

{kind=link}
Whereas Zalando is now one in every of Europe’s main on-line style vacation spot, it started in 2008 as a Berlin-based startup promoting footwear on-line. What began with only a few manufacturers and a single nation rapidly grew right into a pan-European enterprise, working in 27 markets and serving greater than 52 million energetic clients.
Quick ahead to right this moment, and Zalando isn’t simply an internet retailer—it’s a tech firm at its core. With greater than €14 billion in annual gross merchandise quantity (GMV), the corporate realized that to serve style at scale, it wanted to depend on extra than simply logistics and stock. It wanted knowledge. And never simply to assist the enterprise—however to drive it.
On this publish, we present how Zalando migrated their fast-serving layer knowledge warehouse to Amazon Redshift to realize higher price-performance and scalability.
The dimensions and scope of Zalando’s knowledge operations
From personalised dimension suggestions that cut back returns to dynamic pricing, demand forecasting, focused advertising, and fraud detection, knowledge and AI are embedded throughout the group.
Zalando’s knowledge platform operates at a formidable scale, managing over 20 petabytes of information in its lake supporting varied analytics and machine studying functions. The info platform hosts greater than 5,000 knowledge merchandise maintained by 350 decentralized groups, serving 6,000 month-to-month customers, representing 80% of Zalando’s company workforce. As a completely self-service knowledge platform, it gives SQL analytics, orchestration, knowledge discovery, and high quality monitoring, empowering groups to construct and handle knowledge merchandise independently.
This scale solely made the necessity for modernization extra pressing. It was clear that environment friendly knowledge loading, dynamic compute scaling, and future-ready infrastructure had been important.
Challenges with the present Quick-Serving Layer (knowledge warehouse)
To allow selections throughout analytics, dashboards, and machine studying, Zalando makes use of an information warehouse that acts as a fast-serving layer and spine for essential knowledge/reporting use circumstances. This layer holds about 5,000 curated tables and views, optimized for fast, read-heavy workloads. Each week, greater than 3,000 customers—together with analysts, knowledge scientists, and enterprise stakeholders—depend on this layer for immediate insights.
However the incumbent knowledge warehouse wasn’t future proof. It was primarily based on a monolithic cluster setup optimized for peak hundreds, like Monday mornings, when weekly and every day jobs pile up. Because of this, 80% of the time, the system sat underutilized, burning compute and resulting in substantial “slack prices” from over-provisioned capability, with potential month-to-month financial savings of over $30,000 if dynamic scaling had been attainable. Concurrency limitations resulted in excessive latency and disrupted business-critical reporting processes. The system’s lack of elasticity led to poor cost-to-utilization ratios, whereas the absence of workload isolation between groups incessantly precipitated operational incidents. Upkeep and scaling required fixed vendor assist, making it tough to handle peak durations like CyberWeek as a consequence of occasion shortage. Moreover, the platform lacked trendy options reminiscent of on-line question editors and correct auto scaling capabilities, whereas its sluggish characteristic improvement and restricted neighborhood assist additional hindered Zalando’s capacity to innovate.
Fixing for scale: Zalando’s journey to a contemporary quick serving layer
Zalando was on the lookout for an answer that demonstrated capabilities which may meet their value and efficiency targets via a “easy carry and shift” strategy. Amazon Redshift was chosen for the POC to deal with autoscaling and concurrency wants, whereas concurrently lowering operational efforts in addition to its capacity to combine with Zalando’s current knowledge platform and align with their general knowledge technique.
The general analysis scope for the Redshift evaluation coated following key areas.
Efficiency and value
The analysis of Amazon Redshift demonstrated substantial efficiency enhancements and value advantages in comparison with the outdated knowledge warehousing platform.
- Redshift supplied 3-5 instances quicker question execution time.
- Roughly 86% of distinct queries ran quicker on Redshift.
- In a “Monday morning situation”, Redshift demonstrated 3 instances quicker gathered execution time in comparison with the present platform
- For brief queries, Redshift achieved 100% SLA compliance for queries within the 80-480 second vary. For queries as much as 80 seconds, 90% met SLA.
