
{kind=link}
Desk of Contents
-
SAM 3: Idea-Primarily based Visible Understanding and Segmentation
- The Evolution of Section Something: From Geometry to Ideas
- Core Mannequin Structure and Technical Elements
- Promptable Idea Segmentation (PCS): Defining the Job
- The SA-Co Knowledge Engine and Large Scale Dataset
- Coaching Methodology and Optimization
- Benchmarks and Efficiency Evaluation
- Actual-World Purposes and Industrial Influence
- Challenges and Future Outlook
- Configuring Your Growth Surroundings
- Setup and Imports
- Loading the SAM 3 Mannequin
- Downloading a Few Pictures
- Helper Perform
- Promptable Idea Segmentation on Pictures: Single Textual content Immediate on a Single Picture
- Abstract
SAM 3: Idea-Primarily based Visible Understanding and Segmentation
On this tutorial, we introduce Section Something Mannequin 3 (SAM 3), the shift from geometric promptable segmentation to open-vocabulary idea segmentation, and why that issues.

First, we summarize the mannequin household’s evolution (SAM-1 → SAM-2 → SAM-3), define the brand new Notion Encoder + DETR detector + Presence Head + streaming tracker structure, and describe the SA-Co information engine that enabled large-scale idea supervision.
Lastly, we arrange the event surroundings and present single-prompt examples to display the mannequin’s primary picture segmentation workflow.
By the tip of this tutorial, we’ll have a strong understanding of what makes SAM 3 revolutionary and find out how to carry out primary concept-driven segmentation utilizing textual content prompts.
This lesson is the first of a 4-part sequence on SAM 3:
- SAM 3: Idea-Primarily based Visible Understanding and Segmentation (this tutorial)
- Lesson 2
- Lesson 3
- Lesson 4
To study SAM 3 and find out how to carry out idea segmentation on pictures utilizing textual content prompts, simply hold studying.
The discharge of the Section Something Mannequin 3 (SAM 3) marks a definitive transition in laptop imaginative and prescient, shifting the main focus from purely geometric object localization to a complicated, concept-driven understanding of visible scenes.
Developed by Meta AI, SAM 3 is described as the primary unified basis mannequin able to detecting, segmenting, and monitoring all cases of an open-vocabulary idea throughout pictures and movies by way of pure language prompts or visible exemplars.
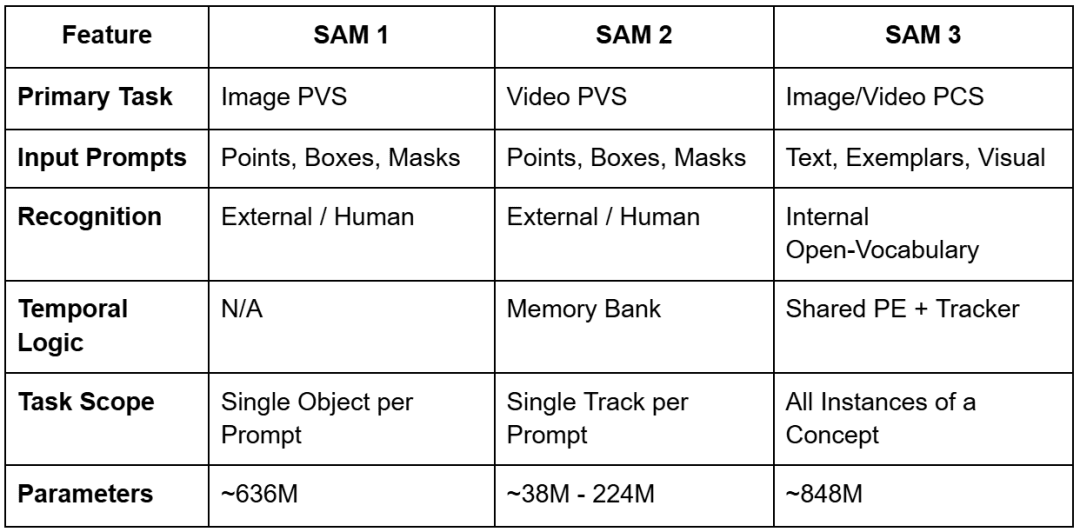
Whereas its predecessors (i.e., SAM 1 and SAM 2) established the paradigm of Promptable Visible Segmentation (PVS) by permitting customers to outline objects by way of factors, packing containers, or masks, they remained semantically agnostic. Consequently, they primarily functioned as high-precision geometric instruments.
SAM 3 transcends this limitation by introducing Promptable Idea Segmentation (PCS). This process internalizes semantic recognition and allows the mannequin to “perceive” user-provided noun phrases (NPs).
This transformation from a geometrical segmenter to a imaginative and prescient basis mannequin is facilitated by a large new dataset, SA-Co (Section Something with Ideas), and a novel architectural design that decouples recognition from localization.
The Evolution of Section Something: From Geometry to Ideas
The trajectory of the Section Something mission displays a broader development in synthetic intelligence towards multi-modal unification and zero-shot generalization.
SAM 1, launched in early 2023, launched the idea of a promptable basis mannequin for picture segmentation, able to zero-shot generalization to unseen domains through the use of easy spatial prompts.
