

{kind=link}
In the present day, we’re publishing a new open supply pattern chatbot that reveals find out how to use suggestions from Automated Reasoning checks to iterate on the generated content material, ask clarifying questions, and show the correctness of a solution.
The chatbot implementation additionally produces an audit log that features mathematically verifiable explanations for the reply validity and a consumer interface that reveals builders the iterative, rewriting course of taking place behind the scenes. Automated Reasoning checks use logical deduction to robotically reveal {that a} assertion is appropriate. Not like massive language fashions, Automated Reasoning instruments are usually not guessing or predicting accuracy. As a substitute, they depend on mathematical proofs to confirm compliance with insurance policies. This weblog publish dives deeper into the implementation structure for the Automated Reasoning checks rewriting chatbot.
Enhance accuracy and transparency with Automated Reasoning checks
LLMs can typically generate responses that sound convincing however include factual errors—a phenomenon often known as hallucination. Automated Reasoning checks validate a consumer’s query and an LLM-generated reply, giving rewriting suggestions that factors out ambiguous statements, assertions which are too broad, and factually incorrect claims based mostly on floor fact data encoded in Automated Reasoning insurance policies.
A chatbot that makes use of Automated Reasoning checks to iterate on its solutions earlier than presenting them to customers helps enhance accuracy as a result of it will probably make exact statements that explicitly reply customers’ sure/no questions with out leaving room for ambiguity; and helps enhance transparency as a result of it will probably present mathematically verifiable proofs of why its statements are appropriate, making generative AI purposes auditable and explainable even in regulated environments.
Now that you simply perceive the advantages, let’s discover how one can implement this in your personal purposes.
Chatbot reference implementation
The chatbot is a Flask software that exposes APIs to submit questions and verify the standing of a solution. To point out the inside workings of the system, the APIs additionally allow you to retrieve details about the standing of every iteration, the suggestions from Automated Reasoning checks, and the rewriting immediate despatched to the LLM.
You should use the frontend NodeJS software to configure an LLM from Amazon Bedrock to generate solutions, choose an Automated Reasoning coverage for validation, and set the utmost variety of iterations to appropriate a solution. Choosing a chat thread within the consumer interface opens a debug panel on the precise that shows every iteration on the content material and the validation output.
Determine 1 – Chat interface with debug panel
As soon as Automated Reasoning checks say a response is legitimate, the verifiable clarification for the validity is displayed.
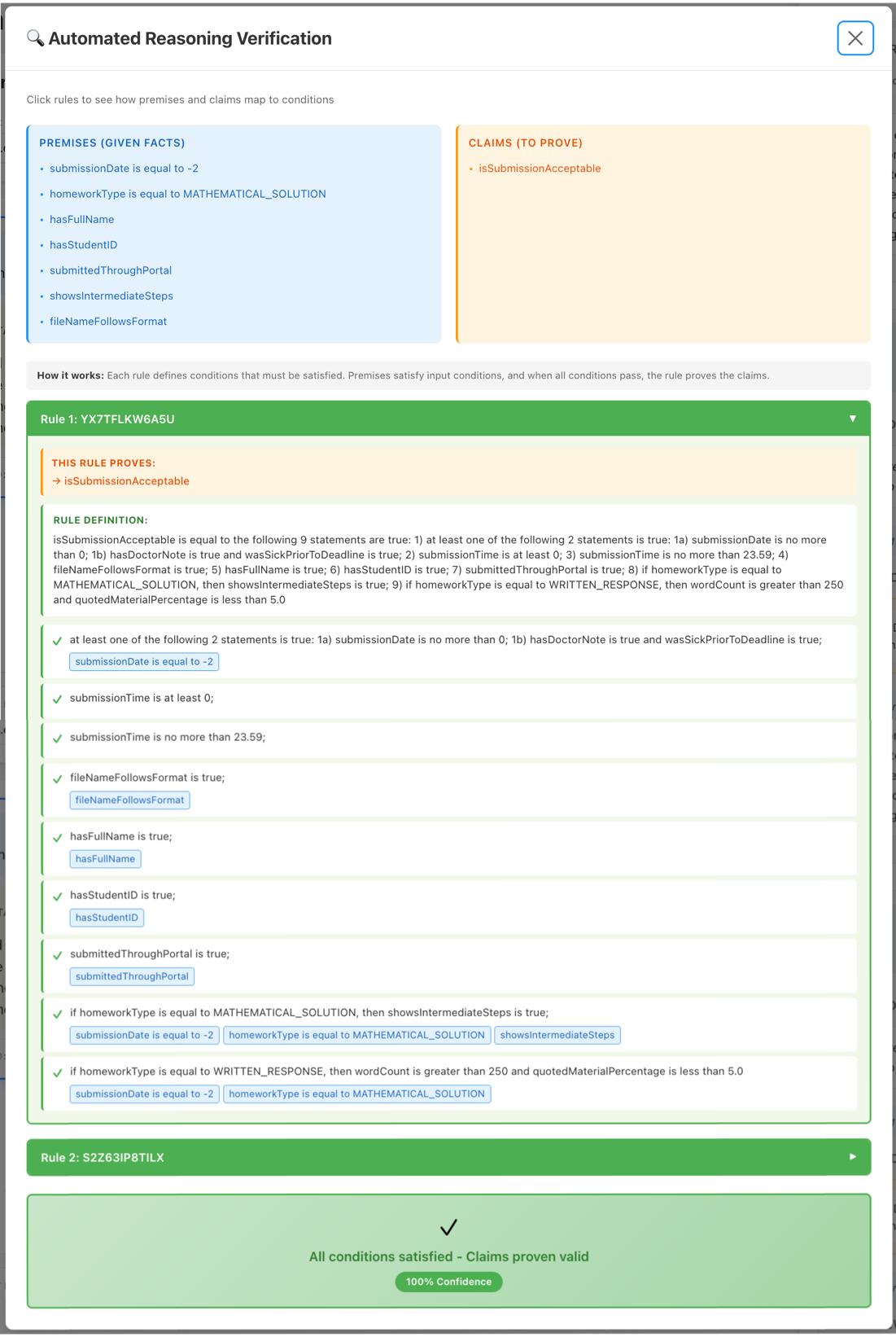
Determine 2 – Automated Reasoning checks validity proof
