

{kind=link}
I’ve been fascinated by the fast evolution of AI brokers. Over the previous yr, I’ve watched them develop from easy chatbots into subtle techniques that may cause by advanced issues, make choices, and preserve context throughout lengthy conversations. But an agent is barely pretty much as good as its reminiscence.
On this put up we present you tips on how to construct production-ready AI brokers with sturdy state administration utilizing Amazon DynamoDB and LangGraph with the brand new DynamoDBSaver connector, a LangGraph checkpoint library maintained by AWS for Amazon DynamoDB. It offers a production-ready persistence layer constructed particularly for DynamoDB and LangGraph that shops agent state with clever dealing with of payloads primarily based on their dimension.
You’ll learn the way this implementation can provide your brokers the persistence they should scale, recuperate from failures, and preserve long-running workflows.
A fast have a look at Amazon DynamoDB
Amazon DynamoDB is a serverless, totally managed, distributed NoSQL database with single-digit millisecond efficiency at any scale. You may retailer structured or semi-structured knowledge, question it with constant millisecond latency, and scale mechanically with out managing servers or infrastructure.As a result of DynamoDB is constructed for low latency and excessive availability, it’s typically used to retailer session knowledge, person profiles, metadata, or utility state. These identical qualities make it a perfect alternative for storing checkpoints and thread metadata for AI brokers.
Introducing LangGraph
LangGraph is an open supply framework from LangChain designed for constructing advanced, graph-based AI workflows. As a substitute of chaining prompts and capabilities in a straight line, LangGraph enables you to outline nodes that may department, merge, and loop. Every node performs a job, and edges management the stream between them.
LangGraph introduces a number of key ideas:
- Threads: A thread is a singular identifier assigned to every checkpoint that incorporates the amassed state of a sequence of runs. When a graph executes, its state persists to the thread, which requires specifying a thread_id within the config (
{"configurable": {"thread_id": "1"}}). Threads should be created earlier than execution to persist state. - Checkpoints: A checkpoint is a snapshot of the graph state saved at every super-step, represented by a StateSnapshot object containing config, metadata, state channel values, subsequent nodes to execute, and job info (together with errors and interrupt knowledge). Checkpoints are persevered and might restore thread state later. For instance, a easy two-node graph creates 4 checkpoints: an empty checkpoint at
START, one with person enter earlier than node_a, one with node_a’s output earlier than node_b, and a last one with node_b’s output atEND. - Persistence: Persistence determines the place and the way checkpoints are saved (similar to, in-memory, database, or exterior storage) utilizing a checkpointer implementation. The checkpointer saves thread state at every super-step and permits retrieval of historic states, permitting graphs to renew from checkpoints or restore earlier execution states.
