
 – Half 2")
{kind=link}
It is a visitor weblog by Arthur Bigeard, Founder at gdotv, in partnership with Charles Ivie, Sr Graph Architect at AWS.
G.V() is a graph database IDE obtainable for Desktop or on AWS Market, providing intensive graph visualization and querying capabilities for Amazon Neptune and Neptune Analytics.
In Half 1 of this collection, we demonstrated design, construct and cargo a Labeled Property Graph (LPG) mannequin into Amazon Neptune utilizing Graph.Construct.
Highly effective exploration of an Amazon Neptune graph is important for locating insights.
On this publish, we present you join G.V() to our Neptune cluster, enabling highly effective no-code exploration, querying, and evaluation to find useful insights on the ingested graph information.
This publish is meant for anybody seeking to change into acquainted with graph information. Prior data of openCypher or Gremlin is just not required, and pattern queries are supplied with explanations.
Resolution overview
Amazon Neptune clusters are all the time deployed inside a Digital Non-public Cloud (VPC) for community isolation. For connectivity, both prohibit entry to inside the VPC or allow a Neptune Public Endpoint for entry over the Web. When a public endpoint is used, enabling IAM database authentication is obligatory for safety.
The next structure exhibits a Neptune cluster configured for personal entry inside its VPC.
A Neptune cluster is a group of situations, with the minimal quantity being 1. Situations may be serverless for on-demand vertical computerized scaling, or distinct occasion varieties. The first occasion acts as the only author occasion, and horizontal scalability is on the market for learn operations by creating extra learn duplicate situations.
G.V() is deployed to an Amazon Elastic Compute Cloud (Amazon EC2) occasion in the identical VPC as Neptune. Safety teams are used to configure community communication permissions between elements within the VPC, in addition to inbound to the VPC from outdoors AWS.
G.V() acts as a consumer utility and connects to Neptune by its cluster endpoint. G.V() begins an internet server that accepts incoming site visitors on port 443, utilizing a self-signed TLS certificates. The high-level implementation steps are as follows:
- Deploy G.V() on Amazon EC2.
- Configure G.V() to hook up with Neptune.
- Search and discover the information utilizing G.V().
Prospects are answerable for the prices of operating the answer. On AWS market, there’s a price for each the Amazon EC2 occasion, and G.V() for the precise occasion sort. For this publish, we suggest utilizing a t3.giant EC2 occasion, so the prices shall be as follows.
Examples are taken from the us-east-1 area
|
G.V() – EC2 t3.giant |
14-days free trial, then $0.64 per hour |
|
AWS – EC2 t3.giant |
$0.0832 per hour |
Stipulations
A operating Amazon Neptune database cluster with information already loaded is required to finish this information. The primary a part of this collection particulars create a Neptune cluster, design and construct a graph mannequin, and cargo it into Amazon Neptune with no code, utilizing Graph.Construct.
Deploy G.V() on Amazon EC2
To deploy G.V() on Amazon EC2, full the next steps:
- Register for a free 2-week G.V() trial on AWS Market by selecting Attempt at no cost.
- Settle for the phrases and situations of the supply and robotically create an settlement, and the free trial will begin. This course of would possibly take as much as a few minutes.
- Select Proceed to Configuration and select the identical AWS Area the Neptune cluster is deployed to.
- Select Proceed to Launch, then beneath Select Motion, select Launch by EC2, and select Launch once more.
Launching by Amazon EC2 presents flexibility with configuration of safety group guidelines and AWS Identification and Entry Administration (IAM) authentication.
The next is a abstract of deployment directions. For a full step-by-step information, confer with the G.V() deployment information.
- To configure communication between G.V() and Neptune, present the VPC that Neptune is operating in.
- Select a t3.giant occasion dimension for G.V().
- If utilizing IAM authentication on the Neptune cluster, we suggest configuring authentication from G.V() by way of an EC2 occasion profile following our documentation.
- Outline the safety group permissions for the G.V() occasion. Guarantee entry to port 443 is enabled in your IP vary at minimal.
- Configure no less than 8 GB of storage for the EC2 occasion.
- Go away different Amazon EC2 configuration parameters as their default values.
- Select Launch Occasion. G.V() must be deployed and able to use inside 5 minutes.
- Pay attention to the EC2 occasion’s ID and public IPv4 DNS.
- Navigate to the general public IPv4 DNS of the deployed EC2 occasion.
As a result of G.V() makes use of a self-signed TLS certificates by default, it must be explicitly trusted in your browser. To configure another, trusted certificates, see Configuring a TLS certificates.
To authenticate to G.V(), enter the next credentials:
For Username, gdotv.
For Password, enter the EC2 occasion ID.
G.V() is now prepared to make use of with Neptune.