- Redshift demonstrated 5x quicker parallel question execution, dealing with considerably larger concurrent queries than the present knowledge warehouse’s most parallelism.
- For Interactive Utilization use circumstances, Redshift demonstrated sturdy efficiency, which is crucial for BI software customers, particularly in parallel executions situation.
- Redshift options reminiscent of Automated Desk Optimizations and Automated Materialized views eradicated the necessity for knowledge producing groups to manually optimize the design of tables, making it extremely appropriate for a central service providing.
Structure
Redshift efficiently demonstrated workload isolation reminiscent of separating transformations(ETL) from serving (BI, Advert-hoc and so forth.) workload utilizing Amazon Redshift knowledge sharing. It additionally proved its versatility via integration with Spark and customary file codecs was additionally confirmed.
Safety
Amazon Redshift efficiently demonstrated end-to-end encryption, auditing capabilities, and complete entry controls with Row-Degree and Column-Degree Safety as a part of the proof of idea.
Developer productiveness
The analysis demonstrated important enhancements in developer effectivity. A baseline idea for central deployment template authoring and distribution through AWS Service Catalog was efficiently applied. Moreover, Redshift confirmed spectacular agility with its capacity to deploy Redshift Serverless endpoints in minutes for ad-hoc analytics, enhancing the group’s capacity to rapidly reply to analytical wants.
Amazon Redshift migration technique
This part outlines the strategy Zalando took emigrate the fast-serving layer to Amazon Redshift.
From monolith to modular: Redesigning with Redshift
The migration technique concerned a whole re-architecture of the fast-serving layer, transferring to Amazon Redshift with a multi-warehouse mannequin that separates knowledge producers from knowledge shoppers.Key parts and rules of the goal structure embrace:
- Workload Isolation: Use circumstances are remoted by occasion or setting, with knowledge shares facilitating knowledge change between them. Knowledge shares allow an “straightforward fan out” of information from the Producer warehouse to numerous Shopper warehouses. The producer and client warehouses could be both Provisioned (reminiscent of for BI Instruments) or Serverless (reminiscent of for Analysts). This enables for knowledge sharing between separate authorized entities.
- Standardized Knowledge Loading: A Knowledge Loading API (proprietary to Zalando) was constructed to standardize knowledge loading processes. This API helps incremental loading and efficiency optimizations. Applied with AWS Step Capabilities and AWS Lambda, it detects modified Parquet recordsdata from Delta lake metadata and makes use of Redshift spectrum for loading knowledge into the Redshift Producer warehouse.
- Utilizing Redshift Serverless: Zalando goals to make use of Redshift Serverless wherever attainable. Redshift Serverless gives flexibility, value effectivity, and improved efficiency, notably for the light-weight queries prevalent in BI dashboards. It additionally permits the deployment of Redshift serverless endpoints in minutes for ad-hoc analytics, enhancing developer productiveness.
The next diagram depicts Zalando’s end-to-end Amazon Redshift multi-warehouse structure, highlighting the producer-consumer mannequin:
The core technique of migration was “lift-and-shift” when it comes to code to keep away from complicated refactoring and meet deadlines.
The primary rules used had been:
- Run duties in parallel at any time when attainable.
- Decrease the workload for inner knowledge groups.
- Decouple duties to permit groups to schedule work flexibly.
- Maximize the work completed by centrally managed companions.
Three-stage migration strategy
The migration is damaged down into three distinct levels to handle the transition successfully.
Stage 1: Knowledge replication
Zalando’s precedence was creating a whole, synchronized copy of all goal knowledge tables from the outdated knowledge warehouse to Redshift. An automatic course of was applied utilizing Changehub, an inner software constructed on Amazon Managed Workflows for Apache Airflow (MWAA), that screens the outdated system’s logs and syncs knowledge updates to Redshift roughly each 5-10 minutes, establishing the brand new knowledge basis with out disrupting current workflows.