Launched in 2024, SAM 2 prolonged this functionality to the temporal area by using a reminiscence financial institution structure to trace single objects throughout video frames with excessive temporal consistency.
Nonetheless, each fashions suffered from a typical bottleneck: they required an exterior system or a human operator to inform them the place an object was earlier than they may decide its extent.
SAM 3 addresses this foundational hole by integrating an open-vocabulary detector instantly into the segmentation and monitoring pipeline. This integration permits the mannequin to resolve “what” is within the picture, successfully turning segmentation right into a query-based search interface.
For instance, whereas SAM 2 required customers to click on on each automotive in a car parking zone to phase them, SAM 3 can settle for the textual content immediate “automobiles” and immediately return masks and distinctive identifiers for every particular person automotive within the scene. This evolution is summarized within the following comparability of the three mannequin generations.
Core Mannequin Structure and Technical Elements
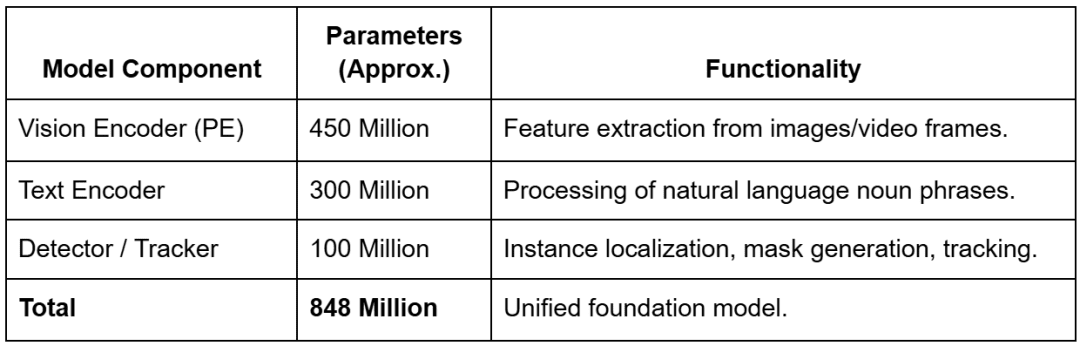
The structure of SAM 3 represents a elementary departure from earlier fashions, shifting to a unified, twin encoder-decoder transformer system.
The mannequin contains roughly 848 million parameters (relying on configuration), a major scale-up from the most important SAM 2 variants, reflecting the elevated complexity of the open-vocabulary recognition process.
These parameters are distributed throughout 3 predominant architectural pillars:
- shared Notion Encoder (PE)
- DETR-based detector
- memory-based tracker
The Notion Encoder (PE) and Imaginative and prescient Spine
Central to SAM 3’s design is the Notion Encoder (PE), a imaginative and prescient spine that’s shared between the image-level detector and the video-level tracker.
This shared design is crucial for guaranteeing that visible options are processed persistently throughout each static and temporal domains, minimizing process interference and maximizing information scaling effectivity.
In contrast to SAM 2, which utilized the Hiera structure, SAM 3 employs a ViT-style notion encoder that’s extra simply aligned with the semantic embeddings of the textual content encoder.
The imaginative and prescient encoder accounts for about 450 million parameters and is designed to deal with high-resolution inputs (usually scaled to 1024 or 1008 pixels) to protect the spatial element mandatory for exact masks technology.
The encoder’s output embeddings, usually of measurement ") with 1024 channels, are handed to a fusion encoder that situations them based mostly on the offered immediate tokens.
with 1024 channels, are handed to a fusion encoder that situations them based mostly on the offered immediate tokens.
The Open-Vocabulary Textual content and Exemplar Encoders
To facilitate Promptable Idea Segmentation, SAM 3 integrates a complicated textual content encoder with roughly 300 million parameters. This encoder processes noun phrases utilizing a specialised Byte Pair Encoding (BPE) vocabulary, permitting it to deal with an unlimited vary of descriptive phrases. When a consumer gives a textual content immediate, the encoder generates linguistic embeddings which might be handled as “immediate tokens”.
Along with textual content, SAM 3 helps picture exemplars — visible crops of goal objects offered by the consumer. These exemplars are processed by a devoted exemplar encoder that extracts visible options to outline the goal idea.
This multi-modal immediate interface permits the fusion encoder to collectively course of linguistic and visible cues, making a unified idea embedding that tells the mannequin precisely what to seek for within the picture.
The DETR-Primarily based Detector and Presence Head
The detection element of SAM 3 is predicated on the DEtection TRansformer (DETR) framework, which makes use of realized object queries to work together with the conditioned picture options.
In a typical DETR structure, queries are answerable for each classifying an object and figuring out its location. Nonetheless, in open-vocabulary eventualities, this usually results in “phantom detections.” There are false positives the place the mannequin localizes background noise as a result of it lacks a worldwide understanding of whether or not the requested idea even exists within the scene.