Configure G.V() to hook up with Neptune
You possibly can hook up with Neptune by following these three steps:
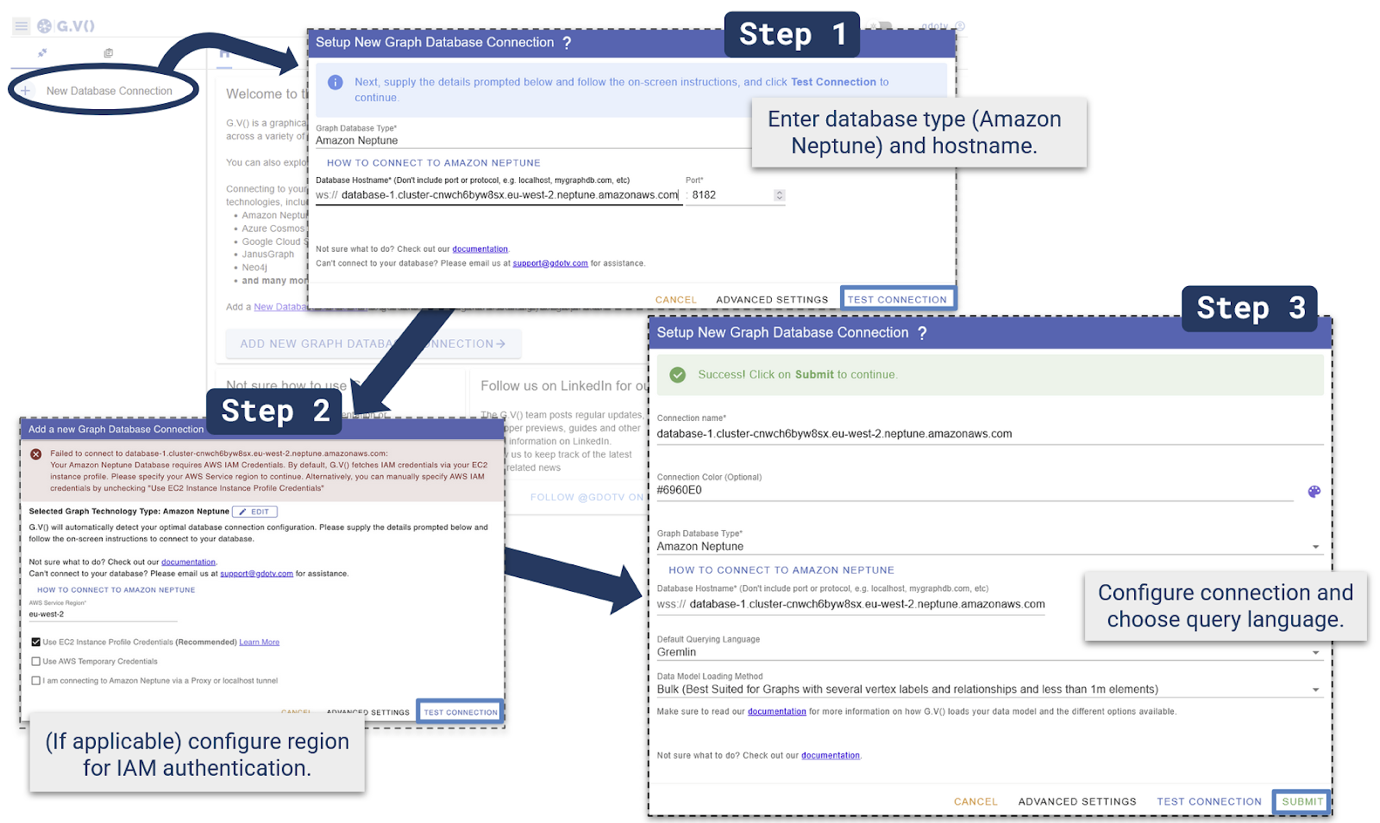
Step 1 – Add connection particulars
Select New Database Connection, Amazon Neptune and enter the Neptune cluster hostname, it appears to be like like the next:
Take a look at Connection
Step 2 – (If relevant) configure IAM authentication
If an EC2 occasion profile is configured, it will likely be used robotically – in any other case enter AWS IAM credentials manually and check the connection.
If this step fails, this means a misconfiguration. Confer with the G.V documentation for EC2 occasion and IAM configuration.
Step 3 – Configure connection
>For Default Querying Language, select Gremlin. Configure different components, just like the connection identify and connection shade if desired, then Submit.
Now you can question the Neptune cluster on G.V() to visualise and discover the graph information created throughout Half 1.
First checks and high quality management inside G.V()
Run the next question.
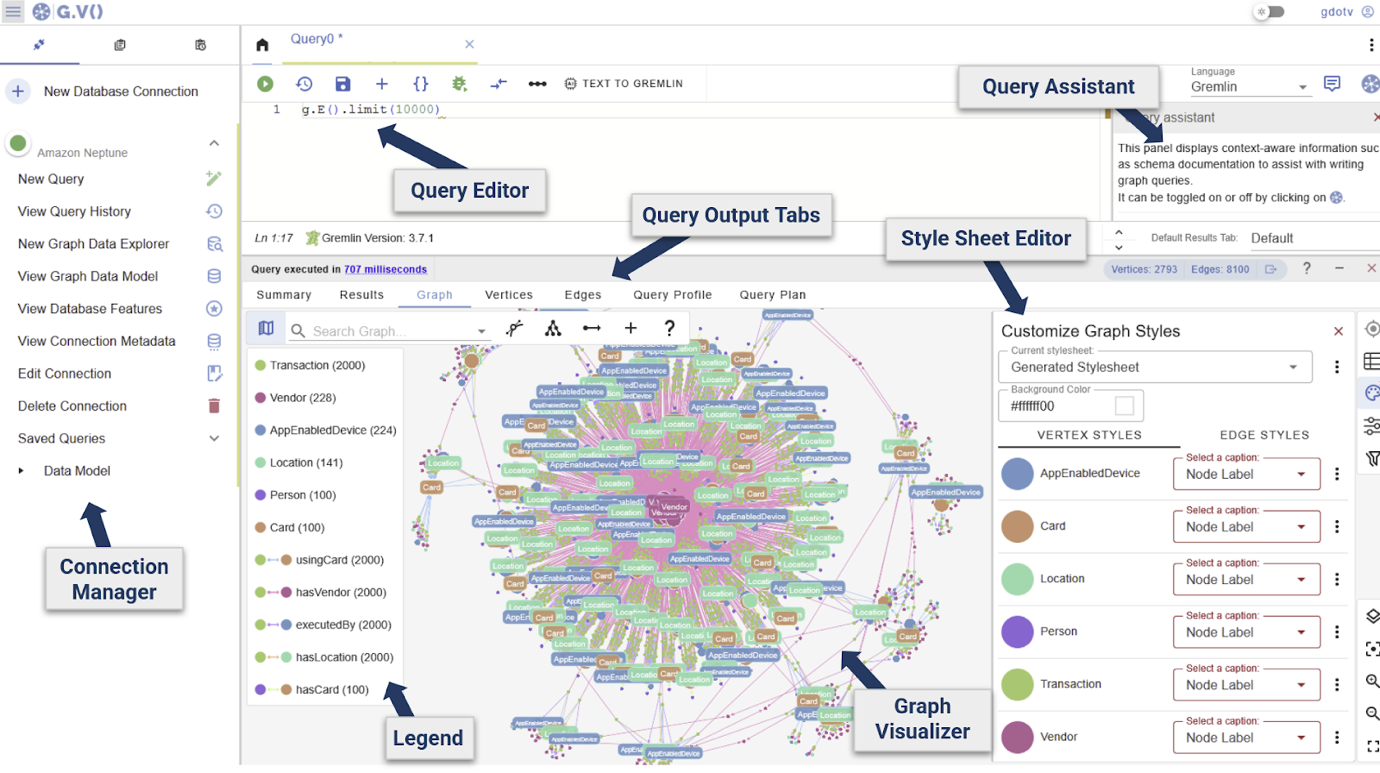
Discover the completely different visible elements exhibiting a pattern of the graph information ingested throughout Half 1.
