

{kind=link}
On this article, we’ll concentrate on Gated Recurrent Models (GRUs)- a extra easy but highly effective various that’s gained traction for its effectivity and efficiency.
Whether or not you are new to sequence modeling or trying to sharpen your understanding, this information will clarify how GRUs work, the place they shine, and why they matter in at this time’s deep studying panorama.
In deep studying, not all knowledge arrives in neat, unbiased chunks. A lot of what we encounter: language, music, inventory costs, unfolds over time, with every second formed by what got here earlier than. That’s the place sequential knowledge is available in, and with it, the necessity for fashions that perceive context and reminiscence.
Recurrent Neural Networks (RNNs) have been constructed to deal with the problem of working with sequences, making it doable for machines to comply with patterns over time, like how individuals course of language or occasions.
Nonetheless, conventional RNNs are likely to lose observe of older data, which might result in weaker predictions. That’s why newer fashions like LSTMs and GRUs got here into the image, designed to higher maintain on to related particulars throughout longer sequences.
What are GRUs?
Gated Recurrent Models, or GRUs, are a sort of neural community that helps computer systems make sense of sequences- issues like sentences, time collection, and even music. In contrast to normal networks that deal with every enter individually, GRUs keep in mind what got here earlier than, which is essential when context issues.

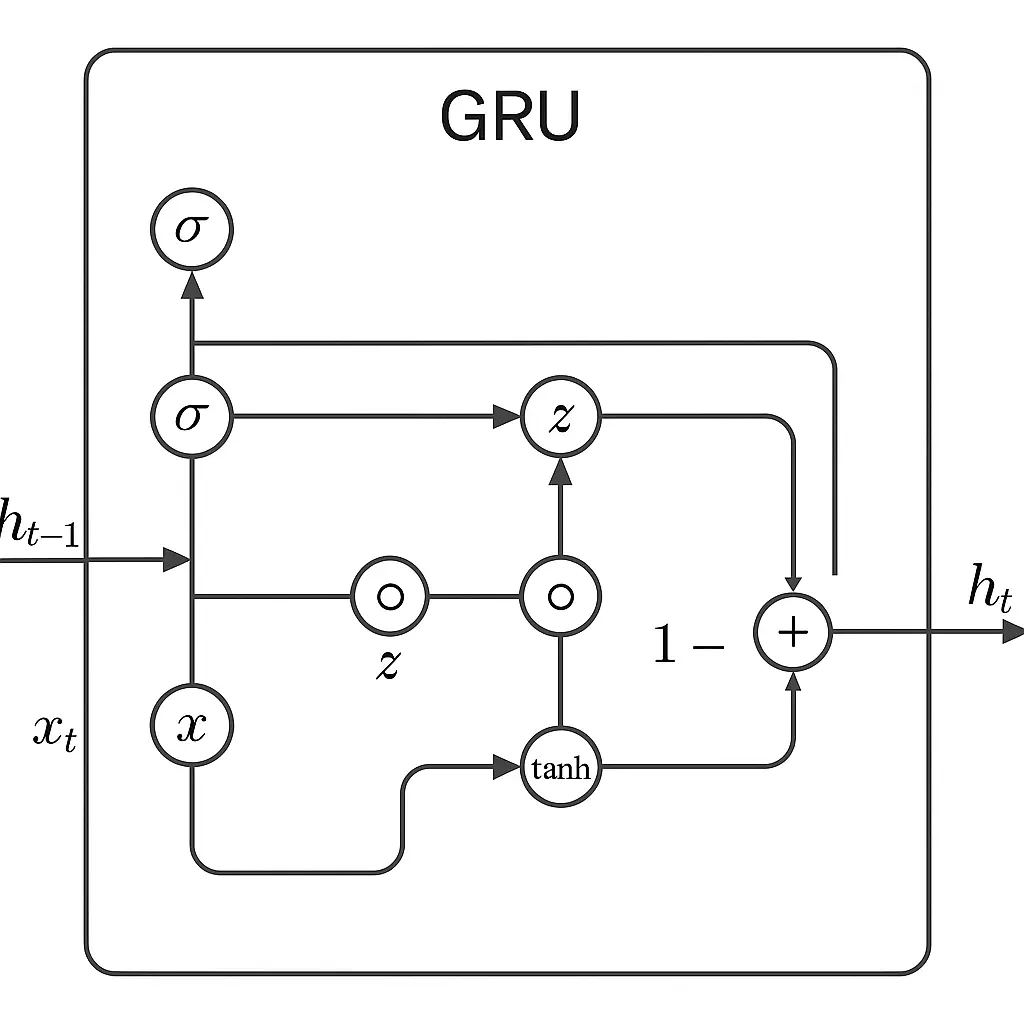
GRUs work by utilizing two fundamental “gates” to handle data. The replace gate decides how a lot of the previous needs to be stored round, and the reset gate helps the mannequin work out how a lot of the previous to overlook when it sees new enter.