To unravel this, SAM 3 introduces the Presence Head, a novel architectural innovation that decouples recognition from localization. The Presence Head makes use of a realized world token that attends to all the picture context and predicts a single scalar “presence rating” ( ) between 0 and 1. This rating represents the chance that the prompted idea is current wherever within the body. The ultimate confidence rating for any particular person object question is then calculated as:
) between 0 and 1. This rating represents the chance that the prompted idea is current wherever within the body. The ultimate confidence rating for any particular person object question is then calculated as:

the place  is the rating produced by the person question’s native detection. If the Presence Head determines {that a} “unicorn” isn’t within the picture (rating ≈ 0.01), it suppresses all native detections, stopping hallucinations throughout the board. This mechanism considerably improves the mannequin’s calibration, significantly on the Picture-Degree Matthews Correlation Coefficient (IL_MCC) metric.
is the rating produced by the person question’s native detection. If the Presence Head determines {that a} “unicorn” isn’t within the picture (rating ≈ 0.01), it suppresses all native detections, stopping hallucinations throughout the board. This mechanism considerably improves the mannequin’s calibration, significantly on the Picture-Degree Matthews Correlation Coefficient (IL_MCC) metric.
The Streaming Reminiscence Tracker
For video processing, SAM 3 integrates a tracker that inherits the reminiscence financial institution structure from SAM 2 however is extra tightly coupled with the detector by means of the shared Notion Encoder.
On every body, the detector identifies new cases of the goal idea, whereas the tracker propagates current “masklets” (i.e., object-specific spatial-temporal masks) from earlier frames utilizing self- and cross-attention.
The system manages the temporal id of objects by means of an identical and replace stage. Propagated masks are in contrast with newly detected masks to make sure consistency, permitting the mannequin to deal with occlusions or objects that quickly exit the body.
If an object disappears behind an obstruction and later reappears, the detector gives a “recent” detection that the tracker makes use of to re-establish the item’s historical past, stopping id drift.
Promptable Idea Segmentation (PCS): Defining the Job
The introduction of Promptable Idea Segmentation (PCS) is the defining attribute of SAM 3, remodeling it from a device for “segmenting that factor” to a system for “segmenting every thing like that”. SAM 3 unifies a number of segmentation paradigms (i.e., single-image, video, interactive refinement, and concept-driven detection) below a single spine.
Open-Vocabulary Noun Phrases
The mannequin’s main interplay mode is thru textual content prompts. In contrast to conventional object detectors which might be restricted to a hard and fast set of courses (e.g., the 80 courses in COCO), SAM 3 is open-vocabulary.
As a result of it has been skilled on over 4 million distinctive noun phrases, it could perceive particular descriptions (e.g., “transport container,” “striped cat,” or “gamers sporting pink jerseys”). This permits researchers to question datasets for particular attributes with out retraining the mannequin for each new class.
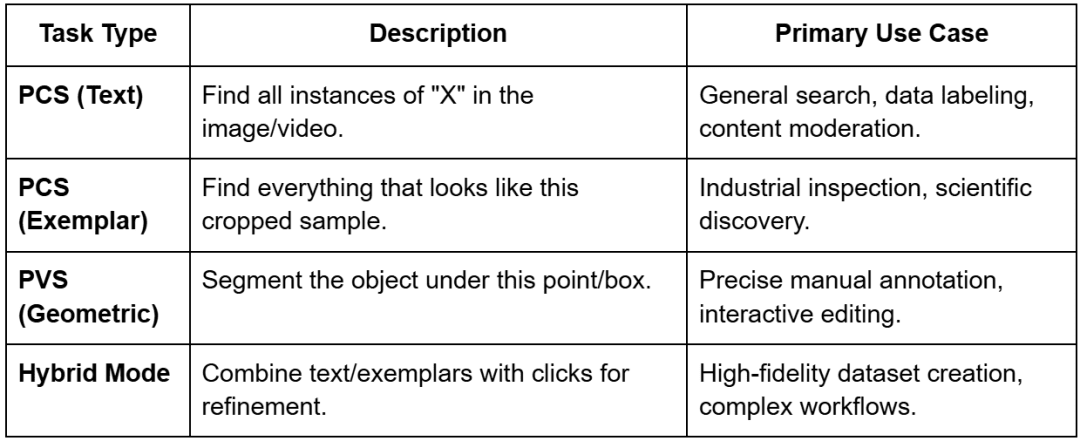
Picture Exemplars and Hybrid Prompting
Exemplar prompting permits customers to offer visible examples as a substitute of or along with textual content.
By drawing a field round an instance object, the consumer tells the mannequin to “discover extra of those”. That is significantly helpful in specialised fields the place textual content descriptions could also be ambiguous (e.g., figuring out a selected kind of business defect or a uncommon organic specimen).
The mannequin additionally helps hybrid prompting, the place a textual content immediate is used to slim the search and visible prompts are used for refinement. As an illustration, a consumer can immediate for “helmets” after which use unfavourable exemplars (packing containers round bicycle helmets) to drive the mannequin to solely phase building arduous hats.
This iterative refinement loop maintains the interactive “spirit” of the unique SAM whereas scaling it to 1000’s of potential objects.
The SA-Co Knowledge Engine and Large Scale Dataset
The success of SAM 3 is basically pushed by its coaching information. Meta developed an revolutionary information engine to create the SA-Co (Section Something with Ideas) dataset, which is the most important high-quality open-vocabulary segmentation dataset so far. This dataset incorporates roughly 5.2 million pictures and 52.5 thousand movies, with over 4 million distinctive noun phrases and 1.4 billion masks.