How the iterative rewriting loop works
The open supply reference implementation robotically helps enhance chatbot solutions by iterating on the suggestions from Automated Reasoning checks and rewriting the response. When requested to validate a chatbot query and reply (Q&A), Automated Reasoning checks return a listing of findings. Every discovering represents an unbiased logical assertion recognized within the enter Q&A. For instance, for the Q&A “How a lot does S3 storage price? In US East (N. Virginia), S3 prices $0.023/GB for the primary 50Tb; in Asia Pacific (Sydney), S3 prices $0.025/GB for the primary 50Tb” Automated Reasoning checks would produce two findings, one which validates the value for S3 in us-east-1 is $0.023, and one for ap-southeast-2.
When parsing a discovering for a Q&A, Automated Reasoning checks separate the enter into a listing of factual premises and claims made in opposition to these premises. A premise is usually a factual assertion within the consumer query, like “I’m an S3 consumer in Virginia,” or an assumption specified by the reply, like “For requests despatched to us-east-1…” A declare represents an announcement being verified. In our S3 pricing instance from the earlier paragraph, the Area can be a premise, and the value level can be a declare.
Every discovering features a validation consequence (VALID, INVALID, SATISFIABLE, TRANSLATION_AMBIGUOUS, IMPOSSIBLE) in addition to the suggestions essential to rewrite the reply in order that it’s VALID. The suggestions modifications relying on the validation consequence. For instance, ambiguous findings embody two interpretations of the enter textual content, satisfiable findings embody two situations that present how the claims could possibly be true in some circumstances and false in others. You may see the attainable discovering varieties in our API documentation.
With this context out of the best way, we are able to dive deeper into how the reference implementation works:
Preliminary response and validation
When the consumer submits a query by way of the UI, the applying first calls the configured Bedrock LLM to generate a solution, then calls the ApplyGuardrail API to validate the Q&A.
Utilizing the output from Automated Reasoning checks within the ApplyGuardrail response, the applying enters a loop the place every iteration checks the Automated Reasoning checks suggestions, performs an motion like asking the LLM to rewrite a solution based mostly on the suggestions, after which calls ApplyGuardrail to validate the up to date content material once more.
The rewriting loop (The guts of the system)
After the preliminary validation, the system makes use of the output from the Automated Reasoning checks to determine the subsequent step. First, it types the findings based mostly on their precedence – addressing crucial first: TRANSLATION_AMBIGUOUS, IMPOSSIBLE, INVALID, SATISFIABLE, VALID. Then, it selects the very best precedence discovering and addresses it with the logic beneath. Since VALID is final within the prioritized listing, the system will solely settle for one thing as VALID after addressing the opposite findings.
