

{kind=link}
Google AI has launched TranslateGemma, a set of open machine translation fashions constructed on Gemma 3 and focused at 55 languages. The household is available in 4B, 12B and 27B parameter sizes. It’s designed to run throughout units from cell and edge {hardware} to laptops and a single H100 GPU or TPU occasion within the cloud.
TranslateGemma just isn’t a separate structure. It’s Gemma 3 specialised for translation by way of a two stage submit coaching pipeline. (1) supervised advantageous tuning on massive parallel corpora. (2) Reinforcement studying that optimizes translation high quality with a multi sign reward ensemble. The objective is to push translation high quality whereas holding the overall instruction following habits of Gemma 3.
Supervised advantageous tuning on artificial and human parallel information
The supervised advantageous tuning stage begins from the general public Gemma 3 4B, 12B and 27B checkpoints. The analysis staff makes use of parallel information that mixes human translations with prime quality artificial translations generated by Gemini fashions.
Artificial information is produced from monolingual sources with a multi step process. The pipeline selects candidate sentences and brief paperwork, feeds them to Gemini 2.5 Flash, after which filters outputs with MetricX 24 QE to maintain solely examples that present clear high quality good points. That is utilized throughout all WMT24 plus plus language pairs plus 30 extra language pairs.
Low useful resource languages obtain human generated parallel information from the SMOL and GATITOS datasets. SMOL covers 123 languages and GATITOS covers 170 languages. This improves protection of scripts and language households which are underneath represented in publicly out there internet parallel information.
The ultimate supervised advantageous tuning combination additionally retains 30 % generic instruction following information from the unique Gemma 3 combination. That is vital. With out it, the mannequin would over specialize on pure translation and lose common LLM habits akin to following directions or doing easy reasoning in context.
Coaching makes use of the Kauldron SFT (Supervised High-quality tuning) tooling with the AdaFactor optimizer. The training fee is 0.0001 with batch dimension 64 for 200000 steps. All mannequin parameters are up to date besides the token embeddings, that are frozen. Freezing embeddings helps protect illustration high quality for languages and scripts that don’t seem within the supervised advantageous tuning information.
Reinforcement studying with a translation centered reward ensemble
After supervised advantageous tuning, TranslateGemma runs a reinforcement studying part on high of the identical translation information combination. The reinforcement studying goal makes use of a number of reward fashions.
The reward ensemble contains:
- MetricX 24 XXL QE, a discovered regression metric that approximates MQM scores and is used right here in high quality estimation mode with no reference.
- Gemma AutoMQM QE, a span stage error predictor advantageous tuned from Gemma 3 27B IT on MQM labeled information. It produces token stage rewards based mostly on error sort and severity.
- ChrF, a personality n gram overlap metric that compares mannequin output with artificial references and is rescaled to match the opposite rewards.
- A Naturalness Autorater that makes use of the coverage mannequin as an LLM choose and produces span stage penalties for segments that don’t sound like native textual content.
- A generalist reward mannequin from the Gemma 3 submit coaching setup that retains reasoning and instruction following means intact.
TranslateGemma makes use of reinforcement studying algorithms that mix sequence stage rewards with token stage benefits. Span stage rewards from AutoMQM and the Naturalness Autorater connect on to the affected tokens. These token benefits are added to sequence benefits computed from reward to go after which batch normalized. This improves credit score project in contrast with pure sequence stage reinforcement studying.
Benchmark outcomes on WMT24++
TranslateGemma is evaluated on the WMT24++ benchmark utilizing MetricX 24 and Comet22. MetricX is decrease higher and correlates with MQM error counts. Comet22 is larger higher and measures adequacy and fluency.