The 4-Stage Knowledge Engine
The SA-Co information engine follows a complicated semi-automated suggestions loop designed to maximise each range and accuracy.
- Media Curation: The engine curates numerous media domains, shifting past homogeneous net information to incorporate aerial, doc, medical, and industrial imagery.
- Label Curation and AI Annotation: By leveraging a fancy ontology and multimodal giant language fashions (MLLMs) resembling Llama 3.2 to function “AI annotators,” the system generates a large variety of distinctive noun phrases for the curated media.
- High quality Verification: AI annotators are deployed to examine masks high quality and exhaustivity. Apparently, these AI techniques are reported to be 5× quicker than people at figuring out “unfavourable prompts” (ideas not current within the scene) and 36% quicker at figuring out “optimistic prompts”.
- Human Refinement: Human annotators are used strategically, stepping in just for probably the most difficult examples the place the AI fashions wrestle (e.g., fine-grained boundary corrections or resolving semantic ambiguities).
Dataset Composition and Statistics
The ensuing dataset is categorized into coaching and analysis units that cowl a variety of real-world eventualities.
- SA-Co/HQ: 5.2 million high-quality pictures with 4 million distinctive NPs.
- SA-Co/SYN: 38 million artificial phrases with 1.4 billion masks, used for massive-scale pre-training.
- SA-Co/VIDEO: 52.5 thousand movies containing over 467,000 masklets, guaranteeing temporal stability.
The analysis benchmark (SA-Co Benchmark) is especially rigorous, containing 214,000 distinctive phrases throughout 126,000 pictures and movies — over 50× the ideas present in current benchmarks (e.g., LVIS). It consists of subsets (e.g., SA-Co/Gold), the place every image-phrase pair is annotated by three totally different people to ascertain a baseline for “human-level” efficiency.
Coaching Methodology and Optimization
The coaching of SAM 3 is a multi-stage course of designed to stabilize the training of numerous duties inside a single mannequin spine.
4-Stage Coaching Pipeline
- Notion Encoder Pre-training: The imaginative and prescient spine is pre-trained to develop a strong function illustration of the world.
- Detector Pre-training: The detector is skilled on a mix of artificial information and high-quality exterior datasets to ascertain foundational idea recognition.
- Detector Positive-tuning: The mannequin is fine-tuned on the SA-Co/HQ dataset, the place it learns to deal with exhaustive occasion detection, and the Presence Head is optimized utilizing difficult unfavourable phrases.
- Tracker Coaching: Lastly, the tracker is skilled whereas the imaginative and prescient spine is frozen, permitting the mannequin to study temporal consistency with out degrading the detector’s semantic precision.
Optimization Strategies
The coaching course of leverages trendy engineering strategies to deal with the huge dataset and parameter rely.
- Precision: Use of PyTorch Automated Blended Precision (AMP) (float16/bfloat16) to optimize reminiscence utilization on giant GPUs (e.g., the H200).
- Gradient Checkpointing: Enabled for decoder cross-attention blocks to scale back reminiscence overhead throughout the coaching of the 848M-parameter mannequin.
- Instructor Caching: In distillation eventualities (e.g., EfficientSAM3), instructor encoder options are cached to scale back the I/O bottleneck, considerably accelerating the coaching of smaller “pupil” fashions.
Benchmarks and Efficiency Evaluation
SAM 3 delivers a “step change” in efficiency, setting new state-of-the-art outcomes throughout picture and video segmentation duties.
Zero-Shot Occasion Segmentation (LVIS)
The LVIS dataset is a typical benchmark for long-tail occasion segmentation. SAM 3 achieves a zero-shot masks common precision (AP) of 47.0 (or 48.8 in some stories), representing a 22% enchancment over the earlier better of 38.5. This means a vastly improved skill to acknowledge uncommon or specialised classes with out specific coaching on these labels.
The SA-Co Benchmark Outcomes
On the brand new SA-Co benchmark, SAM 3 achieves a 2× efficiency acquire over current techniques. On the Gold subset, the mannequin reaches 88% of human-level efficiency, establishing it as a extremely dependable device for automated labeling.
Object Counting and Reasoning Benchmarks
The mannequin’s skill to rely and motive about objects can also be a significant spotlight. In counting duties, SAM 3 achieves an accuracy of 93.8% and a Imply Absolute Error (MAE) of simply 0.12, outperforming huge fashions (e.g., Gemini 2.5 Professional and Qwen2-VL-72B) on exact visible grounding benchmarks.