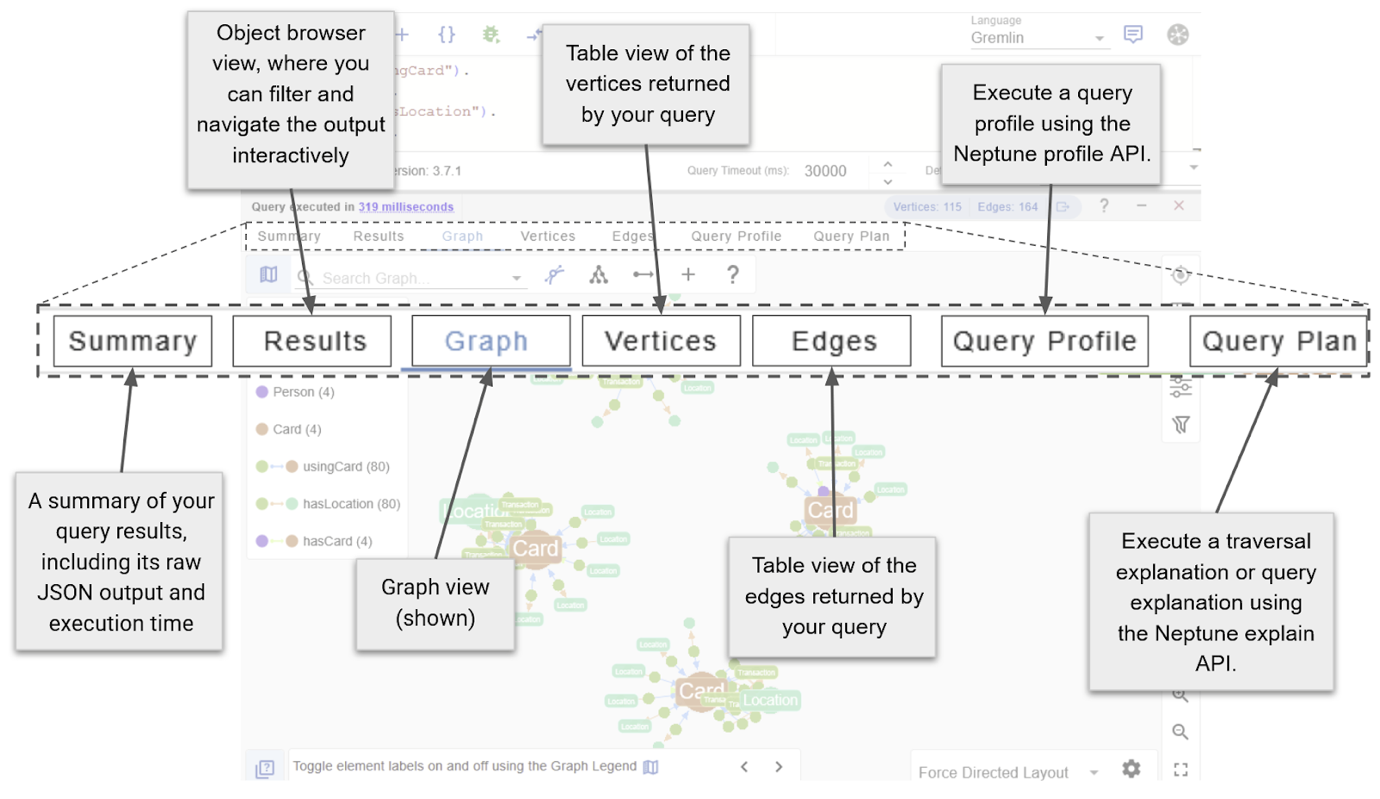
There are three important exploration views, every of which may be opened from the Connection Supervisor, highlighted above.
- Question Editors (earlier picture) – Write and execute a Gremlin, Cypher, or SPARQL queries.
- Graph Information Explorers – Discover information utilizing path definitions and filters, with out the necessity to write a question.
- Graph Information Mannequin views – Graph information schema as an entity-relationship diagram.
The graph is opened within the Question Editor view by default and is suited to conventional query-based checks in Gremlin, Cypher, or SPARQL for RDF graphs.
For broader validation, the Information Mannequin supplies a common overview of the graph schema, whereas the Information Explorer returns visible outcomes and a technique for navigation with out the necessity to manually write code.
Use the Information Mannequin and Information Explorer to reply questions like “How are Card nodes linked to with Location nodes?” or “Which Card nodes have hyperlinks to this explicit Location node?” respectively.
