Amazon Keyspaces now helps the pre-warming characteristic to give you proactive throughput administration. With pre-warming, you’ll be able to set minimal heat throughput values that your desk can deal with immediately, avoiding the chilly begin delays that happen throughout dynamic partition splits.
On this publish, we talk about the Amazon Keyspaces pre-warming characteristic capabilities and reveal the way it can improve your throughput efficiency. By an in depth examination of its core performance, sensible implementation patterns, and price evaluation, we present the right way to successfully put together your tables for product launches or gross sales occasions.
Amazon Keyspaces (for Apache Cassandra) can run your Apache Cassandra workloads on AWS utilizing a totally managed, serverless database service. You possibly can scale your Cassandra functions with just about limitless throughput and storage, whereas sustaining millisecond-level latency. Amazon Keyspaces robotically scales tables based mostly on workload calls for, with scaling conduct decided by the desk’s capability mode. Amazon Keyspaces presents two capability modes, on-demand and provisioned, designed to deal with fluctuating and predictable workloads, respectively. Nevertheless, though on-demand mode excels at automated scaling, it has a built-in delay when tables must deal with large site visitors spikes instantly upon creation or throughout sudden surges similar to product launches or gross sales occasions.
Understanding heat throughput
Heat throughput (achieved by pre-warming tables) defines the minimal learn and write operations your Amazon Keyspaces desk can deal with immediately with out requiring dynamic scaling. Measured in learn models per second and write models per second, it establishes a efficiency baseline slightly than a most restrict, with default values of 12,000 learn and 4,000 write models for on-demand tables, and matching your present provisioned capability for provisioned tables. Not like provisioned capability (which units billable throughput limits), heat throughput represents the capability your desk’s infrastructure can deal with instantly. You possibly can configure heat throughput as much as 40,000 models for each learn and write operations by default, with greater limits obtainable by way of AWS Help. This pre-warming course of works with each capability modes, permitting on-demand tables to scale from the next baseline and provisioned tables to scale as much as the nice and cozy throughput restrict with out experiencing delays.
How pre-warming works
Pre-warming in Amazon Keyspaces is an asynchronous course of that allows tables to deal with excessive throughput instantly upon creation or modification. While you create or replace a desk with pre-warming settings, Amazon Keyspaces configures the desk with the required throughput values. While you proactively pre-warm your desk, you’re primarily setting the variety of reads and writes your desk can instantaneously help, ensuring it could actually deal with a selected stage of site visitors proper from the beginning and your functions can obtain constant sub-millisecond response occasions for anticipated site visitors patterns. You possibly can monitor the pre-warming standing utilizing the GetTable API, which returns real-time details about the pre-warming course of together with the configured heat throughput values. Standing indicators similar to AVAILABLE or UPDATING enable you monitor when your desk is prepared for high-throughput operations.
For multi-Area deployments, pre-warming settings are robotically propagated to all AWS Areas, facilitating constant efficiency throughout all the desk replication group. When utilizing AddReplica so as to add a brand new Area to a keyspace that comprises pre-warmed tables, the identical configuration is utilized to tables within the newly added Area with out requiring further setup. The characteristic integrates with present AWS Identification and Entry Administration (IAM) permissions, utilizing customary actions like cassandra:Create, cassandra:Modify, and cassandra:Choose for desk administration, with out introducing new pre-warming particular permissions. Moreover, pre-warming works with each provisioned and on-demand capability modes, so you’ll be able to keep your most popular billing mannequin whereas gaining speedy high-throughput capabilities, with billing based mostly on a one-time cost mannequin for the distinction between requested heat throughput values and present heat throughput values. Pre-warming additionally integrates with Amazon CloudWatch to offer visibility into desk efficiency, serving to you monitor present Amazon Keyspaces metrics to confirm that your pre-warmed tables are dealing with the anticipated throughput.
