

{kind=link}
Massive AI fashions are scaling quickly, with larger architectures and longer coaching runs turning into the norm. As fashions develop, nonetheless, a elementary coaching stability situation has remained unresolved. DeepSeek mHC instantly addresses this downside by rethinking how residual connections behave at scale. This text explains DeepSeek mHC (Manifold-Constrained Hyper-Connections) and reveals the way it improves giant language mannequin coaching stability and efficiency with out including pointless architectural complexity.
The Hidden Drawback With Residual and Hyper-Connections
Residual connections have been a core constructing block of deep studying because the launch of ResNet in 2016. They permit networks to create shortcut paths, enabling info to circulation instantly by layers as an alternative of being relearned at each step. In easy phrases, they act like specific lanes in a freeway, making deep networks simpler to coach.
This strategy labored effectively for years. However as fashions scaled from thousands and thousands to billions, and now a whole lot of billions of parameters, its limitations grew to become clear. To push efficiency additional, researchers launched Hyper-Connections (HC), successfully widening these info highways by including extra paths. Efficiency improved noticeably, however stability didn’t.
Coaching grew to become extremely unstable. Fashions would practice usually after which abruptly collapse round a selected step, with sharp loss spikes and exploding gradients. For groups coaching giant language fashions, this sort of failure can imply losing large quantities of compute, time, and sources.
What Is Manifold-Constrained Hyper-Connections (mHC)?
It’s a normal framework that maps the residual connection house of HC to a sure manifold to bolster the id mapping property, and on the similar time includes strict infrastructure optimization to be environment friendly.
Empirical assessments present that mHC is nice for large-scale coaching, delivering not solely clear efficiency beneficial properties but in addition glorious scalability. We count on mHC, being a flexible and accessible addition to HC, to help within the comprehension of topological structure design and to suggest new paths for the event of foundational fashions.
What Makes mHC Totally different?
DeepSeek’s technique is not only sensible, it’s good as a result of it causes you to suppose “Oh, why has nobody ever considered this earlier than?” They nonetheless saved Hyper-Connections however restricted them with a exact mathematical methodology.
That is the technical half (don’t surrender on me, it’ll be value your whereas to know): Normal residual connections permit what is called “id mapping” to be carried out. Image it because the legislation of conservation of vitality the place indicators are touring by the community achieve this on the similar energy degree. When HC elevated the width of the residual stream and mixed it with learnable connection patterns, they unintentionally violated this property.
DeepSeek’s researchers comprehended that HC’s composite mappings, primarily, when you retain stacking these connections layer upon layer, had been boosting indicators by multipliers of 3000 instances or much more. Image it that you just stage a dialog and each time somebody communicates your message, the entire room directly yells it 3000 instances louder. That’s nothing however chaos.
mHC solves the issue by projecting these connection matrices onto the Birkhoff polytope, an summary geometric object by which every row and column has a sum equal to 1. It could seem theoretical, however in actuality, it makes the community to deal with sign propagation as a convex mixture of options. No extra explosions, no extra indicators disappearing utterly.
The Structure: How mHC Really Works
Let’s discover the main points of how DeepSeek modified the connections throughout the mannequin. The design is dependent upon three main mappings that decide the route of the data:
The Three-Mapping System
In Hyper-Connections, three learnable matrices carry out completely different duties:
- H_pre: Takes the data from the prolonged residual stream into the layer
- H_post: Sends the output of the layer again to the stream
- H_res: Combines and refreshes the data within the stream itself
Visualize it as a freeways system the place H_pre is the doorway ramp, H_post is the exit ramp, and H_res is the visitors circulation supervisor among the many lanes.
One of many findings of DeepSeek’s ablation research is very attention-grabbing – H_res (the mapping utilized to the residuals) is the principle contributor to the efficiency enhance. They turned it off, permitting solely pre and submit mappings, and efficiency dramatically dropped. That is logical: the spotlight of the method is when options from completely different depths get to work together and swap info.
The Manifold Constraint
That is the purpose the place mHC begins to deviate from common HC. Somewhat than permitting H_res to be picked arbitrarily, they impose it to be doubly stochastic, which is a attribute that each row and each column sums to 1.
What’s the significance of this? There are three key causes:
- Norms are saved intact: The spectral norm is saved throughout the limits of 1, thus gradients can’t explode.
- Closure beneath composition: Doubling up on doubly stochastic matrices leads to one other doubly stochastic matrix; therefore, the entire community depth remains to be steady.
- An illustration when it comes to geometry: The matrices are within the Birkhoff polytope, which is the convex hull of all permutation matrices. To place it in a different way, the community learns weighted combos of routing patterns the place info flows in a different way.
The Sinkhorn-Knopp algorithm is the one used for implementing this constraint, which is an iterative methodology that retains normalizing rows and columns alternately until the specified accuracy is reached. Within the experiments, it was established that 20 iterations yield an apt approximation with no extreme computation.