For a reference on use the Graph Information Explorer view or the Information Mannequin view, see the next cheat sheet:
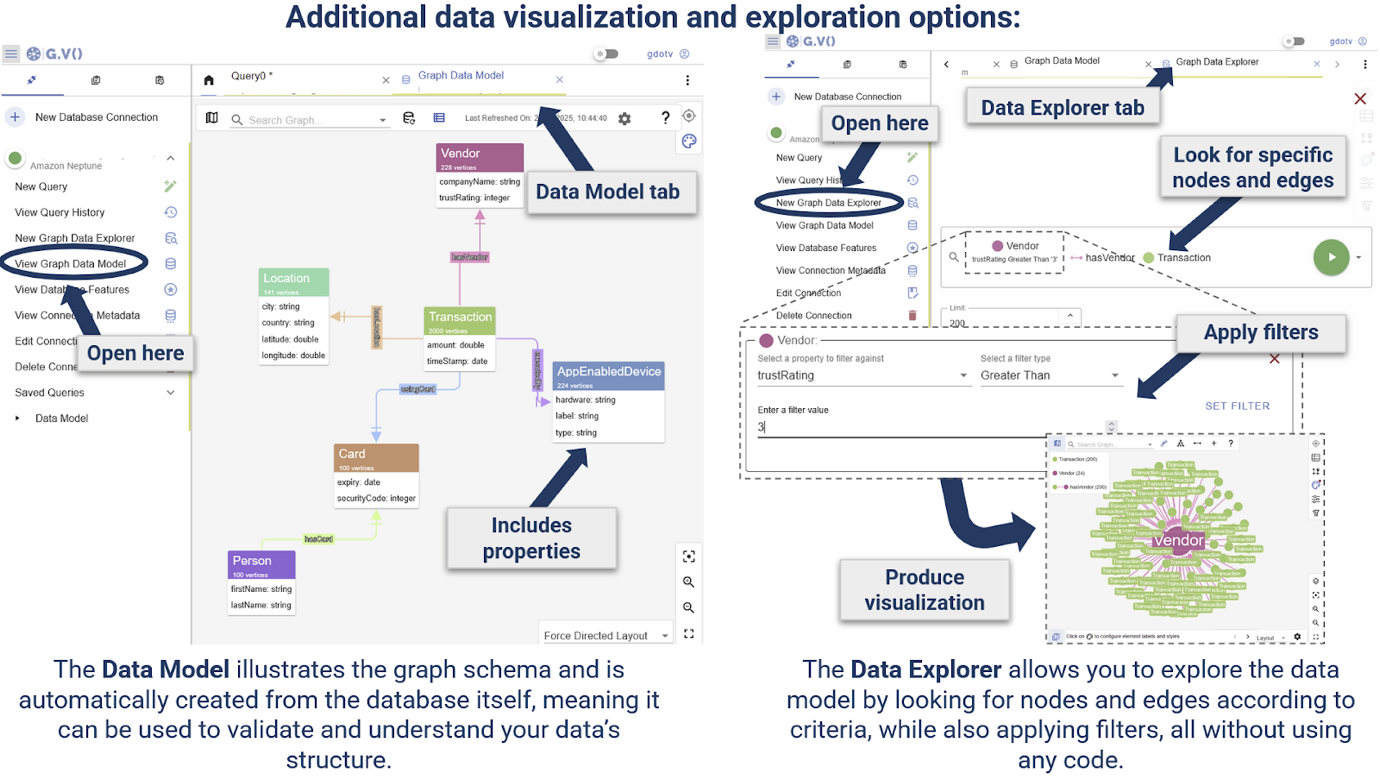
You possibly can organise a number of situations or combos of those views into tabs.Select View Graph Information Mannequin.
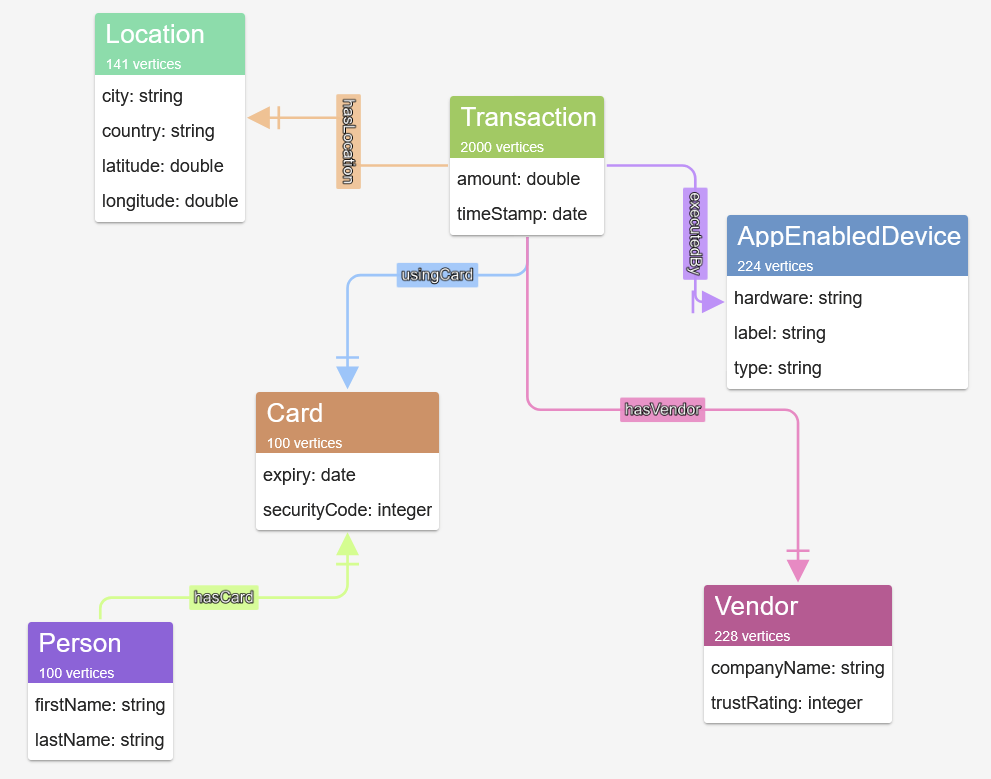
Examine the schema that has been inferred from the graph by G.V().
We will see numerous nodes together with Individual, Card and Transaction nodes, edges and properties.
This provides an outline of the information construction and validates that the ingested information construction matches the schema outlined in Half 1. As a result of the Information Mannequin is generated immediately from the graph, it supplies a powerful validation examine that the graph schema is behaving as supposed.
Uncovering insights from the dataset
You possibly can question Neptune property graphs utilizing Gremlin and Cypher. We use Gremlin within the following examples.
When operating a question, numerous information output codecs organized into tabs can be found to discover the question outcomes. Select Graph View
Execute the next question, to seek for a consumer particular person with the identify ‘Eve Homenick’ and return their linked playing cards and transactions.