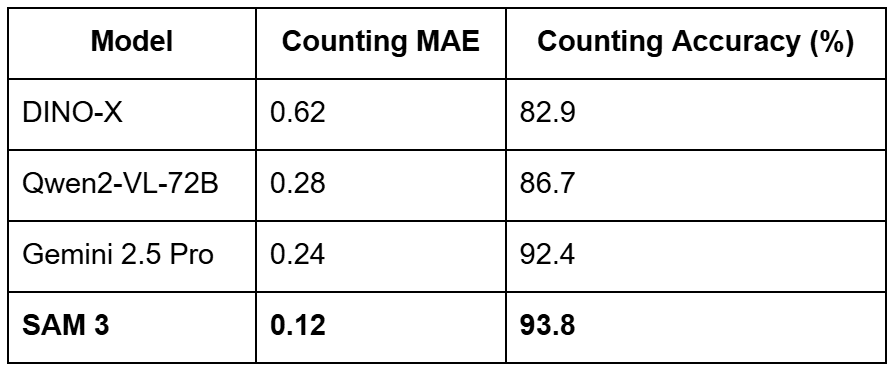
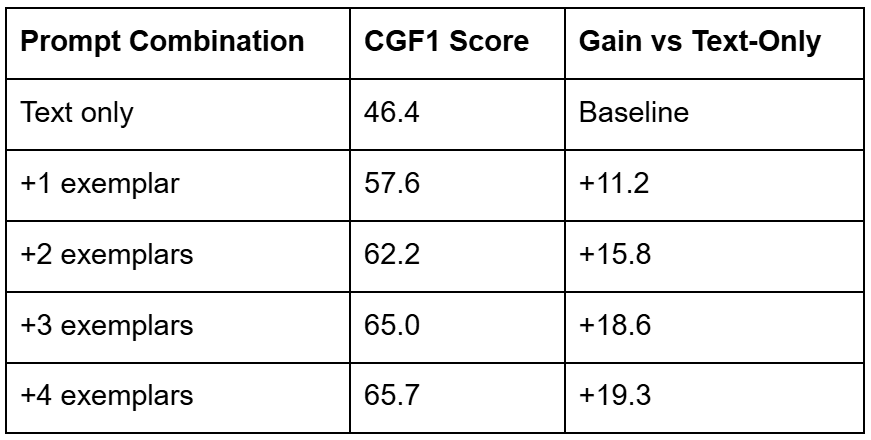
For complicated reasoning duties (ReasonSeg), the place directions is likely to be “the leftmost individual sporting a blue vest,” SAM 3, when paired with an MLLM agent, achieves 76.0 gIoU (Generalized Intersection over Union), a 16.9% enchancment over the prior state-of-the-art.
Actual-World Purposes and Industrial Influence
The flexibility of SAM 3 makes it a strong basis for a variety of business and inventive purposes.
Good Video Enhancing and Content material Creation
Creators can now use pure language to use results to particular topics in movies. For instance, a video editor can immediate “apply a sepia filter to the blue chair” or “blur the faces of all bystanders,” and the mannequin will deal with the segmentation and monitoring all through the clip. This performance is being built-in into instruments (e.g., Vibes on the Meta AI app and media enhancing flows on Instagram).
Dataset Labeling and Distillation
As SAM 3 is computationally heavy (working at  30 ms per picture on an H200), its most quick industrial affect is in scaling information annotation. Groups can use SAM 3 to mechanically label thousands and thousands of pictures with high-quality occasion masks after which use this “floor reality” to coach smaller, quicker fashions like YOLO or EfficientSAM3 for real-time use on the sting (e.g., in drones or cellular apps).
30 ms per picture on an H200), its most quick industrial affect is in scaling information annotation. Groups can use SAM 3 to mechanically label thousands and thousands of pictures with high-quality occasion masks after which use this “floor reality” to coach smaller, quicker fashions like YOLO or EfficientSAM3 for real-time use on the sting (e.g., in drones or cellular apps).
Robotics and AR Analysis
SAM 3 is being utilized in Aria Gen 2 analysis glasses to assist phase and observe fingers and objects from a first-person perspective. This helps contextual AR analysis, the place a wearable assistant can acknowledge {that a} consumer is “holding a screwdriver” or “taking a look at a leaky pipe” and supply related holographic overlays or directions.
Challenges and Future Outlook
Regardless of its breakthrough efficiency, a number of analysis frontiers stay for the Section Something household.
- Instruction Reasoning: Whereas SAM 3 handles atomic ideas, it nonetheless depends on exterior brokers (MLLMs) to interpret long-form or complicated directions. Future iterations (e.g., SAM 3-I) are working to combine this instruction-level reasoning natively into the mannequin.
- Effectivity and On-Machine Use: The 848M parameter measurement restricts SAM 3 to server-side environments. The event of EfficientSAM3 by means of progressive hierarchical distillation is essential for bringing concept-aware segmentation to real-time, on-device purposes.
- Positive-Grained Context: In duties involving fine-grained organic buildings or context-dependent targets, textual content prompts can generally fail or present coarse boundaries. Positive-tuning with adapters (e.g., SAM3-UNet) stays an important analysis course for adapting the inspiration mannequin to specialised scientific and medical domains.
Would you want quick entry to three,457 pictures curated and labeled with hand gestures to coach, discover, and experiment with … free of charge? Head over to Roboflow and get a free account to seize these hand gesture pictures.
Configuring Your Growth Surroundings
To comply with this information, you’ll want to have the next libraries put in in your system.
!pip set up --q git+https://github.com/huggingface/transformers supervision jupyter_bbox_widget
We set up the transformers library to load the SAM 3 mannequin and processor, the supervision library for annotation, drawing, and inspection, which we use later to visualise bounding packing containers and segmentation outputs. We additionally set up jupyter_bbox_widget, which provides us an interactive widget. This widget runs inside a pocket book and lets us click on on the picture so as to add factors or draw bounding packing containers.
