or in your improvement atmosphere, apply those self same configurations on to the SageMaker AI endpoint for a seamless transition to manufacturing. This put up illustrates this course of by discovering an optimum deployment for a Qwen-3-4B mannequin on an Amazon SageMaker AI endpoint.
This put up is written for practising ML engineers, options architects, and system builders who already deploy fashions on Amazon SageMaker or related infrastructure. We assume familiarity with GPU cases, endpoints, and mannequin serving, and deal with sensible efficiency optimization. The reasons of inference metrics are included not as a newbie tutorial, however to construct shared instinct. For particular parameters like batch dimension & tensor parallelism, and the way they straight impression price and latency in manufacturing.
Resolution overview
The step-by-step breakdown is as follows:
- Outline constraints in Jupyter Pocket book: The method begins inside SageMaker AI Studio, the place customers open a Jupyter Pocket book to outline the deployment objectives and constraints of the use case. These constraints can embody goal latency, desired throughput, and output tokens.
- Run theoretical and empirical benchmarks with the BentoML LLM-Optimizer: The LLM-Optimizer first runs a theoretical GPU efficiency estimate to establish possible configurations for the chosen {hardware} (on this instance, an
ml.g6.12xlarge). It executes benchmark assessments utilizing the vLLM serving engine throughout a number of parameter combos resembling tensor parallelism, batch dimension, and sequence size to empirically measure latency and throughput. Based mostly on these benchmarks, the optimizer routinely determines probably the most environment friendly serving configuration that satisfies the offered constraints. - Generate and deploy optimized configuration in a SageMaker endpoint: As soon as the benchmarking is full, the optimizer returns a JSON configuration file containing the optimum parameter values. This JSON is handed from the Jupyter Pocket book to the SageMaker Endpoint configuration, which deploys the LLM (on this instance, the
Qwen/Qwen3-4Bmannequin utilizing the vLLM-based LMI container) in a managed HTTP endpoint utilizing the optimum runtime parameters.
The next determine is an summary of the workflow performed all through the put up.
Earlier than leaping into the theoretical underpinnings of inference optimization, it’s value grounding why these ideas matter within the context of real-world deployments. When groups transfer from API-based fashions to self-hosted endpoints, they inherit the accountability for tuning efficiency parameters that straight have an effect on price and person expertise. Understanding how latency and throughput work together by means of the lens of GPU structure and arithmetic depth allows engineers to make these trade-offs intentionally moderately than by trial and error.
Temporary overview of LLM efficiency
Earlier than diving into the sensible utility of this workflow, we cowl key ideas that construct instinct for why inference optimization is crucial for LLM-powered purposes. The next primer isn’t tutorial; it’s to offer the psychological mannequin wanted to interpret LLM-Optimizer’s outputs and perceive why sure configurations yield higher outcomes.
Key efficiency metrics
Throughput (requests/second): What number of requests your system completes per second. Increased throughput means serving extra customers concurrently.
Latency (seconds): The whole time from when a request arrives till the whole response is returned. Decrease latency means quicker person expertise.
Arithmetic depth: The ratio of computation carried out to knowledge moved. This determines whether or not your workload is:
Reminiscence-bound: Restricted by how briskly you’ll be able to transfer knowledge (low arithmetic depth)
Compute-bound: Restricted by uncooked GPU processing energy (excessive arithmetic depth)
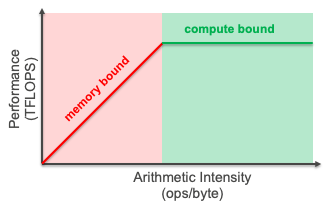
The roofline mannequin
The roofline mannequin visualizes efficiency by plotting throughput towards arithmetic depth. For deeper content material on the roofline mannequin, go to the AWS Neuron Batching documentation. The mannequin reveals whether or not your utility is bottlenecked by reminiscence bandwidth or computational capability. For LLM inference, this mannequin helps establish in the event you’re restricted by:
- Reminiscence bandwidth: Information switch between GPU reminiscence and compute items (typical for small batch sizes)
- Compute capability: Uncooked floating-point operations (FLOPS) accessible on the GPU (typical for giant batch sizes)
The throughput-latency trade-off
In follow, optimizing LLM inference follows a basic trade-off: as you enhance throughput, latency rises. This occurs as a result of:
- Bigger batch sizes → Extra requests processed collectively → Increased throughput
- Extra concurrent requests → Longer queue wait instances → Increased latency
- Tensor parallelism → Distributes mannequin throughout GPUs → Impacts each metrics in another way
The problem lies to find the optimum configuration throughout a number of interdependent parameters:
- Tensor parallelism diploma (what number of GPUs to make use of)
- Batch dimension (most variety of tokens processed collectively)
- Concurrency limits (most variety of simultaneous requests)
- KV cache allocation (reminiscence for consideration states)
Every parameter impacts throughput and latency in another way whereas respecting {hardware} constraints like GPU reminiscence and compute bandwidth. This multi-dimensional optimization drawback is exactly why LLM-Optimizer is efficacious—it systematically explores the configuration house moderately than counting on handbook trial-and-error.