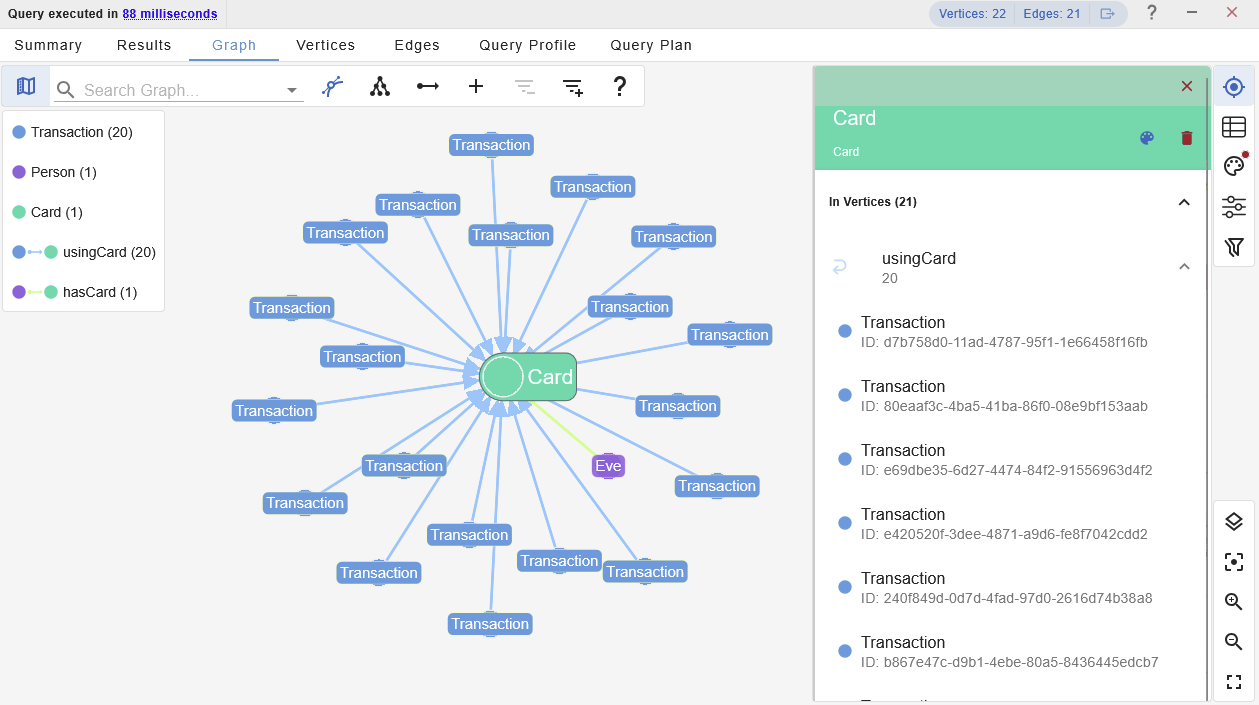
Select the Card node to discover the related neighbours in additional element. On this case, itemizing the In Vertices is all we have to produce an itemized checklist of related transactions.
This may very well be helpful if this consumer is beneath investigation, as both a sufferer, or perpetrator, of fraudulent transactions.
When searching for fraud, investigators could have to run the identical question repeatedly, passing in values reminiscent of they Individual’s identify as parameters.
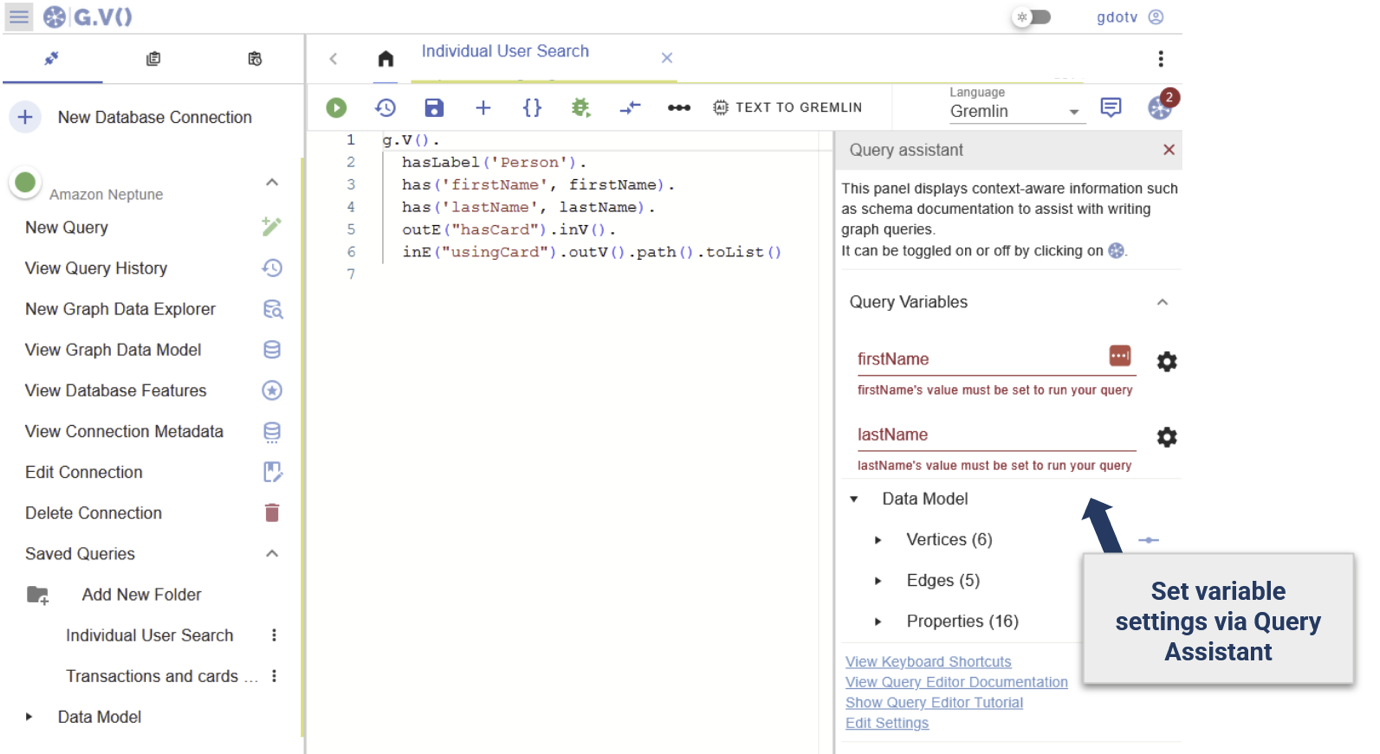
Assume the investigator needed to take a look at a unique particular person. Set parameters as variables for firstName and lastName.