- For
TRANSLATION_AMBIGUOUSfindings, the Automated Reasoning checks return two interpretations of the enter textual content. ForSATISFIABLEfindings, the Automated Reasoning checks return two situations that show and disprove the claims. Utilizing the suggestions, the applying asks the LLM to determine on whether or not it needs to attempt to rewrite the reply to make clear ambiguities or ask the consumer observe up questions to assemble further info. For instance, theSATISFIABLEsuggestions might say that the value of $0.023 is legitimate provided that the Area is US East (N. Virginia). The LLM can use this info to ask concerning the software Area. When the LLM decides to ask follow-up questions, the loop pauses and waits for the consumer to reply the questions, then the LLM regenerates the reply based mostly on the clarifications and the loop restarts. - For
IMPOSSIBLEfindings, the Automated Reasoning checks return a listing of the foundations that contradict the premises – accepted details within the enter content material. Utilizing the suggestions, the applying asks the LLM to rewrite the reply to keep away from logical inconsistencies. - For
INVALIDfindings, the Automated Reasoning checks return the foundations from the Automated Reasoning coverage that make the claims invalid based mostly on the premises and coverage guidelines. Utilizing the suggestions, the applying asks the LLM to rewrite its reply in order that it’s in keeping with the foundations. - For
VALIDfindings, the applying exits the loop and returns the reply to the consumer.
After every reply rewrite, the system sends the Q&A to the ApplyGuardrail API for validation; the subsequent iteration of the loop begins with the suggestions from this name. Every iteration shops the findings and prompts with full context within the thread knowledge construction, creating an audit path of how the system arrived on the definitive reply.
Getting Began with the Automated Reasoning checks rewriting chatbot
To attempt our reference implementation, step one is to create an Automated Reasoning coverage:
- Navigate to Amazon Bedrock within the AWS Administration Console in one of many supported Areas in the USA or European Areas.
- From the left navigation, open the Automated Reasoning web page within the Construct class.
- Utilizing the dropdown menu of the Create coverage button, select Create pattern coverage.
- Enter a reputation for the coverage after which select Create coverage on the backside of the web page.
After you have created a coverage, you’ll be able to proceed to obtain and run the reference implementation:
- Clone the Amazon Bedrock Samples repository.
- Comply with the directions within the README file to put in dependencies, construct the frontend, and begin the applying.
- Utilizing your most popular browser navigate to http://localhost8080 and begin testing.
Backend implementation particulars
For those who’re planning to adapt this implementation for manufacturing use, this part goes over the important thing elements within the backend structure. You’ll find these elements within the backend listing of the repository.
- ThreadManager: Orchestrates a dialog lifecycle administration. It handles the creation, retrieval, and standing monitoring of dialog threads, sustaining correct state all through the rewriting course of. The ThreadManager implements thread-safe operations utilizing a lock to assist forestall race circumstances when a number of operations try to switch the identical dialog concurrently. It additionally tracks threads awaiting consumer enter and may establish stale threads which have exceeded a configurable timeout.
- ThreadProcessor: Handles the rewriting loop utilizing a state machine sample for clear, maintainable management stream. The processor manages state transitions between phases like
GENERATE_INITIAL,VALIDATE,CHECK_QUESTIONS,HANDLE_RESULT, andREWRITING_LOOP, progressing the dialog accurately by way of every stage. - ValidationService: Integrates with Amazon Bedrock Guardrails. This service takes every LLM-generated response and submits it for validation utilizing the
ApplyGuardrailAPI. It handles the communication with AWS, manages retry logic with exponential backoff for transient failures, and parses the validation outcomes into structured findings. - LLMResponseParser: Interprets the LLM’s intentions through the rewriting loop. When the system asks the LLM to repair an invalid response, the mannequin should determine whether or not to aim a rewrite (
REWRITE), ask clarifying questions (ASK_QUESTIONS), or declare the duty unattainable as a result of contradictory premises (IMPOSSIBLE). The parser examines the LLM’s response for particular markers like “DECISION:“, “ANSWER:“, and “QUESTION:“, extracting structured info from pure language output. It handles markdown formatting gracefully and enforces limits on the variety of questions (most 5). - AuditLogger: Writes structured JSON logs to a devoted audit log file, recording two key occasion varieties:
VALID_RESPONSEwhen a response passes validation, andMAX_ITERATIONS_REACHEDwhen the system exhausts the set variety of retry makes an attempt. Every audit entry captures the timestamp, thread ID, immediate, response, mannequin ID, and validation findings. The logger additionally extracts and information Q&A exchanges from clarification iterations, together with whether or not the consumer answered or skipped the questions.
Collectively, these elements assist create a strong basis for constructing reliable AI purposes that mix the pliability of enormous language fashions with the rigor of mathematical verification.
For detailed steerage on implementing Automated Reasoning checks in manufacturing:
Concerning the authors