

{kind=link}
In the present day, we’re saying two new AI mannequin coaching options inside Amazon SageMaker HyperPod: checkpointless coaching, an method that mitigates the necessity for conventional checkpoint-based restoration by enabling peer-to-peer state restoration, and elastic coaching, enabling AI workloads to routinely scale primarily based on useful resource availability.
- Checkpointless coaching – Checkpointless coaching eliminates disruptive checkpoint-restart cycles, sustaining ahead coaching momentum regardless of failures, lowering restoration time from hours to minutes. Speed up your AI mannequin growth, reclaim days from growth timelines, and confidently scale coaching workflows to hundreds of AI accelerators.
- Elastic coaching – Elastic coaching maximizes cluster utilization as coaching workloads routinely broaden to make use of idle capability because it turns into accessible, and contract to yield sources as higher-priority workloads like inference volumes peak. Save hours of engineering time per week spent reconfiguring coaching jobs primarily based on compute availability.
Quite than spending time managing coaching infrastructure, these new coaching methods imply that your workforce can focus fully on enhancing mannequin efficiency, in the end getting your AI fashions to market quicker. By eliminating the normal checkpoint dependencies and absolutely using accessible capability, you possibly can considerably scale back mannequin coaching completion instances.
Checkpointless coaching: The way it works
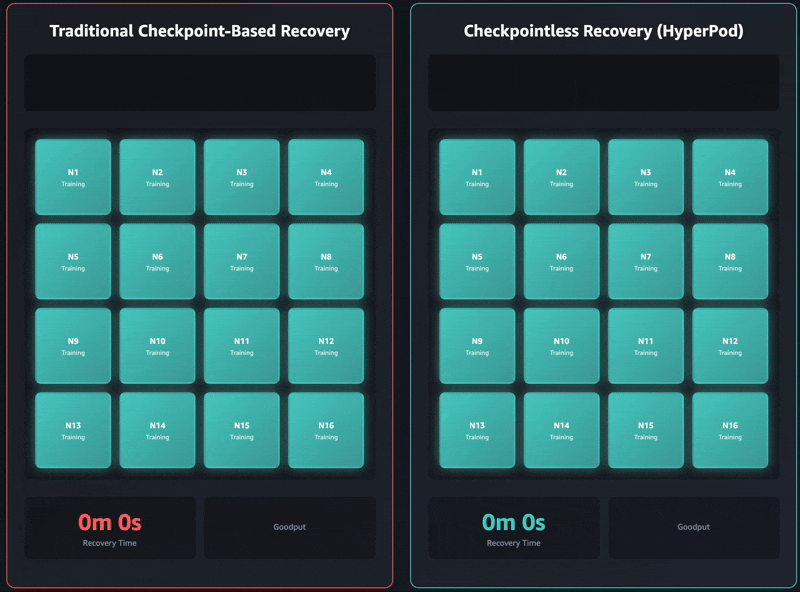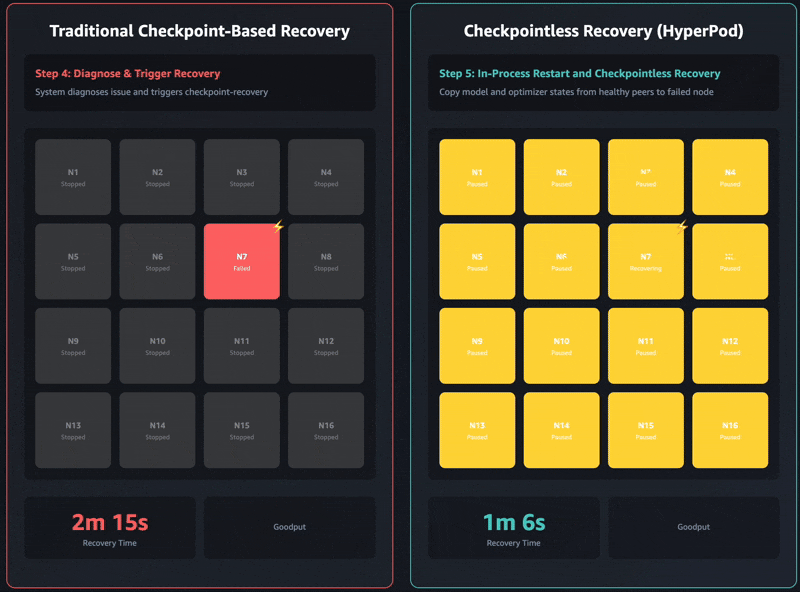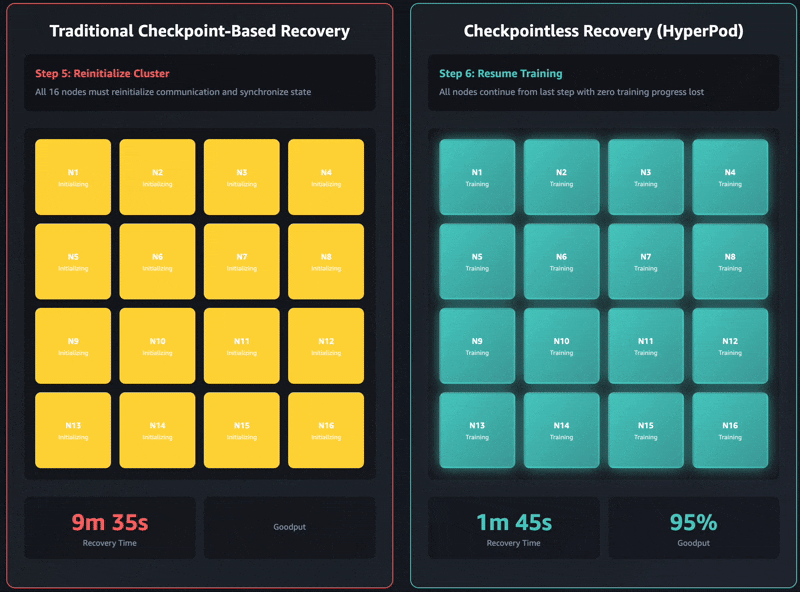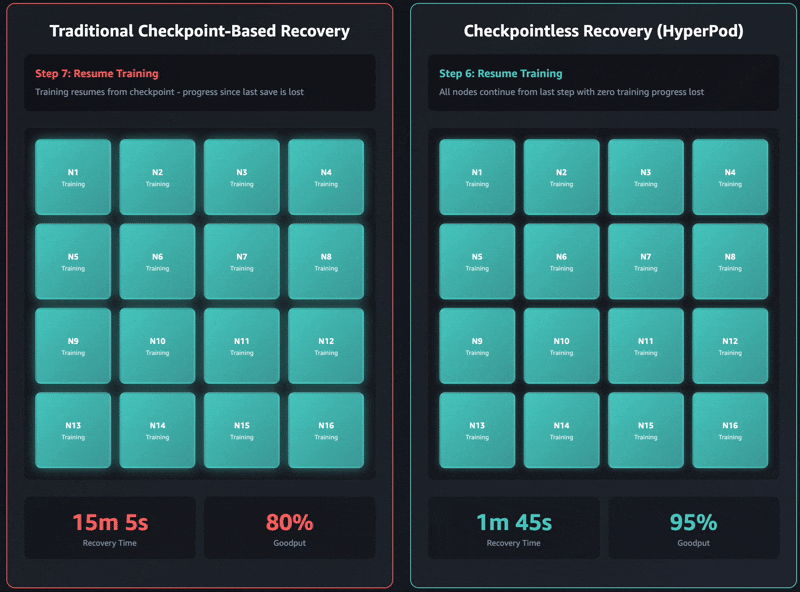
Conventional checkpoint-based restoration has these sequential job phases: 1) job termination and restart, 2) course of discovery and community setup, 3) checkpoint retrieval, 4) knowledge loader initialization, and 5) coaching loop resumption. When failures happen, every stage can develop into a bottleneck and coaching restoration can take as much as an hour on self-managed coaching clusters. The complete cluster should wait for each single stage to finish earlier than coaching can resume. This could result in the whole coaching cluster sitting idle throughout restoration operations, which will increase prices and extends the time to market.