Persistence is what permits superior options similar to human-in-the-loop overview, replay, resumption after failure, and time journey between states.
InMemorySaver is LangGraph’s built-in checkpointing mechanism that shops dialog state and graph execution historical past in reminiscence, enabling options like persistence, time-travel debugging, and human-in-the-loop workflows. You need to use InMemorySaver for quick prototyping, state exists solely in reminiscence and is misplaced when your utility restarts.
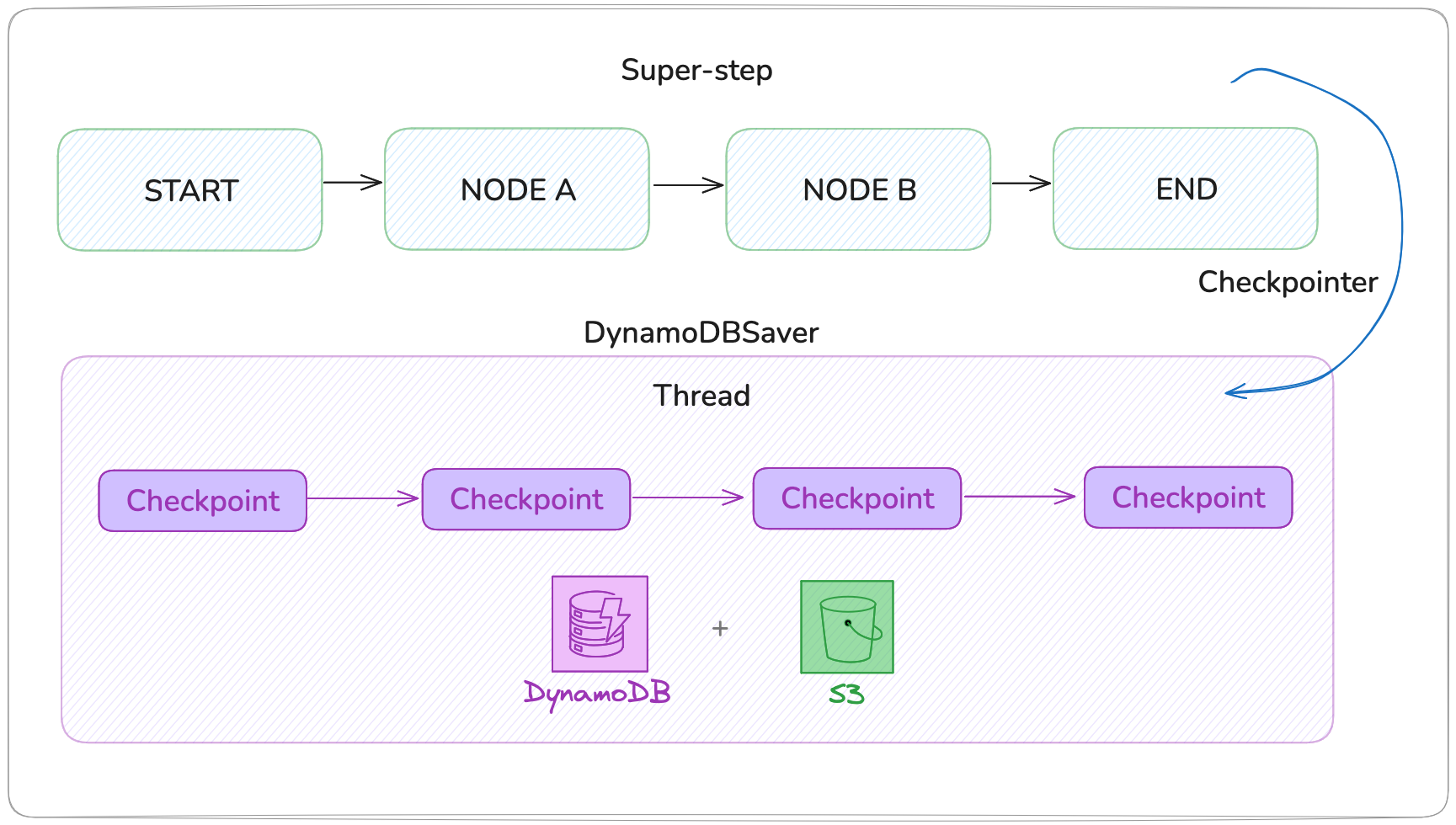
The next picture reveals LangGraph’s checkpointing structure, the place a high-level workflow (super-step) executes by nodes from START to END whereas a checkpointer repeatedly saves state snapshots to reminiscence (InMemorySaver):
Why persistence issues
By default, LangGraph shops checkpoints in reminiscence utilizing the InMemorySaver. That is nice for experimentation as a result of it requires no setup and gives immediate learn and write entry.
Nonetheless, in reminiscence storage has two main limitations. It’s ephemeral and native. When the method stops, the information is misplaced. In case you run a number of employees, every occasion retains its personal reminiscence. You can’t resume a session that began elsewhere, and you can not recuperate if a workflow crashes midway.
For manufacturing environments, this isn’t acceptable. You want a persistent, fault-tolerant retailer that permits brokers to renew the place they left off, scale throughout nodes, and retain historical past for evaluation or audit. That’s the place the DynamoDBSaver is available in.
Think about a situation the place you’re constructing a buyer help agent that handles advanced, multi-step inquiries. A buyer asks about their order, the agent retrieves info, generates a response, and waits for human approval earlier than sending a response.
However what occurs when:
- Your server occasions out mid-workflow?
- It’s worthwhile to scale to a number of employees?
- The shopper comes again hours later to proceed the dialog?
- You need to audit the agent’s decision-making course of?
With in-memory storage, you’re out of luck. The second your course of stops, all the pieces vanishes. Every employee maintains its personal remoted state. There’s no technique to resume, replay, or overview what occurred.
Introducing DynamoDBSaver
The langgraph-checkpoint-aws library offers a persistence layer constructed particularly for AWS. DynamoDBSaver shops light-weight checkpoint metadata in DynamoDB and makes use of Amazon S3 for big payloads.
Right here is the way it works:
- Small checkpoints (< 350 KB): Saved instantly in DynamoDB as serialized gadgets with metadata like
thread_id,checkpoint_id, timestamps, and state - Massive checkpoints (≥ 350 KB): State is uploaded to S3, and DynamoDB shops a reference pointer to the S3 object
- Retrieval: When resuming, the saver fetches metadata from DynamoDB and transparently hundreds massive payloads from S3
This design offers sturdiness, scalability, and environment friendly dealing with of each small and enormous states with out hitting the DynamoDB merchandise dimension restrict.