For an summary on LLM Inference as a complete, BentoML has offered helpful assets of their LLM Inference Handbook.
Sensible utility: Discovering an optimum deployment of Qwen3-4B on Amazon SageMaker AI
Within the following sections, we stroll by means of a hands-on instance of figuring out and making use of optimum serving configurations for LLM deployment. Particularly, we:
- Deploy the
Qwen/Qwen3-4Bmannequin utilizing vLLM on anml.g6.12xlargeoccasion (4x NVIDIA L4 GPUs, 24GB VRAM every). - Outline reasonable workload constraints:
- Goal: 10 requests per second (RPS)
- Enter size: 1,024 tokens
- Output size: 512 tokens
- Discover a number of serving parameter combos:
- Tensor parallelism diploma (1, 2, or 4 GPUs)
- Max batched tokens (4K, 8K, 16K)
- Concurrency ranges (32, 64, 128)
- Analyze outcomes utilizing:
- Theoretical GPU reminiscence calculations
- Benchmarking knowledge
- Throughput vs. latency trade-offs
By the tip, you’ll see how theoretical evaluation, empirical benchmarking, and managed endpoint deployment come collectively to ship a production-ready LLM setup that balances latency, throughput, and value.
Conditions
The next are the conditions wanted to run by means of this instance:
- Entry to SageMaker Studio. This makes deployment & inference simple, or an interactive improvement atmosphere (IDE) resembling PyCharm or Visible Studio Code.
- To benchmark and deploy the mannequin, verify that the really helpful occasion sorts are accessible, primarily based on the mannequin dimension. To confirm the required service quotas, full the next steps:
- On the Service Quotas console, below AWS Companies, choose Amazon SageMaker.
- Confirm ample quota for the required occasion kind for “endpoint deployment” (within the right area).
- If wanted, request a quota enhance/contact AWS for assist.
The next code particulars set up the required packages:
Run the LLM-Optimizer
To get began, instance constraints have to be outlined primarily based on the focused workflow.
Instance constraints:
- Enter tokens: 1024
- Output tokens: 512
- E2E Latency: <= 60 seconds
- Throughput: >= 5 RPS
Run the estimate
Step one with llm-optimizer is to run an estimation. Operating an estimate analyzes the Qwen/Qwen3-4b mannequin on 4x L4 GPUs and estimate the efficiency for an enter size of 1024 tokens, and an output of 512 tokens. As soon as run, the theoretical bests for latency and throughput are calculated mathematically and returned. The roofline evaluation returned identifies the workloads bottlenecks, and a variety of server and consumer arguments are returned, to be used within the following step, working the precise benchmark.
Beneath the hood, LLM-Optimizer performs roofline evaluation to estimate LLM serving efficiency. It begins by fetching the mannequin structure from HuggingFace to extract parameters like hidden dimensions, variety of layers, consideration heads, and complete parameters. Utilizing these architectural particulars, it calculates the theoretical FLOPs required for each prefill (processing enter tokens) and decode (producing output tokens) phases, accounting for consideration operations, MLP layers, and KV cache entry patterns. It compares the arithmetic depth (FLOPs per byte moved) of every section towards the GPU’s {hardware} traits—particularly the ratio of compute capability (TFLOPs) to reminiscence bandwidth (TB/s)—to find out whether or not prefill and decode are memory-bound or compute-bound. From this evaluation, the instrument estimates TTFT (time-to-first-token), ITL (inter-token latency), and end-to-end latency at numerous concurrency ranges. It additionally calculates three theoretical concurrency limits: KV cache reminiscence capability, prefill compute capability, and decode throughput capability. Lastly, it generates tuning instructions that sweep throughout totally different tensor parallelism configurations, batch sizes, and concurrency ranges for empirical benchmarking to validate the theoretical predictions.