Stage 2: Workload migration
The second stage centered on transferring enterprise logic (ETL) and MicroStrategy reporting to Redshift to considerably cut back the load on the legacy system. For ETL migration, semi-automated strategy was applied utilizing Migvisor code convertor to transform the scripts. MicroStrategy reporting was migrated by leveraging MSTR’s functionality to robotically generate Redshift-compatible queries primarily based on the semantic layer.
Stage 3: Finalization and decommissioning
The ultimate stage completes the transition by migrating all remaining knowledge shoppers and ingestion processes, resulting in the total shutdown of the outdated knowledge warehouse. Throughout this section, all knowledge pipelines are being rerouted to feed immediately into Redshift, and long-term possession of processes is being transitioned to the respective groups earlier than the outdated system is absolutely decommissioned.
Advantages and Outcomes
A serious infrastructure change at Zalando occurred on October 30, 2024, switching 80% of analytics reporting from the outdated knowledge warehouse answer to Redshift. The migration of 80% of analytics reporting to Redshift efficiently decreased operational threat for the essential Cyber Week interval and enabled the decommissioning of the outdated knowledge warehouse to keep away from important license charges.
The mission resulted in substantial efficiency and stability enhancements throughout the board.
Efficiency Enhancements
Key efficiency metrics display substantial enhancements throughout a number of dimensions:
- Sooner Question Execution: 75% of all queries now execute quicker on Redshift.
- Improved Reporting Velocity: Excessive-priority reporting queries are considerably quicker, with a 13% discount in P90 execution time and a 23% discount in P99 execution time.
- Drastic Discount in System Load: The general processing time for MicroStrategy (MSTR) studies has dramatically decreased. Peak Monday morning execution time dropped from 130 minutes to 52 minutes. Within the first 4
- weeks, the full MSTR job length was decreased by over 19,000 hours (equal to 2.2 years of compute time) in comparison with the earlier system. This has led to much more constant and dependable efficiency.
The next graph reveals one of many essential Monday Morning Workload elapsed length on old-data warehouse in addition to Amazon Redshift.
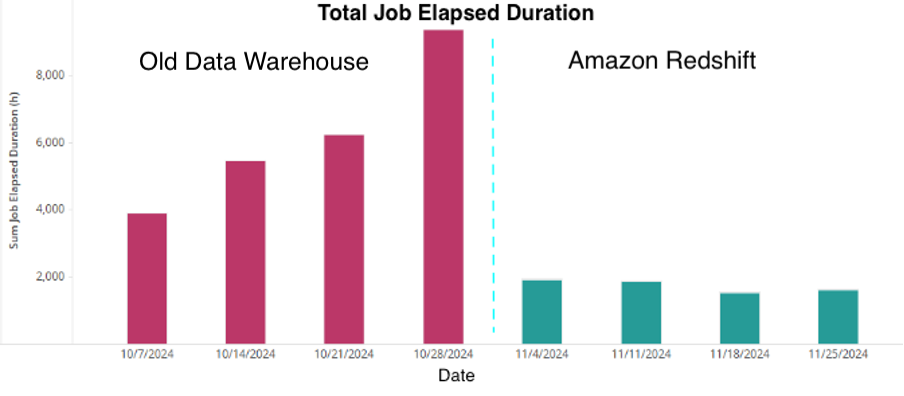
Operational stability
Amazon Redshift has confirmed to be considerably extra steady and dependable, efficiently assembly the important thing goal of lowering operational threat.
- Report Timeouts: Report timeouts, a main concern, have been nearly eradicated.
- Essential Enterprise Interval Efficiency: Redshift carried out exceptionally properly throughout the high-stress Cyber Week 2024. It is a stark distinction to the outdated system, which suffered essential, financially impactful failures throughout the identical interval in 2022 and 2023.
- Knowledge Loading: For knowledge producers, the consistency of information loading is essential, as delays can maintain up quite a few studies and trigger direct enterprise influence. The system relied on an “ETL Prepared” occasion, which triggers report processing solely in spite of everything required datasets have been loaded. Because the migration to Redshift, the timing of this occasion has grow to be considerably extra constant, enhancing the reliability of the whole knowledge pipeline.