We additionally go the --q flag to cover set up logs. This retains pocket book output clear.
Want Assist Configuring Your Growth Surroundings?

All that mentioned, are you:
- Quick on time?
- Studying in your employer’s administratively locked system?
- Eager to skip the effort of preventing with the command line, bundle managers, and digital environments?
- Able to run the code instantly in your Home windows, macOS, or Linux system?
Then be a part of PyImageSearch College right this moment!
Achieve entry to Jupyter Notebooks for this tutorial and different PyImageSearch guides pre-configured to run on Google Colab’s ecosystem proper in your net browser! No set up required.
And better of all, these Jupyter Notebooks will run on Home windows, macOS, and Linux!
Setup and Imports
As soon as put in, we transfer on to import the required libraries.
import io import torch import base64 import requests import matplotlib import numpy as np import ipywidgets as widgets import matplotlib.pyplot as plt from google.colab import output from speed up import Accelerator from IPython.show import show from jupyter_bbox_widget import BBoxWidget from PIL import Picture, ImageDraw, ImageFont from transformers import Sam3Processor, Sam3Model, Sam3TrackerProcessor, Sam3TrackerModel
We import the next:
io: Python’s built-in module to deal with in-memory picture buffers later when changing PIL pictures to base64 formattorch: to run the SAM 3 mannequin, ship tensors to the GPU, and work with mannequin outputsbase64: module to transform our pictures into base64 strings in order that the BBox widget can show them within the pocket bookrequests: library to obtain pictures instantly from a URL; this retains our workflow easy and avoids guide file uploads
We import a number of helper libraries.
matplotlib.pyplot: helps us visualize masks and overlaysnumpy: offers us quick array operationsipywidgets: allows interactive components contained in the pocket book
We import the output utility from Colab. Later, we use it to allow interactive widgets. With out this step, our bounding field widget won’t render. We import Accelerator from Hugging Face to run the mannequin effectively on both CPU or GPU with the identical code. It additionally simplifies system placement.
We import the show operate to render pictures and widgets instantly in pocket book cells, and BBoxWidget acts because the core interactive device that permits us to click on and draw bounding packing containers or factors on prime of a picture. We use this as our immediate enter system.
We additionally import 3 courses from Pillow:
Picture: masses RGB picturesImageDraw: helps us draw shapes on picturesImageFont: offers us textual content rendering assist for overlays
Lastly, we import our SAM 3 instruments from transformers.
Sam3Processor: prepares inputs for the segmentation mannequinSam3Model: performs segmentation from textual content and field promptsSam3TrackerProcessor: prepares inputs for point-based or monitoring promptsSam3TrackerModel: runs point-based segmentation and masking
Loading the SAM 3 Mannequin
system = "cuda" if torch.cuda.is_available() else "cpu"
processor = Sam3Processor.from_pretrained("fb/sam3")
mannequin = Sam3Model.from_pretrained("fb/sam3").to(system)
First, we examine if a GPU is out there within the surroundings. If PyTorch detects CUDA (Compute Unified Machine Structure), then we use the GPU for quicker inference. In any other case, we fall again to the CPU. This examine ensures our code runs effectively on any machine (Line 1).
Subsequent, we load the Sam3Processor. The processor is answerable for making ready all inputs earlier than they attain the mannequin. It handles picture preprocessing, bounding field formatting, textual content prompts, and tensor conversion. In any case, it makes our uncooked pictures suitable with the mannequin (Line 3).
Lastly, we load the Sam3Model from Hugging Face. This mannequin takes the processed inputs and generates segmentation masks. We instantly transfer the mannequin to the chosen system (GPU or CPU) for inference (Line 4).
Downloading a Few Pictures
!wget -q https://media.roboflow.com/notebooks/examples/birds.jpg !wget -q https://media.roboflow.com/notebooks/examples/traffic_jam.jpg !wget -q https://media.roboflow.com/notebooks/examples/basketball_game.jpg !wget -q https://media.roboflow.com/notebooks/examples/dog-2.jpeg
Right here, we obtain just a few pictures from the Roboflow media server utilizing the wget command and use the -q flag to suppress output and hold the pocket book clear.
Helper Perform
This helper overlays segmentation masks, bounding packing containers, labels, and confidence scores instantly on prime of the unique picture. We use it all through the pocket book to visualise mannequin predictions.
def overlay_masks_boxes_scores(
picture,
masks,
packing containers,
scores,
labels=None,
score_threshold=0.0,
alpha=0.5,
):
picture = picture.convert("RGBA")
masks = masks.cpu().numpy()
packing containers = packing containers.cpu().numpy()
scores = scores.cpu().numpy()
if labels is None:
labels = ["object"] * len(scores)
labels = np.array(labels)
# Rating filtering
hold = scores >= score_threshold
masks = masks[keep]
packing containers = packing containers[keep]
scores = scores[keep]
labels = labels[keep]
n_instances = len(masks)
if n_instances == 0:
return picture
# Colormap (one shade per occasion)
cmap = matplotlib.colormaps.get_cmap("rainbow").resampled(n_instances)
colours = [
tuple(int(c * 255) for c in cmap(i)[:3])
for i in vary(n_instances)
]
First, we outline a operate named overlay_masks_boxes_scores. It accepts the unique RGB picture and the mannequin outputs: masks, packing containers, and scores. We additionally settle for non-compulsory labels, a rating threshold, and a transparency issue alpha (Traces 1-9).