G.V()’s question assistant will robotically detect them and immediate for the parameter values:
Save the question for later entry:
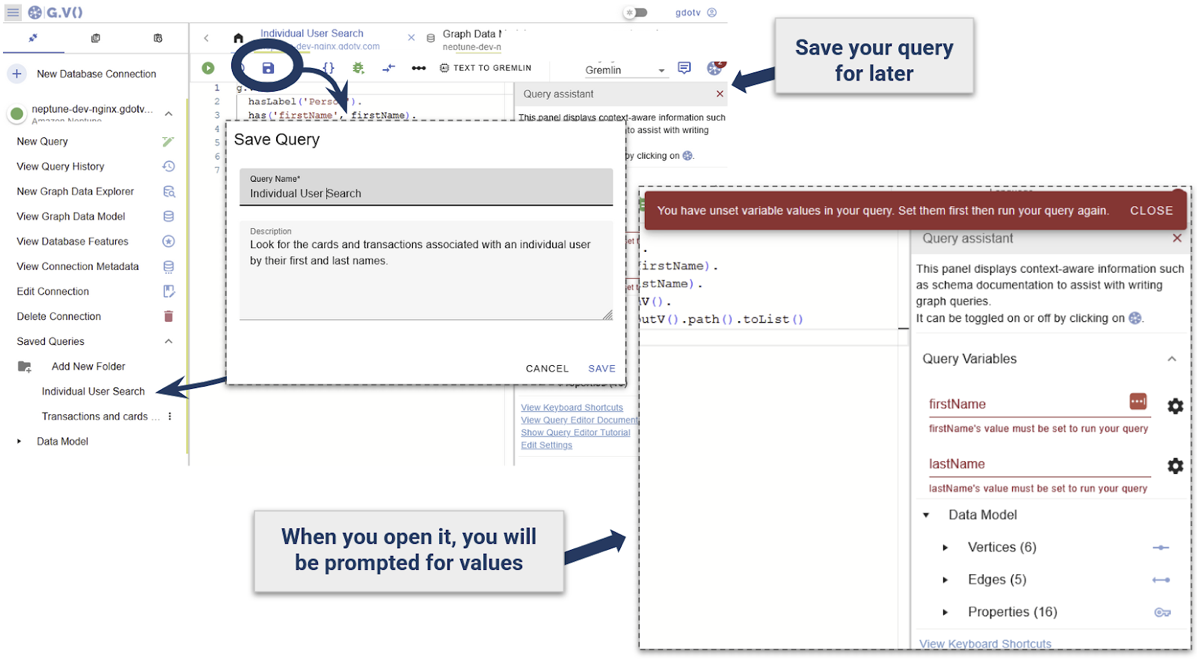
When saving a question with customized parameters like this, they are going to be prompted again to the consumer previous to operating the question, permitting the flexibility to emulate saved procedures.
This eliminates the necessity to rewrite the question, depart it open, or save elsewhere. Write it as soon as, together with any vital parameter immediately within the question, and G.V() will auto detect these. This permits constructing a library of reviews towards the Neptune cluster that may be accessed and run.
On the lookout for suspicious conduct
This artificial dataset demonstrates fraudulent bank card transaction occasions.
A number of transactions being comprised of widespread geographical areas over a brief time period might point out fraudulent exercise.
Execute the next question to:
- Discover Individual vertices, and discover their card utilizing the
hasCardrelationship - Filter out the playing cards to retain these containing transactions which have been carried out from no less than 5 completely different areas
- For the filtered playing cards, retrieve the trail from the cardboard to the placement by the transaction that was carried out
Select Graph View
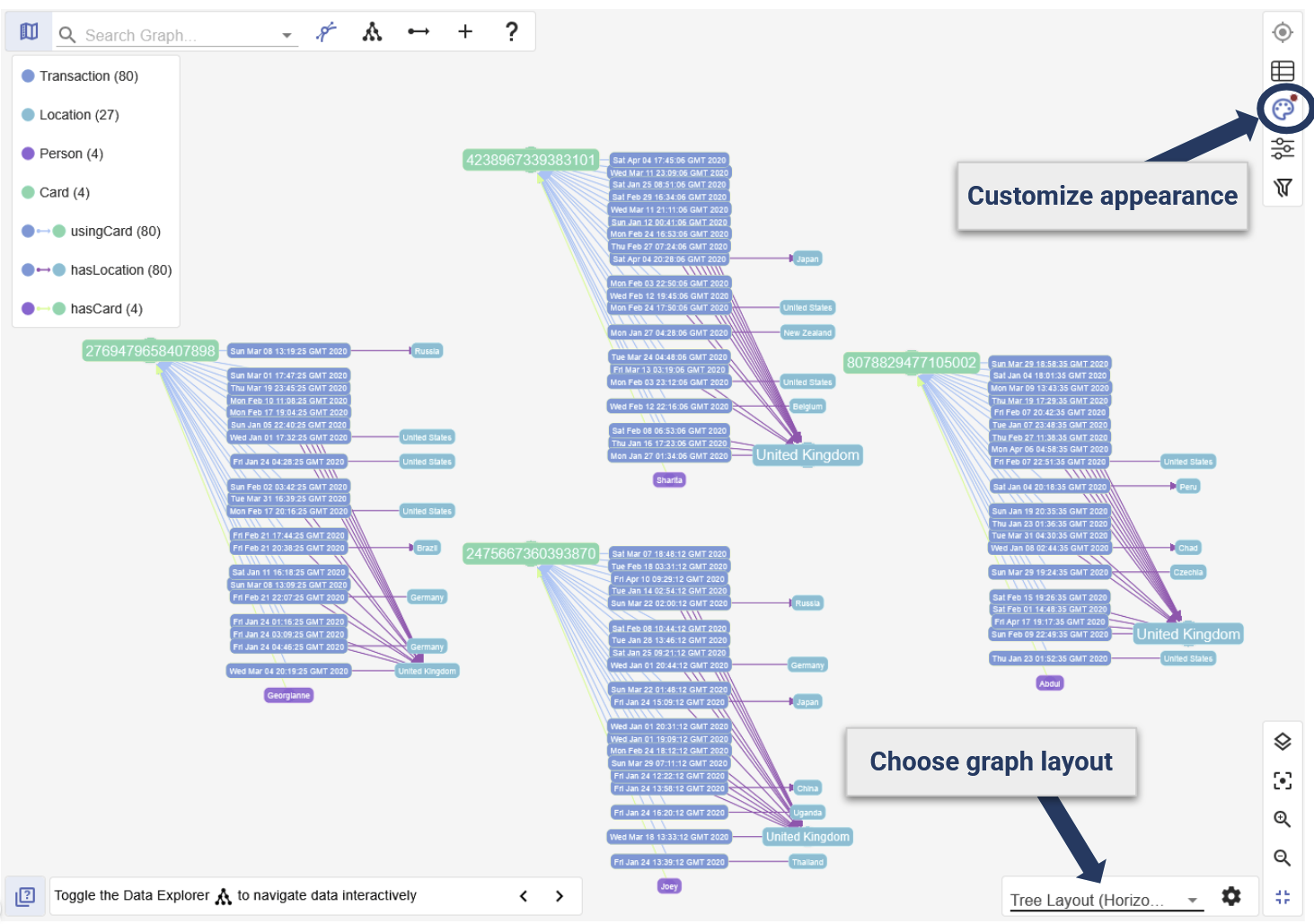
Evaluation exhibits that a number of transactions have occurred in 5 completely different nations inside just some hours.
