

{kind=link}
Predicting Ego-centric Video from human Actions (PEVA). Given previous video frames and an motion specifying a desired change in 3D pose, PEVA predicts the following video body. Our outcomes present that, given the primary body and a sequence of actions, our mannequin can generate movies of atomic actions (a), simulate counterfactuals (b), and help lengthy video era (c).
Latest years have introduced vital advances in world fashions that be taught to simulate future outcomes for planning and management. From intuitive physics to multi-step video prediction, these fashions have grown more and more highly effective and expressive. However few are designed for really embodied brokers. With a purpose to create a World Mannequin for Embodied Brokers, we want a actual embodied agent that acts within the actual world. A actual embodied agent has a bodily grounded complicated motion area versus summary management indicators. Additionally they should act in various real-life eventualities and have an selfish view versus aesthetic scenes and stationary cameras.

💡 Tip: Click on on any picture to view it in full decision.
Why It’s Onerous
- Motion and imaginative and prescient are closely context-dependent. The identical view can result in totally different actions and vice versa. It is because people act in complicated, embodied, goal-directed environments.
- Human management is high-dimensional and structured. Full-body movement spans 48+ levels of freedom with hierarchical, time-dependent dynamics.
- Selfish view reveals intention however hides the physique. First-person imaginative and prescient displays targets, however not movement execution, fashions should infer penalties from invisible bodily actions.
- Notion lags behind motion. Visible suggestions usually comes seconds later, requiring long-horizon prediction and temporal reasoning.
To develop a World Mannequin for Embodied Brokers, we should floor our method in brokers that meet these standards. People routinely look first and act second—our eyes lock onto a aim, the mind runs a short visible “simulation” of the result, and solely then does the physique transfer. At each second, our selfish view each serves as enter from the atmosphere and displays the intention/aim behind the following motion. Once we contemplate our physique actions, we should always contemplate each actions of the toes (locomotion and navigation) and the actions of the hand (manipulation), or extra typically, whole-body management.
What Did We Do?

We educated a mannequin to Predict Ego-centric Video from human Actions (PEVA) for Entire-Physique-Conditioned Selfish Video Prediction. PEVA circumstances on kinematic pose trajectories structured by the physique’s joint hierarchy, studying to simulate how bodily human actions form the atmosphere from a first-person view. We practice an autoregressive conditional diffusion transformer on Nymeria, a large-scale dataset pairing real-world selfish video with physique pose seize. Our hierarchical analysis protocol checks more and more difficult duties, offering complete evaluation of the mannequin’s embodied prediction and management skills. This work represents an preliminary try and mannequin complicated real-world environments and embodied agent behaviors by human-perspective video prediction.
Methodology
Structured Motion Illustration from Movement
To bridge human movement and selfish imaginative and prescient, we characterize every motion as a wealthy, high-dimensional vector capturing each full-body dynamics and detailed joint actions. As an alternative of utilizing simplified controls, we encode world translation and relative joint rotations based mostly on the physique’s kinematic tree. Movement is represented in 3D area with 3 levels of freedom for root translation and 15 upper-body joints. Utilizing Euler angles for relative joint rotations yields a 48-dimensional motion area (3 + 15 × 3 = 48). Movement seize information is aligned with video utilizing timestamps, then transformed from world coordinates to a pelvis-centered native body for place and orientation invariance. All positions and rotations are normalized to make sure secure studying. Every motion captures inter-frame movement adjustments, enabling the mannequin to attach bodily motion with visible penalties over time.
Design of PEVA: Autoregressive Conditional Diffusion Transformer
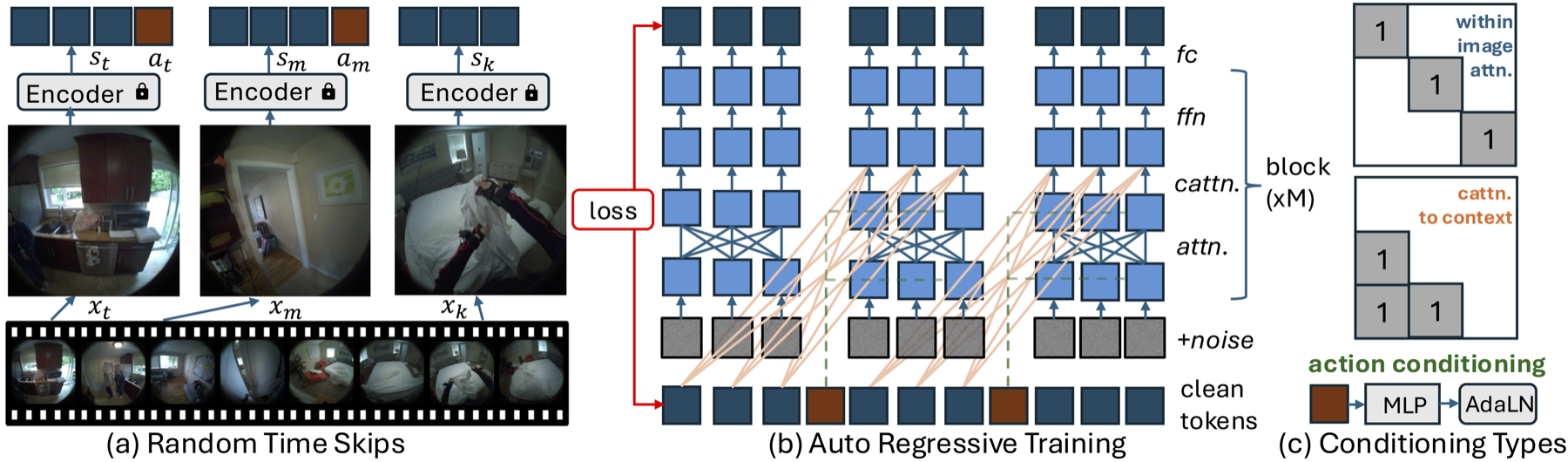
Whereas the Conditional Diffusion Transformer (CDiT) from Navigation World Fashions makes use of easy management indicators like velocity and rotation, modeling whole-body human movement presents better challenges. Human actions are high-dimensional, temporally prolonged, and bodily constrained. To deal with these challenges, we lengthen the CDiT methodology in 3 ways:
- Random Timeskips: Permits the mannequin to be taught each short-term movement dynamics and longer-term exercise patterns.
- Sequence-Stage Coaching: Fashions total movement sequences by making use of loss over every body prefix.
- Motion Embeddings: Concatenates all actions at time t right into a 1D tensor to situation every AdaLN layer for high-dimensional whole-body movement.
Sampling and Rollout Technique
At check time, we generate future frames by conditioning on a set of previous context frames. We encode these frames into latent states and add noise to the goal body, which is then progressively denoised utilizing our diffusion mannequin. To hurry up inference, we prohibit consideration, the place inside picture consideration is utilized solely to the goal body and context cross consideration is just utilized for the final body. For action-conditioned prediction, we use an autoregressive rollout technique. Beginning with context frames, we encode them utilizing a VAE encoder and append the present motion. The mannequin then predicts the following body, which is added to the context whereas dropping the oldest body, and the method repeats for every motion within the sequence. Lastly, we decode the anticipated latents into pixel-space utilizing a VAE decoder.
Atomic Actions
We decompose complicated human actions into atomic actions—akin to hand actions (up, down, left, proper) and whole-body actions (ahead, rotation)—to check the mannequin’s understanding of how particular joint-level actions have an effect on the selfish view. We embrace some samples right here:
Lengthy Rollout
Right here you may see the mannequin’s capacity to keep up visible and semantic consistency over prolonged prediction horizons. We show some samples of PEVA producing coherent 16-second rollouts conditioned on full-body movement. We embrace some video samples and picture samples for nearer viewing right here:


Sequence 1

Sequence 2

Sequence 3
Planning
PEVA can be utilized for planning by simulating a number of motion candidates and scoring them based mostly on their perceptual similarity to the aim, as measured by LPIPS.

On this instance, it guidelines out paths that result in the sink or outside discovering the proper path to open the fridge.

On this instance, it guidelines out paths that result in grabbing close by vegetation and going to the kitchen whereas discovering cheap sequence of actions that result in the shelf.
Allows Visible Planning Capacity
We formulate planning as an vitality minimization downside and carry out motion optimization utilizing the Cross-Entropy Methodology (CEM), following the method launched in Navigation World Fashions [arXiv:2412.03572]. Particularly, we optimize motion sequences for both the left or proper arm whereas holding different physique elements mounted. Consultant examples of the ensuing plans are proven beneath:

On this case, we’re in a position to predict a sequence of actions that raises our proper arm to the blending stick. We see a limitation with our methodology as we solely predict the appropriate arm so we don’t predict to maneuver the left arm down accordingly.

On this case, we’re in a position to predict a sequence of actions that reaches towards the kettle however doesn’t fairly seize it as within the aim.

On this case, we’re in a position to predict a sequence of actions that pulls our left arm in, much like the aim.
Quantitative Outcomes
We consider PEVA throughout a number of metrics to show its effectiveness in producing high-quality selfish movies from whole-body actions. Our mannequin constantly outperforms baselines in perceptual high quality, maintains coherence over very long time horizons, and exhibits sturdy scaling properties with mannequin measurement.
Baseline Perceptual Metrics

Baseline perceptual metrics comparability throughout totally different fashions.
Atomic Motion Efficiency

Comparability of fashions in producing movies of atomic actions.
FID Comparability

FID comparability throughout totally different fashions and time horizons.
Scaling

PEVA has good scaling capacity. Bigger fashions result in higher efficiency.
Future Instructions
Our mannequin demonstrates promising leads to predicting selfish video from whole-body movement, but it surely stays an early step towards embodied planning. Planning is proscribed to simulating candidate arm actions and lacks long-horizon planning and full trajectory optimization. Extending PEVA to closed-loop management or interactive environments is a key subsequent step. The mannequin presently lacks specific conditioning on activity intent or semantic targets. Our analysis makes use of picture similarity as a proxy goal. Future work might leverage combining PEVA with high-level aim conditioning and the mixing of object-centric representations.
Acknowledgements
The authors thank Rithwik Nukala for his assist in annotating atomic actions. We thank Katerina Fragkiadaki, Philipp Krähenbühl, Bharath Hariharan, Guanya Shi, Shubham Tulsiani and Deva Ramanan for the helpful ideas and feedbacks for bettering the paper; Jianbo Shi for the dialogue relating to management idea; Yilun Du for the help on Diffusion Forcing; Brent Yi for his assist in human movement associated works and Alexei Efros for the dialogue and debates relating to world fashions. This work is partially supported by the ONR MURI N00014-21-1-2801.
For extra particulars, learn the full paper or go to the mission web site.