Subsequent, we convert the picture into RGBA format. The additional alpha channel permits us to mix masks easily on prime of the picture (Line 10). We transfer the tensors to the CPU and convert them to NumPy arrays. This makes them simpler to govern and suitable with Pillow (Traces 12-14).
If the consumer doesn’t present labels, we assign a default label string to every detected object (Traces 16 and 17). We convert labels to a NumPy array so we are able to filter them later, together with masks and scores (Line 19). We filter out detections under the rating threshold. This permits us to cover low-confidence masks and cut back litter within the visualization (Traces 22-26). If nothing survives filtering, we return the unique picture unchanged (Traces 28-30).
We choose a rainbow colormap and pattern one distinctive shade per detected object. We convert float values to RGB integer tuples (0-255 vary) (Traces 33-37).
# =========================
# PASS 1: MASK OVERLAY
# =========================
for masks, shade in zip(masks, colours):
mask_img = Picture.fromarray((masks * 255).astype(np.uint8))
overlay = Picture.new("RGBA", picture.measurement, shade + (0,))
overlay.putalpha(mask_img.level(lambda v: int(v * alpha)))
picture = Picture.alpha_composite(picture, overlay)
Right here, we loop by means of every mask-color pair. For every masks, we create a grayscale masks picture, convert it right into a clear RGBA overlay, and mix it onto the unique picture. The alpha worth controls transparency. This step provides tender, coloured areas over segmented areas (Traces 42-46).
# =========================
# PASS 2: BOXES + LABELS
# =========================
draw = ImageDraw.Draw(picture)
attempt:
font = ImageFont.load_default()
besides Exception:
font = None
for field, rating, label, shade in zip(packing containers, scores, labels, colours):
x1, y1, x2, y2 = map(int, field.tolist())
# --- Bounding field (with black stroke for visibility)
draw.rectangle([(x1, y1), (x2, y2)], define="black", width=3)
draw.rectangle([(x1, y1), (x2, y2)], define=shade, width=2)
# --- Label textual content
textual content = f"{label} | {rating:.2f}"
tb = draw.textbbox((0, 0), textual content, font=font)
tw, th = tb[2] - tb[0], tb[3] - tb[1]
# Label background
draw.rectangle(
[(x1, y1 - th - 4), (x1 + tw + 6, y1)],
fill=shade,
)
# Black label textual content (excessive distinction)
draw.textual content(
(x1 + 3, y1 - th - 2),
textual content,
fill="black",
font=font,
)
return picture
Right here, we put together a drawing context to overlay rectangles and textual content (Line 51). We try and load a default font. If unavailable, we fall again to no font (Traces 53-56). We loop over every object and extract its bounding field coordinates (Traces 58 and 59).
We draw two rectangles: The primary one (black) improves visibility, and the second makes use of the assigned object shade (Traces 62 and 63). We format the label and rating textual content, then compute the textual content field measurement (Traces 66-68). We draw a coloured background rectangle behind the label textual content (Traces 71-74). We draw black textual content on prime. Black textual content gives a robust distinction towards vibrant overlay colours (Traces 77-82).
Lastly, we return the annotated picture (Line 84).
Promptable Idea Segmentation on Pictures: Single Textual content Immediate on a Single Picture
Now, we’re prepared to point out Promptable Idea Segmentation on pictures.
On this instance, we phase particular visible ideas from a picture utilizing solely a single textual content immediate.
Instance 1
# Load picture
image_url = "http://pictures.cocodataset.org/val2017/000000077595.jpg"
picture = Picture.open(requests.get(image_url, stream=True).uncooked).convert("RGB")
# Section utilizing textual content immediate
inputs = processor(pictures=picture, textual content="ear", return_tensors="pt").to(system)
with torch.no_grad():
outputs = mannequin(**inputs)
# Publish-process outcomes
outcomes = processor.post_process_instance_segmentation(
outputs,
threshold=0.5,
mask_threshold=0.5,
target_sizes=inputs.get("original_sizes").tolist()
)[0]
print(f"Discovered {len(outcomes['masks'])} objects")
# Outcomes comprise:
# - masks: Binary masks resized to unique picture measurement
# - packing containers: Bounding packing containers in absolute pixel coordinates (xyxy format)
# - scores: Confidence scores
First, we load a take a look at picture from the COCO (Frequent Objects in Context) dataset. We obtain it instantly by way of URL, convert its bytes right into a PIL picture, and guarantee it’s in RGB format utilizing Picture from Pillow. This gives a standardized enter for SAM 3 (Traces 2 and three).
Subsequent, we put together the mannequin inputs. We go the picture and a single textual content immediate — the key phrase "ear". The processor handles all preprocessing steps (e.g., resizing, normalization, and token encoding). We transfer the ultimate tensors to our chosen system (GPU or CPU) (Line 6).