The next code particulars run an preliminary estimation primarily based on the chosen constraints:
Anticipated output:
Run the benchmark
With the estimation outputs in hand, an knowledgeable choice may be made on what parameters to make use of for benchmarking primarily based on the beforehand outlined constraints. Beneath the hood, LLM-Optimizer transitions from theoretical estimation to empirical validation by launching a distributed benchmarking loop that evaluates real-world serving efficiency on the goal {hardware}. For every permutation of server and consumer arguments, the instrument routinely spins up a vLLM occasion with the required tensor parallelism, batch dimension, and token limits, then drives load utilizing an artificial or dataset-based request generator (e.g., ShareGPT). Every run captures low-level metrics—time-to-first-token (TTFT), inter-token latency (ITL), end-to-end latency, tokens per second, and GPU reminiscence utilization—throughout concurrent request patterns. These measurements are aggregated right into a Pareto frontier, permitting LLM-Optimizer to establish configurations that finest steadiness latency and throughput throughout the person’s constraints. In essence, this step grounds the sooner theoretical roofline evaluation in actual efficiency knowledge, producing reproducible metrics that straight inform deployment tuning.
The next code runs the benchmark, utilizing data from the estimate:
This outputs the next permutations to the vLLM engine for testing. The next are easy calculations on the totally different combos of consumer & server arguments that the benchmark runs:
- 3
tensor_parallel_sizex 3max_num_batched_tokenssettings = 9 - 3
max_concurrencyx 1num prompts= 3 - 9 * 3 = 27 totally different assessments
As soon as accomplished, three artifacts are generated:
- An HTML file containing a Pareto dashboard of the outcomes: An interactive visualization that highlights the trade-offs between latency and throughput throughout the examined configurations.
- A JSON file summarizing the benchmark outcomes: This compact output aggregates the important thing efficiency metrics (e.g., latency, throughput, GPU utilization) for every take a look at permutation and is used for programmatic evaluation or downstream automation.
- A JSONL file containing the total report of particular person benchmark runs: Every line represents a single take a look at configuration with detailed metadata, enabling fine-grained inspection, filtering, or customized plotting.
Instance benchmark report output:
Unpacking the benchmark outcomes, we will use the metrics p99 e2e latency and request throughput at numerous ranges of concurrency to make an knowledgeable choice. The benchmark outcomes revealed that tensor parallelism of 4 throughout the accessible GPUs constantly outperformed decrease parallelism settings, with the optimum configuration being tensor_parallel_size=4, max_num_batched_tokens=8192, and max_concurrency=128, attaining 7.51 requests/second and a couple of,270 enter tokens/second—a 2.7x throughput enchancment over the naive single-GPU baseline (2.74 req/s).Whereas this configuration delivered peak throughput, it got here with elevated p99 end-to-end latency of 61.4 seconds below heavy load; for latency-sensitive workloads, the candy spot was tensor_parallel_size=4 with max_num_batched_tokens=4096 at reasonable concurrency (32), which maintained sub-24-second p99 latency whereas nonetheless delivering 5.63 req/s—greater than double the baseline throughput. The information demonstrates that shifting from a naive single-GPU setup to optimized 4-way tensor parallelism with tuned batch sizes can unlock substantial efficiency positive aspects, with the particular configuration selection relying on whether or not the deployment prioritizes most throughput or latency assurances.