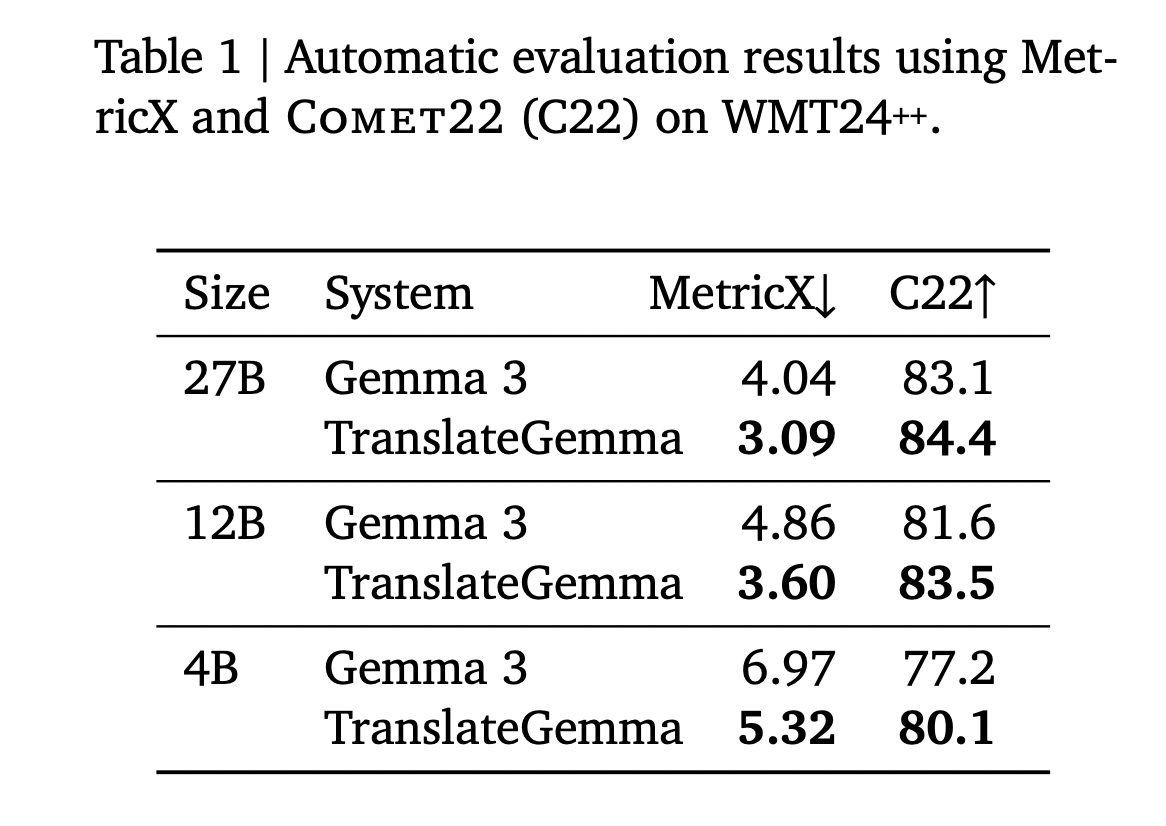
The above Desk from the analysis pape summarizes outcomes for English centered analysis over 55 language pairs.
- 27B: Gemma 3 baseline has MetricX 4.04 and Comet22 83.1. TranslateGemma 27B reaches MetricX 3.09 and Comet22 84.4.
- 12B: Gemma 3 baseline has MetricX 4.86 and Comet22 81.6. TranslateGemma 12B reaches MetricX 3.60 and Comet22 83.5.
- 4B: Gemma 3 baseline has MetricX 6.97 and Comet22 77.2. TranslateGemma 4B reaches MetricX 5.32 and Comet22 80.1.
The important thing sample is that TranslateGemma improves high quality for each mannequin dimension. On the similar time, mannequin scale interacts with specialization. The 12B TranslateGemma mannequin surpasses the 27B Gemma 3 baseline. The 4B TranslateGemma mannequin reaches high quality much like the 12B Gemma 3 baseline. This implies a smaller translation specialised mannequin can substitute a bigger baseline mannequin for a lot of machine translation workloads.
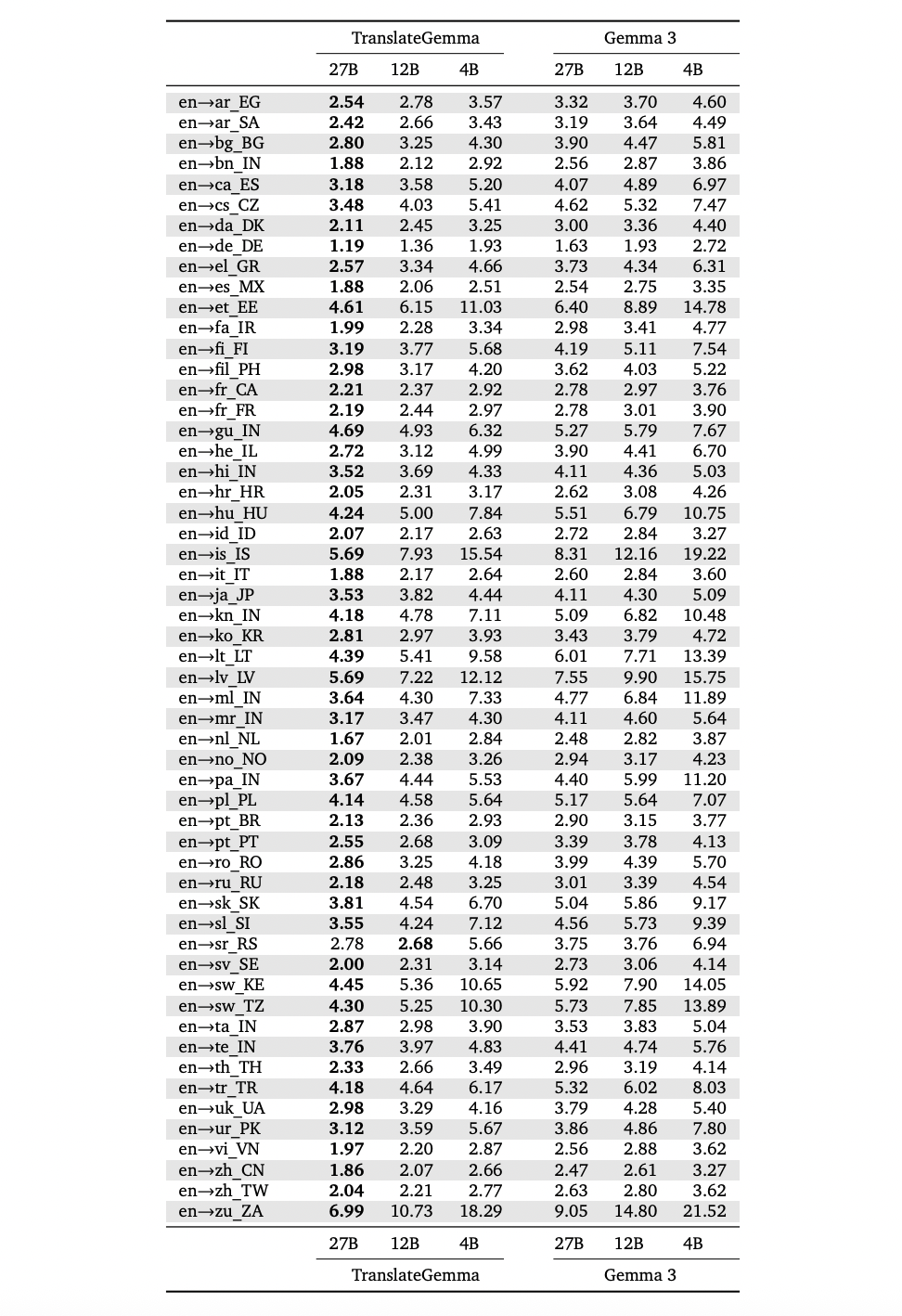
A language stage breakdown within the above appendix desk from the analysis paper reveals that these good points seem throughout all 55 language pairs. For instance, MetricX improves from 1.63 to 1.19 for English to German, 2.54 to 1.88 for English to Spanish, 3.90 to 2.72 for English to Hebrew, and 5.92 to 4.45 for English to Swahili. Enhancements are additionally massive for tougher circumstances akin to English to Lithuanian, English to Estonian and English to Icelandic.
Human analysis on WMT25 with MQM confirms this pattern. TranslateGemma 27B often yields decrease MQM scores, that’s fewer weighted errors, than Gemma 3 27B, with particularly sturdy good points for low useful resource instructions akin to English to Marathi, English to Swahili and Czech to Ukrainian. There are two notable exceptions. For German as goal each programs are very shut. For Japanese to English TranslateGemma reveals a regression induced primarily by named entity errors, despite the fact that different error classes enhance.
Multimodal translation and interface for builders
TranslateGemma inherits the picture understanding stack of Gemma 3. The analysis staff evaluates picture translation on the Vistra benchmark. They choose 264 photos that every include a single textual content occasion. The mannequin receives solely the picture plus a immediate that asks it to translate the textual content within the picture. There is no such thing as a separate bounding field enter and no specific OCR step.