Parameterization Particulars
The execution is wise. As a substitute of engaged on single characteristic vectors, mHC compresses the entire n×C hidden matrix into one vector. This permits for the entire context info for use within the dynamic mapping’s computation.
The final constrained mappings apply:
- Sigmoid activation for H_pre and H_post (thus guaranteeing non-negativity)
- Sinkhorn-Knopp projection for H_res (thereby implementing double stochasticity)
- Small initialization values (α = 0.01) for gating components to start with conservative
This configuration stops sign cancellation attributable to interactions between positive-negative coefficients and on the similar time retains the crucial id mapping property.
Scaling Conduct: Does It Maintain Up?
Probably the most superb issues is how the advantages of mHC scale. DeepSeek carried out their experiments in three completely different dimensions:
- Compute Scaling: They educated to 3B, 9B, and 27B parameters with proportional information. The efficiency benefit remained the identical and even barely elevated at larger budgets for the compute. That is unbelievable as a result of often, many architectural methods which work at small-scale don’t work when scaling up.
- Token Scaling: They monitored the efficiency all through the coaching of their 3B mannequin educated on 1 trillion tokens. The loss enchancment was steady from very early coaching to the convergence stage, indicating that mHC’s advantages are usually not restricted to the early-training interval.
- Propagation Evaluation: Do you recall these 3000x sign amplification components in vanilla HC? With mHC, the utmost achieve magnitude was diminished to round 1.6 being three orders of magnitude extra steady. Even after composing 60+ layers, the ahead and backward sign beneficial properties remained well-controlled.
Efficiency Benchmarks
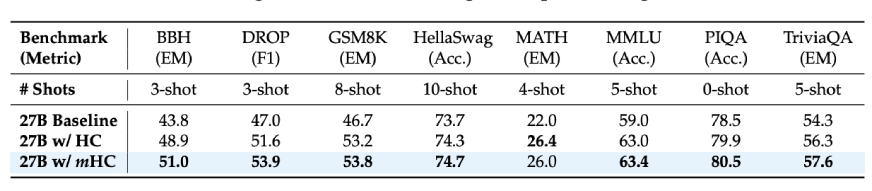
DeepSeek evaluated mHC on completely different fashions with parameter sizes various from 3 billion to 27 billion and the steadiness beneficial properties had been significantly seen:
- Coaching loss was easy through the entire course of with no sudden spikes
- Gradient norms had been saved in the identical vary, in distinction to HC, which displayed wild behaviour
- Probably the most vital factor was that the efficiency not solely improved but in addition proven throughout a number of benchmarks
If we contemplate the outcomes of the downstream duties for the 27B mannequin:
- BBH reasoning duties: 51.0% (vs. 43.8% baseline)
- DROP studying comprehension: 53.9% (vs. 47.0% baseline)
- GSM8K math issues: 53.8% (vs. 46.7% baseline)
- MMLU data: 63.4% (vs. 59.0% baseline)
These don’t characterize minor enhancements however in actual fact, we’re speaking about 7-10 level will increase on troublesome reasoning benchmarks. Moreover, these enhancements weren’t solely seen as much as the bigger fashions but in addition throughout longer coaching durations, which was the case with the scaling of the deep studying fashions.
Additionally Learn: DeepSeek-V3.2-Exp: 50% Cheaper, 3x Quicker, Most Worth
Conclusion
In case you are engaged on or coaching giant language fashions, mHC is a facet that you must undoubtedly contemplate. It’s a type of papers that uncommon, which identifies an actual situation, presents a mathematically legitimate resolution, and even proves that it really works at a big scale.
The most important revelations are:
- Growing residual stream width results in higher efficiency; nonetheless, naive strategies trigger instability
- Limiting interactions to doubly stochastic matrices retain the id mapping properties
- If finished proper, the overhead might be barely noticeable
- The benefits might be reapplied to fashions with a measurement of tens of billions of parameters
Furthermore, mHC is a reminder that the architectural design remains to be a vital issue. The problem of use extra compute and information can’t final perpetually. There will likely be instances when it’s essential to take a step again, comprehend the rationale for the failure on the giant scale, and repair it correctly.
And to be trustworthy, such analysis is what I like most. Not little modifications to be made, however somewhat profound modifications that can make the whole area slightly extra strong.
Gen AI Intern at Analytics Vidhya
Division of Pc Science, Vellore Institute of Know-how, Vellore, India
I’m at the moment working as a Gen AI Intern at Analytics Vidhya, the place I contribute to progressive AI-driven options that empower companies to leverage information successfully. As a final-year Pc Science scholar at Vellore Institute of Know-how, I convey a stable basis in software program improvement, information analytics, and machine studying to my position.
Be at liberty to attach with me at [email protected]
Login to proceed studying and revel in expert-curated content material.