Instance use case
For example the pre-warming use case, take into account a newly launched Web of Issues (IoT) service with 200,000 related sensors that retailer sensor readings in an Amazon Keyspaces desk configured in on-demand mode. In on-demand mode, the desk initially helps as much as 4,000 Write Capability Items (WCUs) and 12,000 Learn Capability Items (RCUs), and requests exceeding this capability will likely be throttled till the desk scales as much as meet the throughput necessities. When all 200,000 sensors come on-line concurrently and try to ship their sensor readings to the Amazon Keyspaces desk, the desk lacks the capability to deal with 200,000 write requests per second, inflicting requests to be throttled till the desk robotically scales as much as accommodate the workload. The next instance demonstrates this throttling conduct and the gradual scale-up course of.
Use the next script to run a simulated workload. The script generates roughly 200,000 write requests per second and can maintain retrying till all of the requests are full.
from cassandra.cluster import Cluster, ConsistencyLevel
from cassandra_sigv4.auth import SigV4AuthProvider
from ssl import SSLContext, PROTOCOL_TLS
import time
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor, as_completed
import threading
import json
# Configuration
KEYSPACE = 'iot_demo'
TABLE = 'sensor_readings_fresh'
DURATION_MINUTES = 15
TARGET_WRITES = 10000000 # Excessive quantity to make sure we run for full length
WORKERS = 500
BATCH_SIZE = 1000
# Metrics monitoring
metrics_lock = threading.Lock()
metrics = {
'consumed_writes': 0,
'throttled_writes': 0,
'total_attempts': 0,
'timeline': []
}
# Setup Keyspaces connection
ssl_context = SSLContext(PROTOCOL_TLS)
auth_provider = SigV4AuthProvider()
cluster = Cluster(
['cassandra.us-east-1.amazonaws.com'],
ssl_context=ssl_context,
auth_provider=auth_provider,
port=9142
)
session = cluster.join(KEYSPACE)
insert_stmt = session.put together(
f"INSERT INTO {TABLE} (sensor_id, reading_time, temperature, humidity) VALUES (?, ?, ?, ?)"
)
insert_stmt.consistency_level = ConsistencyLevel.LOCAL_QUORUM
def is_throttle_error(error_str):
"""Verify if error signifies throttling"""
throttle_indicators = ['throttl', 'overload', 'exceeded', 'unavailable', 'timeout']
return any(indicator in error_str.decrease() for indicator in throttle_indicators)
def write_with_retry(sensor_id):
"""Write with retry logic to deal with throttling"""
import random
import uuid
max_retries = 100
retry_count = 0
# Generate extremely randomized sensor_id to make sure even partition distribution
random_uuid = str(uuid.uuid4())[:8] # Use UUID for higher randomization
random_number = random.randint(1, 10000000) # Bigger vary
random_sensor_id = f"{random_uuid}_{random_number}"
whereas retry_count < max_retries:
strive:
session.execute(insert_stmt, (
random_sensor_id,
datetime.utcnow(),
20.0 + (random_number % 10),
50.0 + (random_number % 20)
))
with metrics_lock:
metrics['consumed_writes'] += 1
metrics['total_attempts'] += retry_count + 1
return {'success': True, 'retries': retry_count}
besides Exception as e:
retry_count += 1
with metrics_lock:
if is_throttle_error(str(e)):
metrics['throttled_writes'] += 1
metrics['total_attempts'] += 1
if retry_count < max_retries:
time.sleep(0.01) # Minimal backoff
return {'success': False, 'retries': max_retries}
def collect_metrics(start_time):
"""Acquire timeline metrics for evaluation"""
end_time = start_time + (DURATION_MINUTES * 60)
whereas True:
time.sleep(0.5)
current_time = time.time()
with metrics_lock:
elapsed = current_time - start_time
metrics['timeline'].append({
'timestamp': elapsed,
'consumed_writes': metrics['consumed_writes'],
'throttled_writes': metrics['throttled_writes'],
'total_attempts': metrics['total_attempts']
})
if current_time >= end_time:
