

{kind=link}
Correlated subqueries may cause efficiency challenges in Amazon Aurora PostgreSQL-Appropriate Version, usually inflicting functions to expertise decreased efficiency as knowledge volumes develop. On this publish, we discover the superior optimization configurations obtainable in Aurora PostgreSQL that may remodel these efficiency challenges into environment friendly operations with out requiring you to switch a single line of SQL code. The configurations we’re going to discover are the subquery transformation and the subquery cache optimizations.
Should you’re experiencing efficiency impacts attributable to correlated subqueries or planning a database migration the place rewriting a question utilizing correlated subquery to a unique kind isn’t possible, the optimization capabilities of Aurora PostgreSQL may ship the efficiency enchancment you want.
Understanding correlated subqueries
A correlated subquery is a nested question that references columns from its outer question, making a dependency that requires the interior question to execute as soon as for every row processed of the outer question. This relationship is what makes them each highly effective and probably problematic for efficiency.
Anatomy of a correlated subquery
The next diagram reveals a correlated subquery that finds the utmost order quantity for every buyer by trying up their orders in a separate desk. For every buyer row in the primary question, the subquery executes as soon as to search out that particular buyer’s highest order whole utilizing the matching customer_id from the orders desk.
Key parts:
- Outer question: Processes the primary dataset (prospects desk)
- Internal question: The subquery that depends upon outer question values
- Correlation situation:
o.customer_id = c.customer_idhyperlinks the queries - Correlated column:
c.customer_idfrom the outer question used within the interior question
The efficiency problem
Conventional execution of correlated subqueries follows this sample:
- Fetch one row from the outer question
- Execute the subquery with correlated values fetched from step 1
- Return the subquery outcome
- Repeat for the subsequent outer row
For 10,000 prospects with 500 orders every, this might suggest 10,000 separate subquery executions, leading to sub-optimal efficiency for the question.
Aurora PostgreSQL gives two highly effective strategies to beat the efficiency challenges of correlated subqueries: subquery transformation optimization and subquery cache optimization.
Subquery transformation
The subquery transformation optimization mechanically converts correlated subqueries into environment friendly join-based execution plans. As a substitute of working the identical subquery repeatedly for every row in your outer desk, this optimization runs the subquery simply as soon as and shops the leads to a hash lookup desk. The outer question then merely seems to be up the solutions it wants from the hash desk, which is way sooner than recalculating the identical factor repeatedly.
The subquery transformation function delivers the best discount in question execution time in a number of key eventualities. When your outer question is predicted to return massive outcome units of greater than 1,000 rows, the transformation can considerably enhance efficiency. The function excels with costly subqueries that embrace aggregations, advanced joins, and sorting operations throughout the subquery itself. It proves significantly helpful when indexes are lacking on correlation columns, as a result of the transformation eliminates the necessity for these indexes. Migration eventualities the place rewriting queries isn’t possible signify one other ultimate use case; you should utilize subquery transformation to enhance efficiency with out modifying current SQL code. A best-case situation for the subquery transformation optimization happens when the desk is massive and has lacking indexes and the subquery outcome makes use of aggregation features.
Tips on how to allow subquery transformation
Aurora PostgreSQL can mechanically remodel eligible correlated subqueries into environment friendly be a part of operations. This may be enabled at both the session or parameter group degree.
Limitations and scope
The transformation applies solely when the next circumstances are met:
- Correlated columns seem solely within the subquery
WHEREclause - Subquery
WHEREcircumstances useANDoperators solely - The subquery should return a scalar worth utilizing combination features like:
MAX,MIN,AVG,COUNT, orSUM. - No
LIMIT,OFFSET, orORDER BYoperators might be current within the subquery - There are not any indexes current on the outer question or subquery be a part of columns
The next are examples of queries that may not be optimized by subquery transformation based mostly on these limitations:
A correlated discipline in a SELECT clause:
OR circumstances in a WHERE clause:
A LIMIT within the subquery:
The subquery cache
The subquery cache optimization shops and reuses subquery outcomes for repeated correlation values, decreasing computational overhead and bettering efficiency when the identical subquery circumstances are evaluated a number of occasions. The perfect situation for enabling the subquery cache is when you might have excessive correlation worth repetition (many rows with the identical attributes), costly subquery computations, queries ineligible for plan remodel, and when the cached result’s finite. An ideal instance situation happens when the subquery situation is just too sophisticated, so the subquery remodel received’t work for the question, and the cache hit price is greater than 30%, which signifies there are repeated rows within the outer desk.
The subquery cache optimization provides a PostgreSQL Memoize node, a caching layer between a nested loop and its interior subquery, storing outcomes to keep away from redundant computations. As a substitute of executing the subquery for each buyer row, the Memoize node:
- Caches outcomes based mostly on the
customer_id(cache key). - Reuses cached outcomes when the identical
customer_idseems once more. - Reduces redundant computations by storing beforehand calculated max (
total_amount) values.