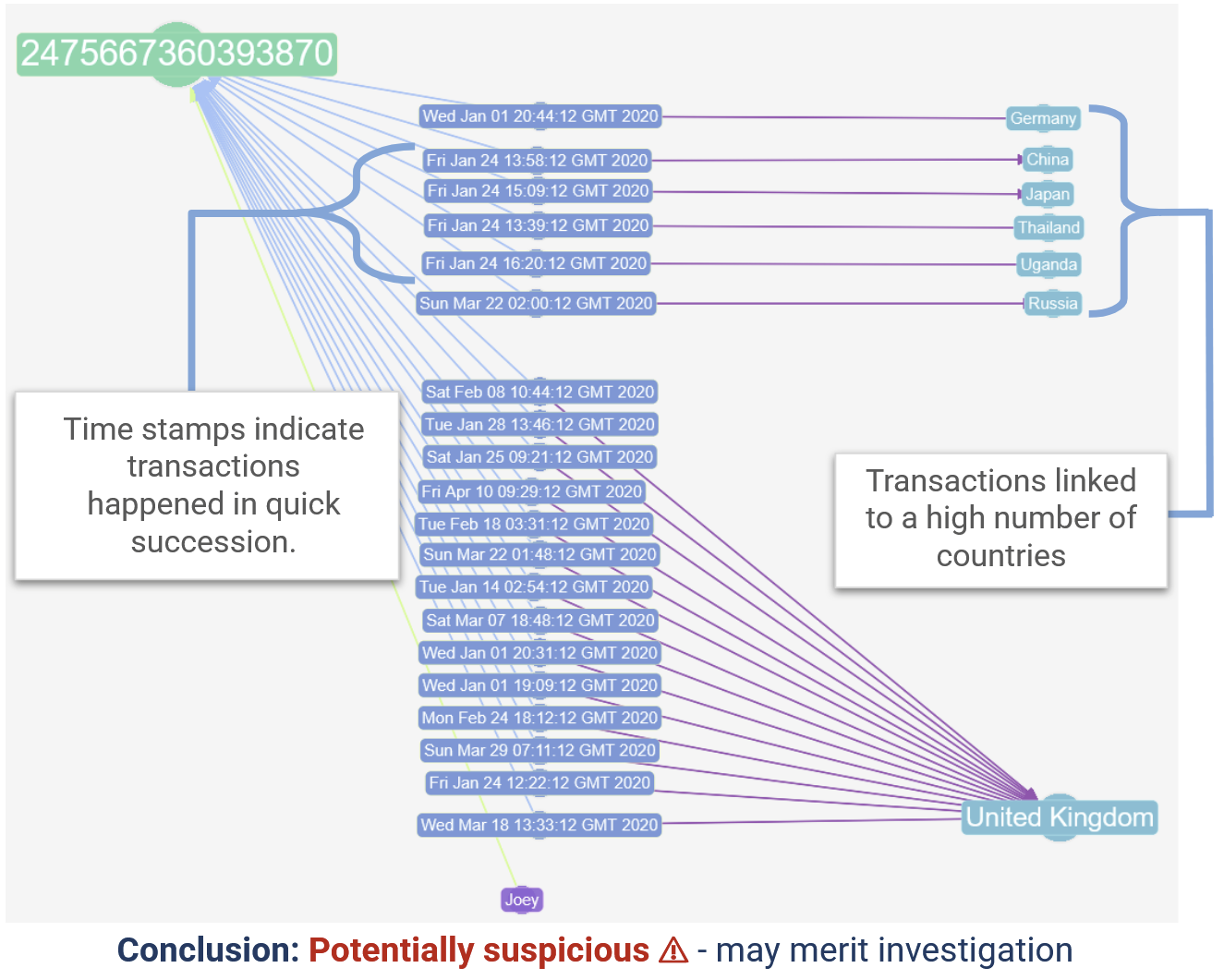
Enhance the WHERE situation to focus on transactions occurring inside a short while span throughout a number of areas.
Deciding what number of areas are adequate to qualify a transaction historical past as ‘suspicious’ is subjective, so having the variety of areas as an adjustable parameter is helpful. You should utilize the Question Assistant to create and manually regulate parameters.