break
print(f"n{'='*70}")
print(f"KEYSPACES 15-MINUTE PREWARMED BURST TEST")
print(f"{'='*70}n")
print(f"Desk: {KEYSPACE}.{TABLE}")
print(f"Period: {DURATION_MINUTES} minutes")
print(f"Staff: {WORKERS}")
print(f"Function: Reveal sustained excessive throughput with prewarmingn")
start_time = time.time()
end_time = start_time + (DURATION_MINUTES * 60)
# Begin metrics assortment
metrics_thread = threading.Thread(goal=collect_metrics, args=(start_time,))
metrics_thread.daemon = True
metrics_thread.begin()
accomplished = 0
failed_final = 0
total_retries = 0
batch_count = 0
whereas time.time() < end_time:
batch_start = batch_count * BATCH_SIZE
batch_end = batch_start + BATCH_SIZE
with ThreadPoolExecutor(max_workers=WORKERS) as executor:
futures = [executor.submit(write_with_retry, i)
for i in range(batch_start, batch_end)]
for future in as_completed(futures):
if time.time() >= end_time:
break
outcome = future.outcome()
accomplished += 1
if outcome['success']:
total_retries += outcome['retries']
else:
failed_final += 1
# Progress replace each 2000 writes
if accomplished % 2000 == 0:
elapsed = time.time() - start_time
remaining = (end_time - time.time()) / 60
with metrics_lock:
consumed = metrics['consumed_writes']
throttled = metrics['throttled_writes']
makes an attempt = metrics['total_attempts']
throttle_rate = throttled / max(1, makes an attempt) * 100
print(f" Progress: {accomplished:,} writes | "
f"Success: {consumed:,} | Throttled: {throttled:,} ({throttle_rate:.1f}%) | "
f"Charge: {consumed/elapsed:.1f}/sec | Remaining: {remaining:.1f}min")
batch_count += 1
time.sleep(2) # Permit metrics assortment to finish
elapsed = time.time() - start_time
print(f"n{'='*70}")
print(f"15-MINUTE PREWARMED BURST TEST RESULTS")
print(f"{'='*70}")
print(f"Period: {DURATION_MINUTES} minutes ({elapsed:.1f}s)")
print(f"Complete writes: {metrics['consumed_writes']:,}")
print(f"Profitable: {metrics['consumed_writes']:,} ({metrics['consumed_writes']/(metrics['consumed_writes']+failed_final)*100:.1f}%)")
print(f"Failed: {failed_final:,}")
print(f"Throttled makes an attempt: {metrics['throttled_writes']:,}")
print(f"Complete makes an attempt: {metrics['total_attempts']:,}")
print(f"Retry overhead: {(metrics['total_attempts']-metrics['consumed_writes'])/metrics['consumed_writes']*100:.1f}%")
print(f"Common price: {metrics['consumed_writes']/elapsed:.1f} writes/sec")
print(f"Peak capability used: {max(5000, metrics['consumed_writes']/elapsed):.0f} WCU/sec")
# Save metrics
metrics_file = f'prewarmed_15min_metrics_{int(start_time)}.json'
with open(metrics_file, 'w') as f:
json.dump({
'test_config': {
'duration_minutes': DURATION_MINUTES,
'employees': WORKERS,
'batch_size': BATCH_SIZE,
'desk': f'{KEYSPACE}.{TABLE}',
'warm_throughput': '40,000 WCU / 40,000 RCU'
},
'abstract': {
'duration_seconds': elapsed,
'total_writes': metrics['consumed_writes'],
'consumed_writes': metrics['consumed_writes'],
'throttled_writes': metrics['throttled_writes'],
'total_attempts': metrics['total_attempts'],
'failed_writes': failed_final,
'average_rate_per_sec': metrics['consumed_writes']/elapsed,
'retry_overhead_percent': (metrics['total_attempts']-metrics['consumed_writes'])/max(1,metrics['consumed_writes'])*100,
'throttle_percentage': metrics['throttled_writes']/max(1, metrics['total_attempts'])*100,
'success_rate': metrics['consumed_writes']/(metrics['consumed_writes']+failed_final)*100
},
'timeline': metrics['timeline']
}, f, indent=2)
print(f"nMetrics saved to: {metrics_file}")
print(f"Use this knowledge on your weblog publish about prewarming effectiveness")
print(f"{'='*70}n")
cluster.shutdown()
The next CloudWatch graphs present that with out pre-warming, throttling began when the desk reaches the preliminary 4,000 WRUs or when storage break up is required so as to add extra partitions.