Tips on how to allow subquery caching
Subquery caching enhances transformation by storing and reusing subquery outcomes. It may be enabled in two methods.
You may allow subquery caching on the session degree:
You may as well allow in your cluster parameter group, utilizing the next dynamic parameter:
Lastly, you may examine the change has been utilized:
Limitations and scope
The next are subquery varieties which can be can be utilized within the subquery cache:
- Scalar subqueries with correlation
- Deterministic features solely
- Hashable correlation column varieties
The operators IN, ANY, ALL can’t be used with statements within the subquery cache.
When to make use of subquery remodel or subquery cache
The subquery cache might be enabled independently of subquery transformation, which suggests you should utilize subquery caching as a standalone efficiency enhancement or together with subquery transformation for max optimization. Use subquery transformation by itself when you might have massive datasets with minimal repeated values and your subqueries meet the strict necessities, as a result of it might probably considerably cut back execution time by changing nested loops into environment friendly joins. Use the subquery cache when your queries have advanced circumstances that forestall transformation however include many repeated correlation values, permitting the cache to retailer and reuse outcomes even when transformation isn’t doable.
The place subqueries meet the necessities for each subquery transformation and caching due to repeated correlation values, then you’ll get most profit by utilizing each optimizations:
In such circumstances, the optimizer will do the remodel first and subsequently the subquery cache might be used to construct the question plan.
Subquery optimizations in motion
Let’s have a look at the best way to use these two optimizations in observe. For subquery transformation, we are going to measure affect in question execution time earlier than and after optimization. For subquery cache, we are going to measure affect in cache hit ratio (CHR).
Subquery transformation affect
To evaluate the affect of subquery transformation, we begin by producing take a look at knowledge. The next knowledge preparation SQL statements create two tables, the primary known as inner_table with three columns (id, a, and b) and populates it with 10,000 rows of knowledge the place column a cycles by values 1–100 and column b comprises random numbers. The code then fills the second outer_table with 50,000 rows break up between repeated values (1–100) and distinctive values (101–25100), adopted by gathering statistics on each tables.
An index isn’t wanted on this instance, as a result of correlated subquery transformation works finest with out indexes. It’s because subquery transformations can take away the necessity for indexes by changing a number of desk scans right into a single desk scan, decreasing question complexity and avoiding the storage overhead and Information Manipulation Language (DML) latency penalties related to sustaining indexes.
Earlier than enabling the transformation:
After enabling the transformation:
Sections indicating {that a} hash lookup desk is getting used as a substitute of repeated subquery executions for each row within the outer desk are highlighted in daring.
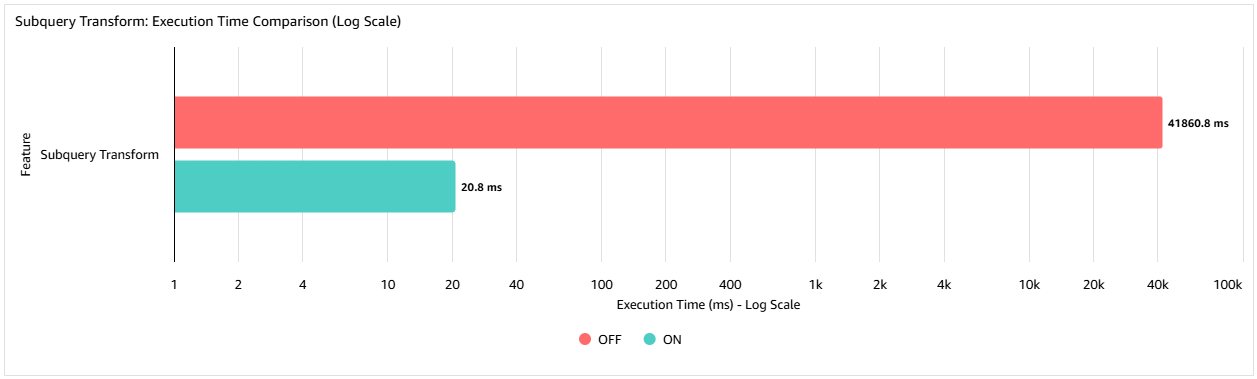
The next graph reveals the execution time (in milliseconds) in a take a look at case with an interior desk of 10,000 rows and an outer desk of 75,000 rows. By utilizing the subquery remodel, the question execution time is decreased by 99.95% in comparison with not utilizing the function, from 41seconds down to twenty.8 milliseconds. The proportion enchancment realized is data-dependent, however this instance demonstrates the dimensions of enchancment that may be achieved.
Subquery cache affect
Identical to reviewing the affect of subquery transformation, step one to evaluate the affect of utilizing a subquery cache is to generate take a look at knowledge. The next SQL code creates two tables (outer_table and inner_table) with similar buildings (id, a, bcolumns) and populates inner_table with 10,000 sequential rows whereas filling outer_table with 100,000 rows break up between repeated values (1–100) within the first half and distinctive values (101–50100) within the second half. The script concludes by updating the database statistics for each tables utilizing the ANALYZE command.