Right here we have a look at any playing cards which have transactions linked to greater than a single location:
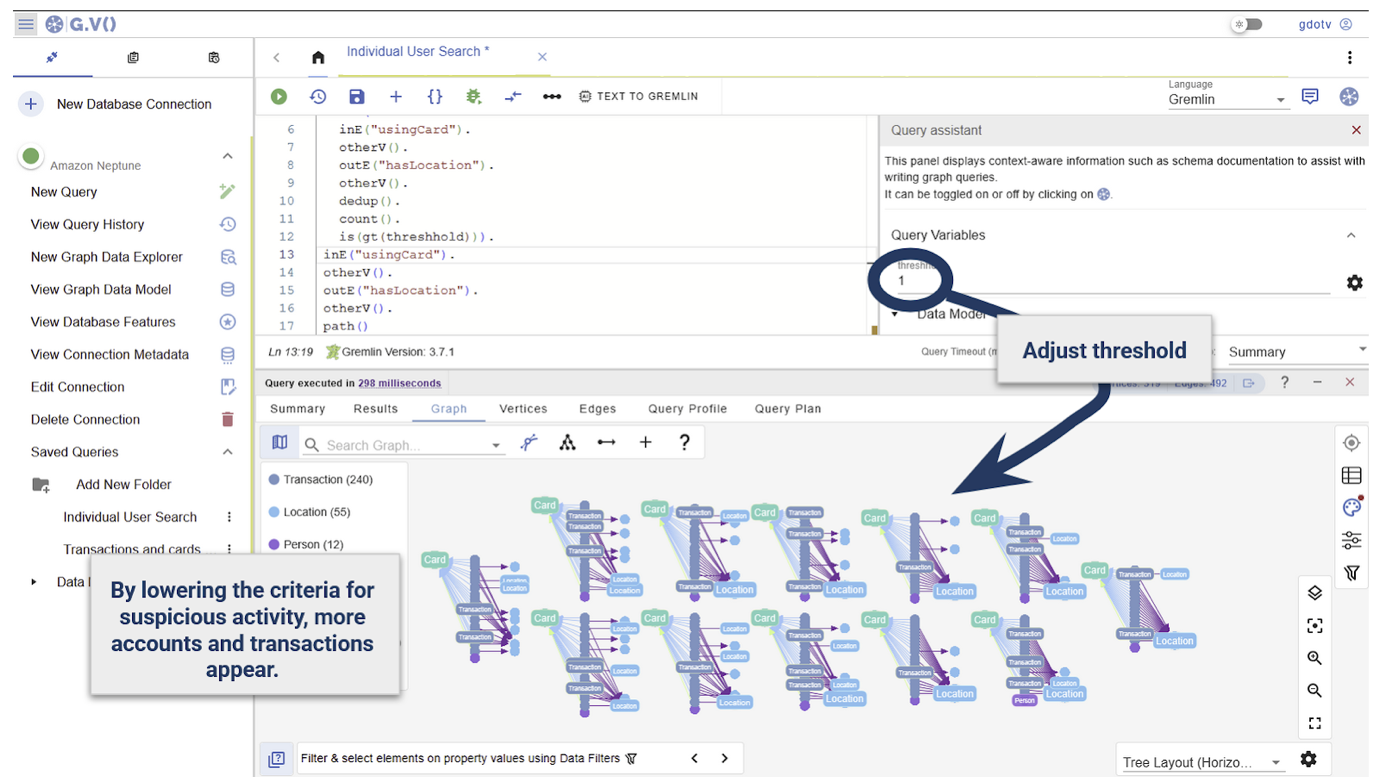
Utilizing parameters, reviews may be adjusted to the thresholds and context reminiscent of investigating a particular consumer or transaction.
Cleanup
Navigate to the EC2 part on the AWS console, select situations, choose the G.V() occasion’s checkbox, then select occasion state, terminate.
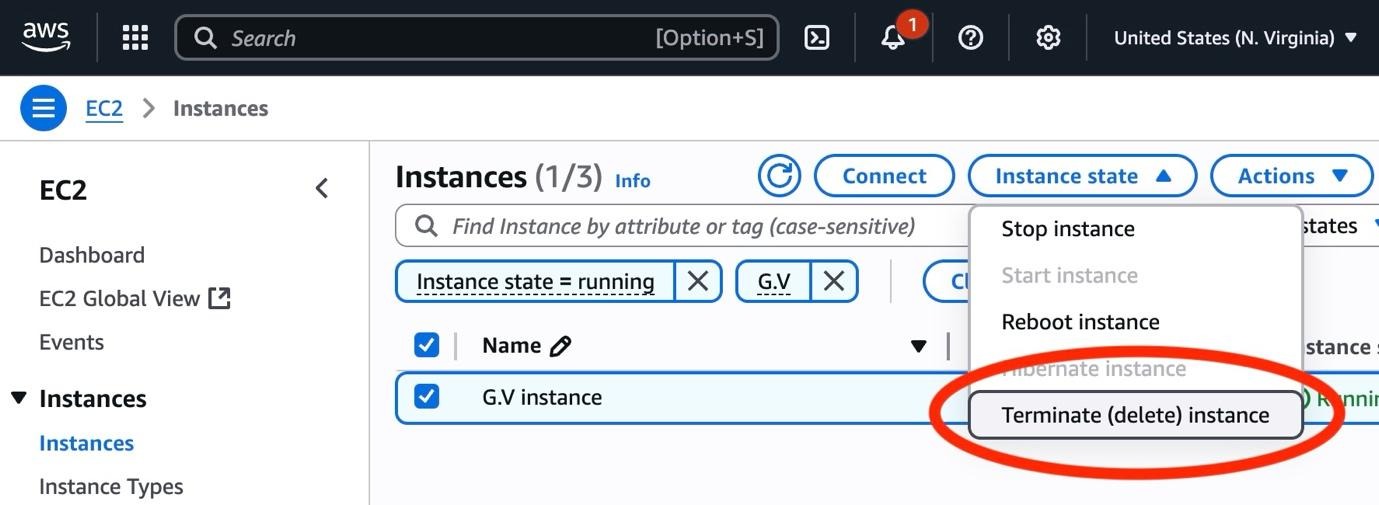
For those who now not want the Amazon Neptune cluster created on this publish, evaluate the Amazon Neptune documentation for delete the cluster.
Conclusion
On this publish, we demonstrated the fundamentals of deploying G.V() and configuring it to hook up with a Neptune cluster.
G.V() presents a variety of instruments to discover graph information, design complicated graph queries, and create configurable reviews. This makes querying, exploring and visualizing graph information considerably simpler, with out the necessity to construct complicated, bespoke options.
Our documentation presents a complete overview of our options and compatibility with different graph databases and engines, reminiscent of Neptune Analytics and different companions, reminiscent of Neo4J.
In regards to the Authors