Checkpointless coaching removes this bottleneck fully by sustaining steady mannequin state preservation throughout the coaching cluster. When failures happen, the system immediately recovers by utilizing wholesome friends, avoiding the necessity for a checkpoint-based restoration that requires restarting the whole job. Consequently, checkpointless coaching allows fault restoration in minutes.
Checkpointless coaching is designed for incremental adoption and constructed on 4 core parts that work collectively: 1) collective communications initialization optimizations, 2) memory-mapped knowledge loading that permits caching, 3) in-process restoration, and 4) checkpointless peer-to-peer state replication. These parts are orchestrated by the HyperPod coaching operator that’s used to launch the job. Every part optimizes a particular step within the restoration course of, and collectively they allow computerized detection and restoration of infrastructure faults in minutes with zero guide intervention, even with hundreds of AI accelerators. You’ll be able to progressively allow every of those options as your coaching scales.
The most recent Amazon Nova fashions have been skilled utilizing this know-how on tens of hundreds of accelerators. Moreover, primarily based on inside research on cluster sizes ranging between 16 GPUs to over 2,000 GPUs, checkpointless coaching showcased important enhancements in restoration instances, lowering downtime by over 80% in comparison with conventional checkpoint-based restoration.
To study extra, go to checkpointless coaching GitHub web page for implementation and HyperPod Checkpointless Coaching within the Amazon SageMaker AI Developer Information.
Elastic coaching: The way it works
On clusters that run various kinds of trendy AI workloads, accelerator availability can change constantly all through the day as short-duration coaching runs full, inference spikes happen and subside, or sources unlock from accomplished experiments. Regardless of this dynamic availability of AI accelerators, conventional coaching workloads stay locked into their preliminary compute allocation, unable to benefit from idle accelerators with out guide intervention. This rigidity leaves priceless GPU capability unused and prevents organizations from maximizing their infrastructure funding.
 Elastic coaching transforms how coaching workloads work together with cluster sources. Coaching jobs can routinely scale as much as make the most of accessible accelerators and gracefully contract when sources are wanted elsewhere, all whereas sustaining coaching high quality.
Elastic coaching transforms how coaching workloads work together with cluster sources. Coaching jobs can routinely scale as much as make the most of accessible accelerators and gracefully contract when sources are wanted elsewhere, all whereas sustaining coaching high quality.
Workload elasticity is enabled by the HyperPod coaching operator that orchestrates scaling choices by integration with the Kubernetes management airplane and useful resource scheduler. It constantly screens cluster state by three major channels: pod lifecycle occasions, node availability modifications, and useful resource scheduler precedence alerts. This complete monitoring allows near-instantaneous detection of scaling alternatives, whether or not from newly accessible sources or requests from higher-priority workloads.
The scaling mechanism depends on including and eradicating knowledge parallel replicas. When extra compute sources develop into accessible, new knowledge parallel replicas be a part of the coaching job, accelerating throughput. Conversely, throughout scale-down occasions (for instance, when a higher-priority workload requests sources), the system scales down by eradicating replicas moderately than terminating the whole job, permitting coaching to proceed at lowered capability.
Throughout completely different scales, the system preserves the worldwide batch measurement and adapts studying charges, stopping mannequin convergence from being adversely impacted. This allows workloads to dynamically scale up or right down to make the most of accessible AI accelerators with none guide intervention.
You can begin elastic coaching by the HyperPod recipes for publicly accessible basis fashions (FMs) together with Llama and GPT-OSS. Moreover, you possibly can modify your PyTorch coaching scripts so as to add elastic occasion handlers, which allow the job to dynamically scale.
To study extra, go to the HyperPod Elastic Coaching within the Amazon SageMaker AI Developer Information. To get began, discover the HyperPod recipes accessible within the AWS GitHub repository.
Now accessible
Each options can be found in all of the Areas through which Amazon SageMaker HyperPod is obtainable. You should use these coaching methods with out extra value. To study extra, go to the SageMaker HyperPod product web page and SageMaker AI pricing web page.
Give it a attempt to ship suggestions to AWS re:Publish for SageMaker or by your standard AWS Help contacts.
— Channy