An index isn’t wanted as a result of when indexes are current and usable, particular person subquery executions would possibly already be quick sufficient that caching gives diminishing returns.
With out the subquery cache:
With the subquery cache:
Highlighted in daring are the cache hits and misses displaying a 49.9% CHR.
Understanding cache hit price
The Cache Hit Charge determines cache effectiveness and is calculated like the next:
From this output, we are able to decide our CHR within the previous instance to be 49.9%. Usually, for the subquery cache, a CHR above 70% is taken into account wonderful. A CHR price above 30% is nice, and under 30%, the cache might be disabled due to restricted profit.
It’s because—not like shared buffer CHRs, which may moderately attain 90% or extra as a result of the identical knowledge pages are regularly accessed—a 70% CHR for subquery cache displays practical knowledge distribution patterns the place solely a portion of customers have duplicate correlation values. A 50% CHR means half the shoppers within the outer question have duplicate values (comparable to repeat purchases), which represents regular enterprise eventualities, whereas anticipating 90% would suggest unrealistic knowledge patterns the place almost all customers have similar behaviours.
You may as well set parameters associated to the subquery cache to resolve whether or not the cache will get used. For every cached subquery, after the variety of cache misses outlined by apg_subquery_cache_check_interval is exceeded, the system evaluates whether or not caching that specific subquery is useful by evaluating the CHR towards the apg_subquery_cache_hit_rate_threshold. If the CHR falls under this threshold, the subquery is faraway from the cache. The next are the defaults for these parameters.
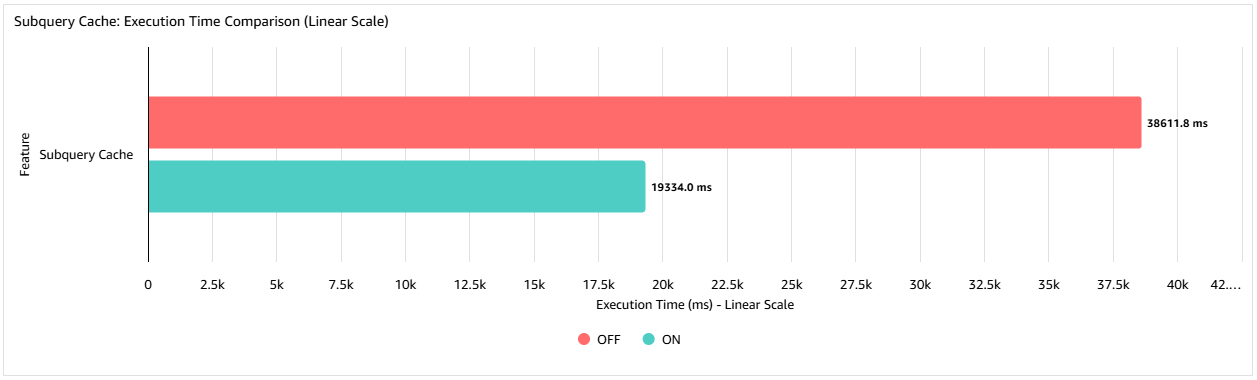
The next graph reveals that on this instance when utilizing the subquery cache the question execution time is decreased to 50% of its authentic execution time. The development you obtain will range from case to case. For instance, the effectiveness of the cache might be influenced by the variety of repeated rows within the outer question.
When to think about alternate options
Think about using the unique PostgreSQL plan when you might have wonderful indexes already current on correlation columns, queries execute sometimes, you might have a small dataset for the outer question, otherwise you’re coping with advanced subqueries with a number of correlation circumstances. Contemplate manually rewriting the question when the plan is just too advanced to remodel or when the cache hit price is lower than 30% within the subquery cache.
Conclusion
On this publish, you might have seen how the correlated subquery optimizations obtainable in Aurora PostgreSQL can considerably enhance efficiency by two complementary strategies: automated subquery transformations and clever subquery caching. These options work collectively to deal with gradual correlated queries with out requiring code rewrites. Subquery transformation optimizes queries behind the scenes for vital pace enhancements, whereas caching remembers outcomes from costly subqueries that repeatedly course of comparable knowledge patterns. You may implement these optimizations incrementally, monitor their results by Amazon CloudWatch, and take a look at safely utilizing the Amazon Aurora cloning and blue/inexperienced deployment options earlier than manufacturing rollout, decreasing the necessity to spend time rewriting advanced queries and permitting Aurora to mechanically deal with the efficiency optimization heavy lifting.
To get began implementing these optimizations in your individual atmosphere, see Optimizing correlated subqueries in Aurora PostgreSQL and dive deeper into efficiency evaluation strategies at this PostgreSQL web page about studying EXPLAIN plans.
In regards to the authors