To visualise the outcomes, LLM-Optimizer gives a handy perform to view the outputs plotted in a Pareto dashboard. The Pareto dashboard may be displayed with the next line of code:
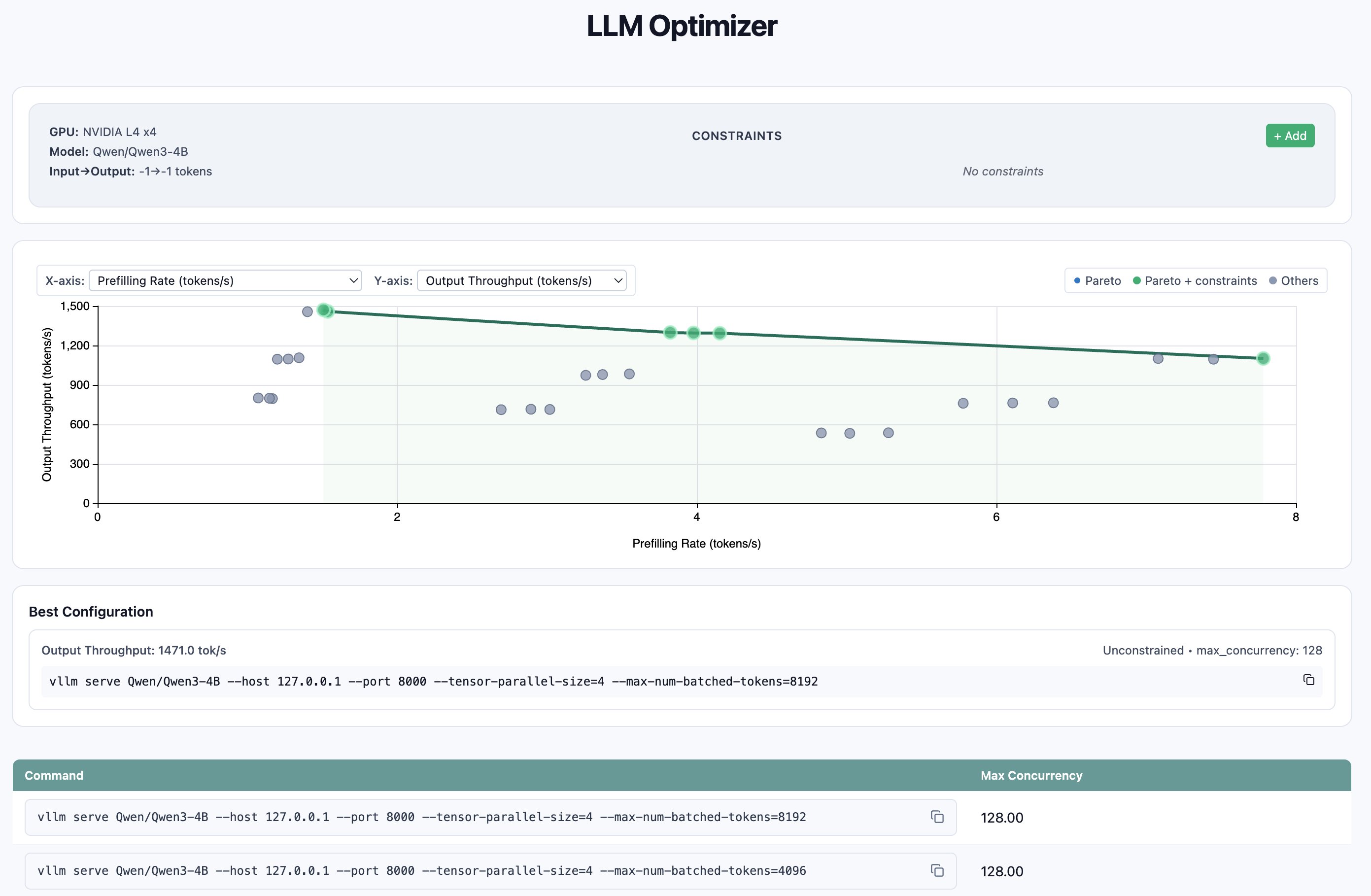
With the proper artifacts now in hand, the mannequin with the proper configurations may be deployed.
Deploying to Amazon SageMaker AI
With the optimum serving parameters recognized by means of LLM-Optimizer, the ultimate step is to deploy the tuned mannequin into manufacturing. Amazon SageMaker AI gives a great atmosphere for this transition, abstracting away the infrastructure complexity of distributed GPU internet hosting whereas preserving fine-grained management over inference parameters. Through the use of LMI containers, builders can deploy open-source frameworks like vLLM at scale, with out managing CUDA dependencies, GPU scheduling, or load balancing manually.
SageMaker AI LMI containers are high-performance Docker pictures particularly designed for LLM inference. These containers combine natively with frameworks resembling vLLM and TensorRT, and supply built-in assist for multi-GPU tensor parallelism, steady batching, streaming token technology, and different optimizations crucial to low-latency serving. The LMI v16 container used on this instance contains vLLM v0.10.2 and the V1 engine, supporting new mannequin architectures and enhancing each latency and throughput in comparison with earlier variations.