On this setting, TranslateGemma 27B improves MetricX from 2.03 to 1.58 and Comet22 from 76.1 to 77.7. The 4B variant reveals smaller however optimistic good points. The 12B mannequin improves MetricX however has a barely decrease Comet22 rating than the baseline. General, the analysis staff concludes that TranslateGemma retains the multimodal means of Gemma 3 and that textual content translation enhancements principally carry over to picture translation.
Key Takeaways
- TranslateGemma is a specialised Gemma 3 variant for translation: TranslateGemma is a set of open translation fashions derived from Gemma 3, with 4B, 12B and 27B parameter sizes, optimized for 55 languages by way of a two stage pipeline, supervised advantageous tuning then reinforcement studying with translation centered rewards.
- Coaching combines Gemini artificial information with human parallel corpora: The fashions are advantageous tuned on a combination of top of the range artificial parallel information generated by Gemini and human translated information, which improves protection for each excessive useful resource and low useful resource languages whereas preserving common LLM capabilities from Gemma 3.
- Reinforcement studying makes use of an ensemble of high quality estimation rewards: After supervised advantageous tuning, TranslateGemma applies reinforcement studying pushed by an ensemble of reward fashions, together with MetricX QE and AutoMQM, that explicitly goal translation high quality and fluency somewhat than generic chat habits.
- Smaller fashions match or beat bigger Gemma 3 baselines on WMT24++: On WMT24++ throughout 55 languages, all TranslateGemma sizes present constant enhancements over Gemma 3, with the 12B mannequin surpassing the 27B Gemma 3 baseline and the 4B mannequin reaching high quality akin to the 12B baseline, which reduces compute necessities for a given translation high quality stage.
- Fashions retain multimodal skills and are launched as open weights: TranslateGemma retains Gemma 3 picture textual content translation capabilities and improves efficiency on the Vistra picture translation benchmark, and the weights are launched as open fashions on Hugging Face and Vertex AI, enabling native and cloud deployment.
Try the Paper, Mannequin Weights and Technical particulars. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be a part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.