DynamoDBSaver consists of built-in options that can assist you handle prices and knowledge lifecycle:
- Time-to-Reside (
ttl_seconds) permits computerized expiration of checkpoints at specified intervals. Outdated thread states are cleaned up with out handbook intervention, supreme for non permanent workflows, testing environments, or functions the place a historic state past a sure age has no worth. - Compression (
enable_checkpoint_compression) reduces checkpoint dimension earlier than storage by serializing and compressing state knowledge, which lowers each DynamoDB write prices and S3 storage prices whereas sustaining full state constancy upon retrieval.
Collectively, these options assist present fine-grained management over your persistence layer’s operational prices and storage footprint, permitting you to stability sturdiness necessities with price range constraints as your utility scales.
Getting began
Let’s construct a sensible instance displaying tips on how to persist agent state throughout executions and retrieve historic checkpoints.
Conditions
Earlier than we start, you’ll have to arrange the required AWS assets:
- DynamoDB desk: The
DynamoDBSaverrequires a desk to retailer checkpoint metadata. The desk will need to have a partition key named PK (String) and a form key named SK (String). - S3 bucket (optionally available): In case your checkpoints could exceed 350 KB, present an S3 bucket for big payload storage. The saver will mechanically route outsized states to S3 and retailer references in DynamoDB.
You need to use the AWS Cloud Growth Package (AWS CDK) to outline these assets:
Your utility wants the next AWS Identification and Entry Administration (AWS IAM) permissions to make use of DynamoDBSaver as LangGraph checkpoint storage:
DynamoDB Desk Entry:
dynamodb:GetItem– Retrieve particular person checkpointsdynamodb:PutItem– Retailer new checkpointsdynamodb:Question– Seek for checkpoints by thread IDdynamodb:BatchGetItem– Retrieve a number of checkpoints effectivelydynamodb:BatchWriteItem– Retailer a number of checkpoints in a single operation
S3 Object Operations (for checkpoints bigger than 350KB):
s3:PutObject– Add checkpoint knowledges3:GetObject– Retrieve checkpoint knowledges3:DeleteObject– Take away expired checkpointss3:PutObjectTagging– Tag objects for lifecycle administration
S3 Bucket Configuration:
s3:GetBucketLifecycleConfiguration– Learn lifecycle guideliness3:PutBucketLifecycleConfiguration– Configure computerized knowledge expiration
Set up
Set up LangGraph and the AWS checkpoint storage library utilizing pip:
Fundamental setup
Configure the DynamoDB checkpoint saver together with your desk and optionally available S3 bucket for big checkpoints:
Constructing the workflow
Create your graph and compile it with the checkpointer to allow persistent state throughout invocations:
Acquiring state
Retrieve the present state or entry earlier checkpoints for time-travel debugging:
Actual-world use instances
1. Human-in-the-loop overview
For delicate operations (monetary transactions, authorized paperwork, medical recommendation), you possibly can pause workflows for human oversight:
2. Failure restoration
In manufacturing techniques, failures occur. Community interruptions, API timeouts, or transient errors can cease execution mid-way.
With in-memory checkpoints, you lose progress. With DynamoDBSaver, the workflow can question the final profitable checkpoint and resume from there. This helps cut back re-computation, pace up restoration, and enhance reliability.
3. Lengthy-running conversations
Some workflows span hours or days. The sturdiness of DynamoDB makes certain conversations persist:
Transferring from prototype to manufacturing is so simple as altering your checkpointer. Substitute MemorySaver with DynamoDBSaver to achieve persistent, scalable state administration:
Clear up
To keep away from incurring ongoing expenses, delete the assets you created:
In case you used AWS CDK to deploy, run the next command:
In case you used the CLI, run the next instructions:
- Delete the DynamoDB desk:
- Empty and delete the Amazon S3 bucket:
Conclusion
LangGraph makes it simple to construct clever, stateful brokers. DynamoDBSaver makes it protected to run them in manufacturing.
By integrating DynamoDBSaver into your LangGraph functions, you possibly can achieve sturdiness, scalability, and the power to renew advanced workflows from a particular cut-off date. You may construct techniques that contain human oversight, preserve long-running classes, and recuperate gracefully from interruptions.
Get Began Right this moment
Begin with in-memory checkpoints whereas prototyping. While you’re able to go reside, change to DynamoDBSaver and let your brokers bear in mind, recuperate, and scale with confidence. Set up the library with pip set up langgraph-checkpoint-aws.
Study extra in regards to the DynamoDBSaver on the langgraph-checkpoint-aws documentation to see the obtainable configuration choices.
For manufacturing workloads, think about internet hosting your LangGraph brokers utilizing Amazon Bedrock AgentCore Runtime. AgentCore offers a totally managed runtime atmosphere that handles scaling, monitoring, and infrastructure administration, permitting you to concentrate on constructing agent logic whereas AWS manages the operational complexity.
In regards to the authors