The next diagram reveals consistency in ETL Prepared occasion, after migrating to Amazon Redshift
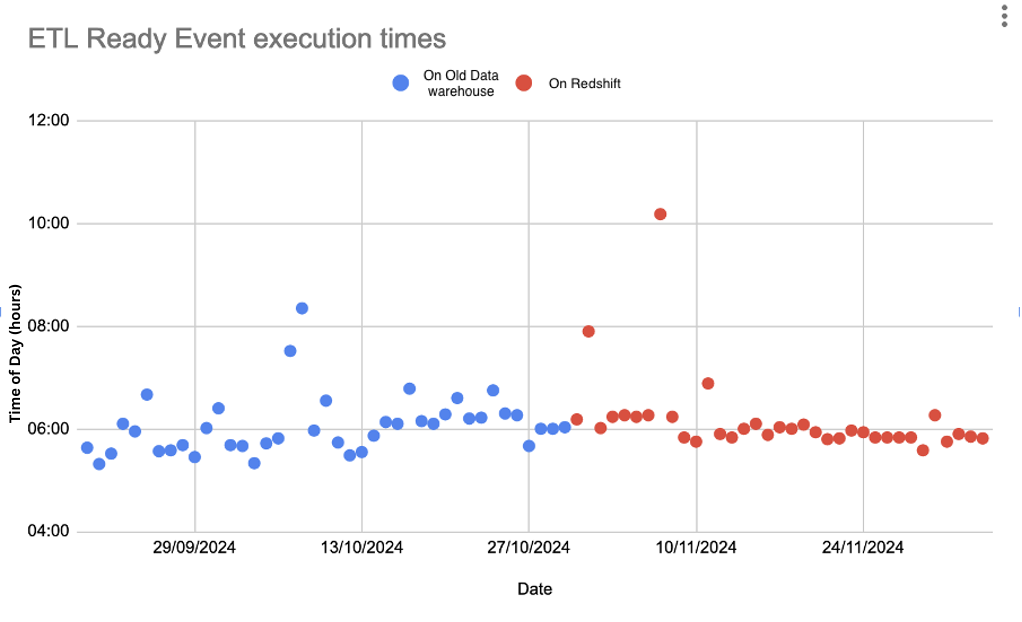
Finish consumer expertise
The discount in whole execution time of Monday morning hundreds has resulted in dramatically improved end-user productiveness. That is the time wanted to course of the total batch of scheduled studies (peak load), which immediately interprets to attend instances and productiveness for finish customers, since that is when most customers want their weekly studies for his or her enterprise. The next graphs reveals typical Mondays earlier than and after the change and the way Amazon Redshift handles the MSTR queue offering significantly better finish consumer expertise.
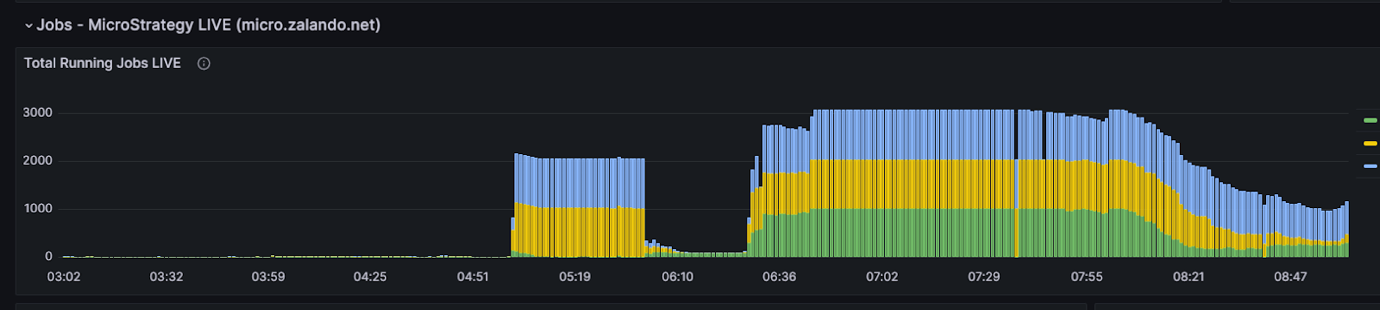 MSTR queue on 28/10/2024 (earlier than change)
MSTR queue on 28/10/2024 (earlier than change)
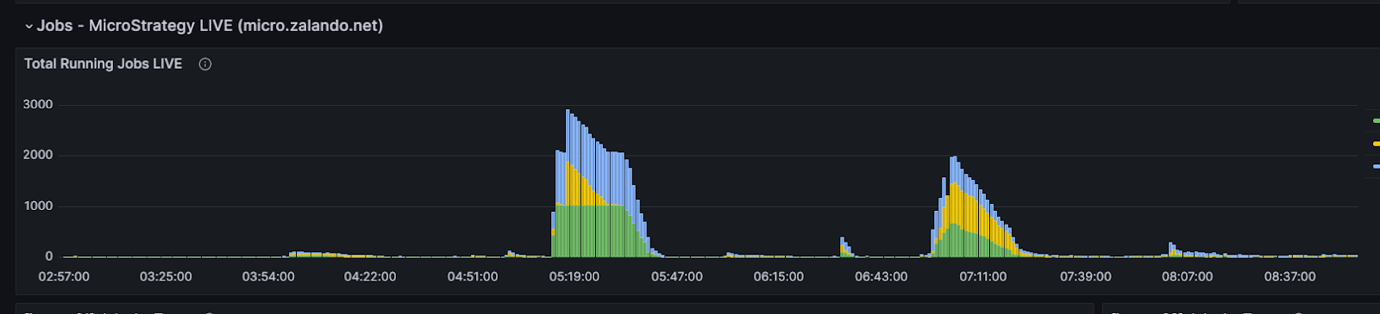 MSTR queue on 02/12/25 (after change)
MSTR queue on 02/12/25 (after change)
Learnings and unexpected challenges
Navigating automated optimization in a multi-warehouse structure
Probably the most important challenges Zalando encountered throughout migration entails Redshift’s multi-warehouse structure and its interplay with automated desk upkeep. The Redshift structure is designed for workload isolation: a central producer warehouse for knowledge loading, and a number of client warehouses for analytical queries. Knowledge and related objects reside solely on the producer and are shared through Redshift Datashare.
The core situation: Redshift’s Automated Desk Optimization (ATO) operates solely on the producer warehouse. This extends to different efficiency options like Automated Materialized Views and automated question rewriting. Consequently, these optimization processes had been unaware of question patterns and workloads on client warehouses. For example, MicroStrategy studies operating heavy analytical queries on the patron aspect had been outdoors the scope of those automated options. This led to suboptimal knowledge fashions and important efficiency impacts, notably for tables with AUTO-set distribution and kind keys.