Now that the very best quantitative values for inference serving have been decided, these configurations may be handed on to the container as atmosphere variables. (please refer right here for in-depth steering):
When these atmosphere variables are utilized, SageMaker routinely injects them into the container’s runtime configuration layer, which initializes the vLLM engine with the specified arguments. Throughout startup, the container downloads the mannequin weights from Hugging Face, configures the GPU topology for tensor parallel execution throughout the accessible gadgets (on this case, on the ml.g6.12xlarge occasion), and registers the mannequin with the SageMaker Endpoint Runtime. This makes positive that the mannequin runs with the identical optimized settings validated by LLM-Optimizer, bridging the hole between experimentation and manufacturing deployment.
The next code demonstrates bundle and deploy the mannequin for real-time inference on SageMaker AI:
As soon as the mannequin assemble is created, you’ll be able to create and activate the endpoint:
After deployment, the endpoint is able to deal with stay visitors and may be invoked straight for inference:
These code snippets show the deployment movement conceptually. For an entire end-to-end pattern on deploying an LMI container for actual time inference on SageMaker AI, seek advice from this instance.
Conclusion
The journey from mannequin choice to manufacturing deployment not must depend on trial and error. By combining BentoML’s LLM-Optimizer with Amazon SageMaker AI, organizations can now transfer from speculation to deployment by means of a data-driven, automated optimization loop. This workflow replaces handbook parameter tuning with a repeatable course of that quantifies efficiency trade-offs, aligns with business-level latency and throughput targets, and deploys the very best configuration straight right into a managed inference atmosphere. This workflow addresses a crucial problem in manufacturing LLM deployment: with out systematic optimization, groups face an costly guessing sport between over-provisioning GPU assets and risking degraded person expertise. As demonstrated on this walkthrough, the efficiency variations are substantial—misconfigured setups can require 2-4x extra GPUs whereas delivering 2-3x greater latency. What might historically take an engineer days or perhaps weeks of handbook trial-and-error testing turns into just a few hours of automated benchmarking. By combining LLM-Optimizer’s clever configuration search with SageMaker AI’s managed infrastructure, groups could make data-driven deployment selections that straight impression each cloud prices and person satisfaction, focusing their efforts on constructing differentiated AI experiences moderately than tuning inference parameters.
The mixture of automated benchmarking and managed large-model deployment represents a major step ahead in making enterprise AI each accessible and economically environment friendly. By leveraging LLM-Optimizer for clever configuration search and SageMaker AI for scalable, fault-tolerant internet hosting, groups can deal with constructing differentiated AI experiences moderately than managing infrastructure or tuning inference stacks manually. In the end, the very best LLM configuration isn’t simply the one which runs quickest—it’s the one which meets particular latency, throughput, and value objectives in manufacturing. With BentoML’s LLM-Optimizer and Amazon SageMaker AI, that steadiness may be found systematically, reproduced constantly, and deployed confidently.
Extra assets
In regards to the authors
 Josh Longenecker is a Generative AI/ML Specialist Options Architect at AWS, partnering with prospects to architect and deploy cutting-edge AI/ML options. He’s a part of the Neuron Information Science Knowledgeable TFC and obsessed with pushing boundaries within the quickly evolving AI panorama. Exterior of labor, you’ll discover him on the health club, open air, or having fun with time together with his household.
Josh Longenecker is a Generative AI/ML Specialist Options Architect at AWS, partnering with prospects to architect and deploy cutting-edge AI/ML options. He’s a part of the Neuron Information Science Knowledgeable TFC and obsessed with pushing boundaries within the quickly evolving AI panorama. Exterior of labor, you’ll discover him on the health club, open air, or having fun with time together with his household.
 Mohammad Tahsin is a Generative AI/ML Specialist Options Architect at AWS, the place he works with prospects to design, optimize, and deploy trendy AI/ML options. He’s obsessed with steady studying and staying on the frontier of latest capabilities within the area. In his free time, he enjoys gaming, digital artwork, and cooking.
Mohammad Tahsin is a Generative AI/ML Specialist Options Architect at AWS, the place he works with prospects to design, optimize, and deploy trendy AI/ML options. He’s obsessed with steady studying and staying on the frontier of latest capabilities within the area. In his free time, he enjoys gaming, digital artwork, and cooking.