These gates enable the mannequin to concentrate on what’s essential and ignore noise or irrelevant knowledge.
As new knowledge is available in, these gates work collectively to mix the outdated and new well. If one thing from earlier within the sequence nonetheless issues, the GRU retains it. If it doesn’t, the GRU lets it go.
This steadiness helps it be taught patterns throughout time with out getting overwhelmed.
In comparison with LSTMs (Lengthy Quick-Time period Reminiscence), which use three gates and a extra complicated reminiscence construction, GRUs are lighter and sooner. They don’t want as many parameters and are often faster to coach.
GRUs carry out simply as effectively in lots of instances, particularly when the dataset isn’t huge or overly complicated. That makes them a strong selection for a lot of deep studying duties involving sequences.
Total, GRUs provide a sensible mixture of energy and ease. They’re designed to seize important patterns in sequential knowledge with out overcomplicating issues, which is a top quality that makes them efficient and environment friendly in real-world use.
GRU Equations and Functioning
A GRU cell makes use of just a few key equations to determine what data to maintain and what to discard because it strikes by a sequence. GRU blends outdated and new data primarily based on what the gates determine. This permits it to retain sensible context over lengthy sequences, serving to the mannequin perceive dependencies that stretch throughout time.
GRU Diagram
Benefits and Limitations of GRUs
Benefits
- GRUs have a repute for being each easy and efficient.
- One in every of their greatest strengths is how they deal with reminiscence. They’re designed to carry on to the essential stuff from earlier in a sequence, which helps when working with knowledge that unfolds over time, like language, audio, or time collection.
- GRUs use fewer parameters than a few of their counterparts, particularly LSTMs. With fewer transferring components, they practice faster and wish much less knowledge to get going. That is nice when brief on computing energy or working with smaller datasets.
- Additionally they are likely to converge sooner. Meaning the coaching course of often takes much less time to achieve an excellent stage of accuracy. When you’re in a setting the place quick iteration issues, this is usually a actual profit.
Limitations
- In duties the place the enter sequence could be very lengthy or complicated, they might not carry out fairly in addition to LSTMs. LSTMs have an additional reminiscence unit that helps them cope with these deeper dependencies extra successfully.
- GRUs additionally wrestle with very lengthy sequences. Whereas they’re higher than easy RNNs, they’ll nonetheless lose observe of knowledge earlier within the enter. That may be a problem in case your knowledge has dependencies unfold far aside, like the start and finish of an extended paragraph.
So, whereas GRUs hit a pleasant steadiness for a lot of jobs, they’re not a common repair. They shine in light-weight, environment friendly setups, however would possibly fall brief when the duty calls for extra reminiscence or nuance.
Purposes of GRUs in Actual-World Eventualities
Gated Recurrent Models (GRUs) are being broadly utilized in a number of real-world purposes attributable to their potential to course of sequential knowledge.
- In pure language processing (NLP), GRUs assist with duties like machine translation and sentiment evaluation.
- These capabilities are particularly related in sensible NLP initiatives like chatbots, textual content classification, or language technology, the place the flexibility to know and reply to sequences meaningfully performs a central position.
- In time collection forecasting, GRUs are particularly helpful for predicting traits. Suppose inventory costs, climate updates, or any knowledge that strikes in a timeline
- GRUs can choose up on the patterns and assist make sensible guesses about what’s coming subsequent.
- They’re designed to hold on to only the correct amount of previous data with out getting slowed down, which helps keep away from widespread coaching points.
- In voice recognition, GRUs assist flip spoken phrases into written ones. Since they deal with sequences effectively, they’ll modify to totally different talking kinds and accents, making the output extra dependable.
- Within the medical world, GRUs are getting used to identify uncommon patterns in affected person knowledge, like detecting irregular heartbeats or predicting well being dangers. They’ll sift by time-based information and spotlight issues that docs won’t catch immediately.
GRUs and LSTMs are designed to deal with sequential knowledge by overcoming points like vanishing gradients, however they every have their strengths relying on the scenario.