To handle this, two-pronged strategy was applied:
1. Collaborative guide tuning: Zalando labored intently with the AWS Database Engineering group, who present holistic efficiency checks and tailor-made suggestions for distribution and kind keys throughout all warehouses.
2. Scheduled desk upkeep: Zalando applied a every day VACUUM course of for tables with over 5% unsorted knowledge, guaranteeing knowledge group and question efficiency.
Moreover, following knowledge distribution technique was applied:
- KEY Distribution: Explicitly outlined DISTKEY for tables with clear JOIN circumstances.
- EVEN Distribution: Used for big reality tables with out clear be part of keys.
- ALL Distribution: Utilized to smaller dimension tables (underneath 4 million rows).
This proactive strategy has given higher management over cluster efficiency and mitigated knowledge skew points. Zalando is inspired that AWS is working to incorporate cross-cluster workload consciousness in a future Redshift launch, which ought to additional optimize multi-warehouse setup.
CTEs and execution plans
Widespread Desk Expressions (CTEs) are a robust software for structuring complicated queries by breaking them down into logical, readable steps. Evaluation of question efficiency recognized optimization alternatives in CTE utilization patterns.
Efficiency monitoring revealed that Redshift’s question engine would typically recompute the logic for a nested or repeatedly referenced CTE from scratch each time it was referred to as inside the similar SQL assertion as an alternative of writing the CTE’s end result to an in-memory non permanent desk for reuse.