Now, create the desk with pre-warming and run the identical load and observe the conduct to see if throttling happens:
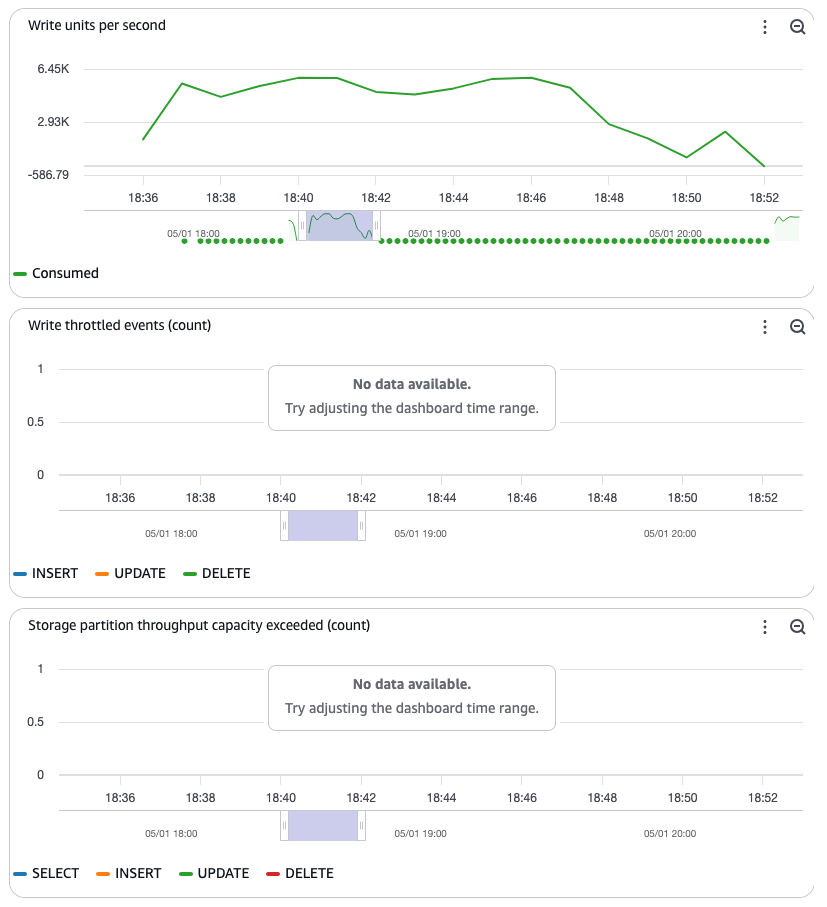
After the desk is created, Amazon Keyspaces creates the storage partitions and turns into able to serve the incoming site visitors with out throttling. The next CloudWatch graphs present you could help the incoming surge of site visitors with out points.
Pricing
The pricing for pre-warming relies on the price of provisioned WCUs and RCUs within the particular Area the place your desk is situated. While you pre-warm a desk, the associated fee is calculated as a one-time cost based mostly on the distinction between the brand new values and the present heat throughput that the desk or index can help.
By default, on-demand tables have a baseline heat throughput of 4,000 WCUs and 12,000 RCUs. When pre-warming a newly created on-demand desk, you’re solely charged for the distinction between your specified values and these baseline values. The IoT instance on this publish demonstrating pre-warning tables to 40,000 WCUs and 40,000 RCUs. This incurs a one-time cost that applies to the extra 36,000 (40,000 – 4,000) WCUs and 28,000 (40,000 – 12,000) RCUs wanted.
The pre-warming price calculation for us-east-1 are as follows:
By pre-warming tables, you mitigate operational danger and ensure your software can deal with the site visitors surge with out throttling, offering a clean buyer expertise throughout vital gross sales occasions.
Conclusion
Pre-warming gives a robust functionality in Amazon Keyspaces to organize your tables for speedy high-throughput workloads. Whether or not you’re orchestrating a serious product launch or gearing up for anticipated site visitors surges, Use pre-warming to organize your tables with the required capability from the beginning, lowering throttling and delivering constant, sub-millisecond efficiency your functions demand.


{kind=link}