When to Select GRUs Over LSTMs or Different Fashions
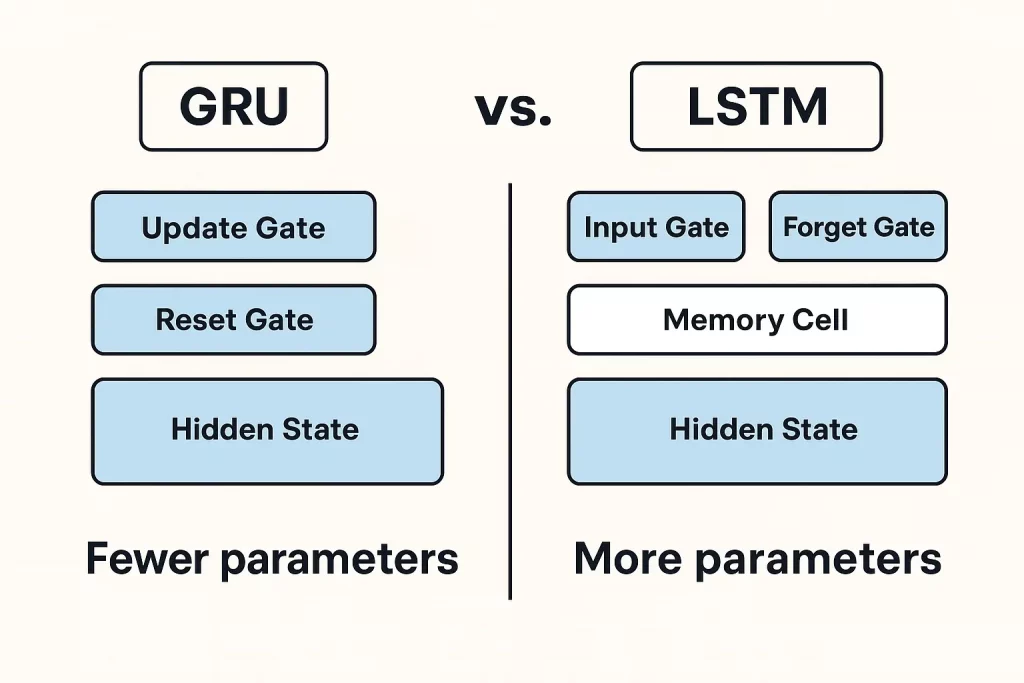
Each GRUs and LSTMs are recurrent neural networks used for the processing of sequences, and are distinguished from one another by each complexity and computational metrics.
Their simplicity, that’s, the less parameters, makes GRUs practice sooner and use much less computational energy. They’re subsequently broadly utilized in use instances the place velocity overshadows dealing with giant, complicated reminiscences, e.g., on-line/stay analytics.
They’re routinely utilized in purposes that demand quick processing, akin to stay speech recognition or on-the-fly forecasting, the place fast operation and never a cumbersome evaluation of knowledge is crucial.
Quite the opposite, LSTMs assist the purposes that may be extremely dependent upon fine-grained reminiscence management, e.g. machine translation or sentiment evaluation. There are enter, overlook, and output gates current in LSTMs that enhance their capability to course of long-term dependencies effectively.
Though requiring extra evaluation capability, LSTMs are typically most popular for addressing these duties that contain in depth sequences and sophisticated dependencies, with LSTMs being skilled at such reminiscence processing.
Total, GRUs carry out finest in conditions the place sequence dependencies are reasonable and velocity is a matter, whereas LSTMs are finest for purposes requiring detailed reminiscence and complicated long-term dependencies, although with a rise in computational calls for.
Way forward for GRU in Deep Studying
GRUs proceed to evolve as light-weight, environment friendly parts in fashionable deep studying pipelines. One main development is their integration with Transformer-based architectures, the place
GRUs are used to encode native temporal patterns or function environment friendly sequence modules in hybrid fashions, particularly in speech and time collection duties.
GRU + Consideration is one other rising paradigm. By combining GRUs with consideration mechanisms, fashions achieve each sequential reminiscence and the flexibility to concentrate on essential inputs.
These hybrids are broadly utilized in neural machine translation, time collection forecasting, and anomaly detection.
On the deployment entrance, GRUs are perfect for edge units and cellular platforms attributable to their compact construction and quick inference. They’re already being utilized in purposes like real-time speech recognition, wearable well being monitoring, and IoT analytics.
GRUs are additionally extra amenable to quantization and pruning, making them a strong selection for TinyML and embedded AI.
Whereas GRUs could not substitute Transformers in large-scale NLP, they continue to be related in settings that demand low latency, fewer parameters, and on-device intelligence.
Conclusion
GRUs provide a sensible mixture of velocity and effectivity, making them helpful for duties like speech recognition and time collection prediction, particularly when sources are tight.
LSTMs, whereas heavier, deal with long-term patterns higher and go well with extra complicated issues. Transformers are pushing boundaries in lots of areas however include increased computational prices. Every mannequin has its strengths relying on the duty.
Staying up to date on analysis and experimenting with totally different approaches, like combining RNNs and a focus mechanisms may also help discover the proper match. Structured packages that mix concept with real-world knowledge science purposes can present each readability and path.
Nice Studying’s PG Program in AI & Machine Studying is one such avenue that may strengthen your grasp of deep studying and its position in sequence modeling.