Two methods proved efficient in addressing this problem:
- Convert to a materialized view: CTEs used incessantly throughout a number of queries or with notably complicated logic had been transformed into materialized views (MVs). This pre-compute the end result, making the information available with out re-running the underlying logic.
- Use express non permanent tables: For CTEs used a number of instances inside a single, complicated question, the CTE’s end result was explicitly written right into a non permanent desk initially of the transaction. For instance, inside MicroStrategy, the “intermediate desk kind” setting was modified from the default CTE to “Momentary desk.”
Implementation of both materialized views or non permanent tables ensures the complicated logic is computed solely as soon as. This strategy eradicated the recomputation situation and considerably improved the efficiency of multi-layered SQL queries.
Optimizing reminiscence utilization by right-sizing VARCHAR columns
It might appear to be a minor element, however defining the suitable size for VARCHAR columns can have a shocking and important influence on question efficiency. This was found firsthand whereas investigating the basis reason behind sluggish queries that had been displaying excessive quantities of disk spill.
The difficulty stemmed from knowledge loading API software, which is answerable for syncing knowledge from Delta Lake tables into Redshift. As a result of Delta Lake’s StringType datatype doesn’t have an outlined size, the software defaulted to creating Redshift columns with a really excessive VARCHAR size (reminiscent of VARCHAR(16384)).
When a question is executed, the Redshift question engine allocates reminiscence for in-transit knowledge primarily based on the column’s outlined dimension, not the precise dimension of the information it comprises. This meant that for a column containing strings of solely 50 characters however outlined as VARCHAR(16384), the engine would reserve a vastly outsized block of reminiscence. This extreme reminiscence allocation led on to excessive disk spill, the place intermediate question outcomes overflowed from reminiscence to disk, drastically slowing down execution.
To resolve this, a brand new course of was applied requiring knowledge groups to explicitly outline acceptable column lengths throughout object deployment. nalyzing the precise knowledge and setting sensible VARCHAR sizes (reminiscent of VARCHAR(100) as an alternative of VARCHAR(16384)), considerably improved reminiscence utilization, decreased disk spill, and boosted general question velocity. This modification underscores the significance of precision in knowledge definition for an optimized Redshift setting.
Future outlook
Central to Zalando technique is the shift to a serverless-based warehouse topology. This transfer permits automated scaling to satisfy fluctuating analytical calls for, from seasonal gross sales peaks to new group tasks, all with out guide intervention. The strategy permits knowledge groups to focus completely on producing insights that drive innovation, guaranteeing platform efficiency aligns with enterprise development.
Because the platform scales, accountable administration is paramount. The combination of AWS Lake Formation create a centralized governance mannequin for safe, fine-grained knowledge entry, enabling secure knowledge democratization throughout the group. Concurrently, Zalando is embedding a powerful FinOps tradition by establishing unified value administration processes. This gives knowledge house owners with a complete, 360-degree view of their prices throughout Redshift’s companies, empowering them with actionable insights to optimize spending and align it with enterprise worth. In the end, the objective is to make sure each funding in Zalando’s knowledge platform is maximized for enterprise influence.
Conclusion
On this publish, we confirmed how Zalando’s migration to Amazon Redshift has efficiently remodeled its knowledge platform, making it a extra data-driven style tech chief. This transfer has delivered important enhancements throughout key areas together with enhanced efficiency, elevated stability, decreased operational prices, and improved knowledge consistency. Transferring ahead, a serverless-based structure, centralized governance with AWS Lake Formation, and a powerful FinOps tradition will proceed to drive innovation and maximize enterprise influence.
Should you’re enthusiastic about studying extra about Amazon Redshift capabilities, we advocate watching the newest What’s new with Amazon Redshift session within the AWS Occasions channel to get an summary of the options not too long ago added to the service. You can even discover the self-service, hands-on Amazon Redshift labs to experiment with key Amazon Redshift functionalities in a guided method.
Contact your AWS account group to learn the way we will help you modernize your knowledge warehouse infrastructure.
Concerning the authors