Then, we run inference. We disable gradient monitoring utilizing torch.no_grad(). This reduces reminiscence utilization and hastens ahead passes. The mannequin returns uncooked segmentation outputs (Traces 8 and 9).
After inference, we convert uncooked mannequin outputs into usable instance-level segmentation predictions utilizing processor.post_process_instance_segmentation (Traces 12-17).
- We apply a
thresholdto filter weak detections. - We apply
mask_thresholdto transform predicted logits into binary masks. - We resize masks again to their unique dimensions.
We index [0] as a result of this output corresponds to the primary (and solely) picture within the batch (Line 17).
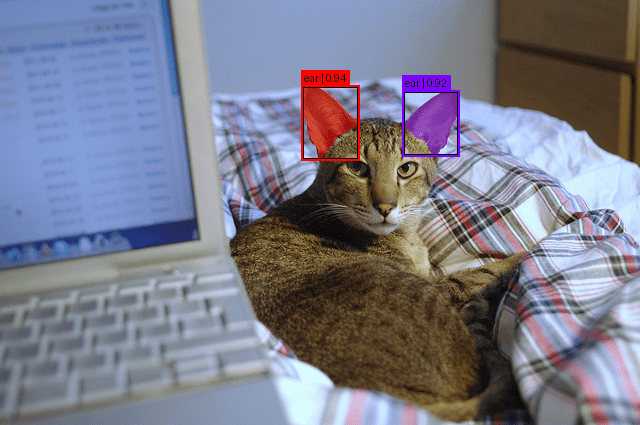
We print the variety of detected occasion masks. Every masks corresponds to at least one “ear” discovered within the picture (Line 19).
Under is the variety of objects detected within the picture.
Discovered 2 objects
Output
labels = ["ear"] * len(outcomes["scores"]) overlay_masks_boxes_scores( picture, outcomes["masks"], outcomes["boxes"], outcomes["scores"], labels )
Now, to visualise the output, we assign the label "ear" to every detected occasion. This ensures our visualizer shows clear textual content overlays.
Lastly, we name our visualization helper. This overlays:
- segmentation masks
- bounding packing containers
- labels
- scores
instantly on prime of the picture. The result’s a transparent visible map displaying the place SAM 3 discovered ears within the scene (Traces 2-8).
In Determine 1, we are able to see the item (ear) detected within the picture.
Instance 2
IMAGE_PATH = '/content material/birds.jpg'
# Load picture
picture = Picture.open(IMAGE_PATH).convert("RGB")
# Section utilizing textual content immediate
inputs = processor(pictures=picture, textual content="chicken", return_tensors="pt").to(system)
with torch.no_grad():
outputs = mannequin(**inputs)
# Publish-process outcomes
outcomes = processor.post_process_instance_segmentation(
outputs,
threshold=0.5,
mask_threshold=0.5,
target_sizes=inputs.get("original_sizes").tolist()
)[0]
print(f"Discovered {len(outcomes['masks'])} objects")
# Outcomes comprise:
# - masks: Binary masks resized to unique picture measurement
# - packing containers: Bounding packing containers in absolute pixel coordinates (xyxy format)
# - scores: Confidence scores
This block of code is an identical to the earlier instance. The one change is that we now load a native picture (birds.jpg) as a substitute of downloading one from COCO. We additionally replace the segmentation immediate from "ear" to "chicken".
Under is the variety of objects detected within the picture.
Discovered 45 objects
Output
labels = ["bird"] * len(outcomes["scores"]) overlay_masks_boxes_scores( picture, outcomes["masks"], outcomes["boxes"], outcomes["scores"], labels )
The output code stays much like the above. The one distinction is the label change from "ear" to "chicken".
In Determine 2, we are able to see the item (chicken) detected within the picture.

Instance 3
IMAGE_PATH = '/content material/traffic_jam.jpg'
# Load picture
picture = Picture.open(IMAGE_PATH).convert("RGB")
# Section utilizing textual content immediate
inputs = processor(pictures=picture, textual content="taxi", return_tensors="pt").to(system)
with torch.no_grad():
outputs = mannequin(**inputs)
# Publish-process outcomes
outcomes = processor.post_process_instance_segmentation(
outputs,
threshold=0.5,
mask_threshold=0.5,
target_sizes=inputs.get("original_sizes").tolist()
)[0]
print(f"Discovered {len(outcomes['masks'])} objects")
# Outcomes comprise:
# - masks: Binary masks resized to unique picture measurement
# - packing containers: Bounding packing containers in absolute pixel coordinates (xyxy format)
# - scores: Confidence scores
This block of code is an identical to the earlier instance. The one change is that we now load a native picture (traffic_jam.jpg) as a substitute of downloading one from COCO. We additionally replace the segmentation immediate from "chicken" to "taxi".
Under is the variety of objects detected within the picture.
Discovered 16 objects
Output
labels = ["taxi"] * len(outcomes["scores"]) overlay_masks_boxes_scores( picture, outcomes["masks"], outcomes["boxes"], outcomes["scores"], labels )
The output code stays much like the above. The one distinction is the change of the label from "chicken" to "taxi".
In Determine 3, we are able to see the item (taxi) detected within the picture.

What’s subsequent? We suggest PyImageSearch College.
86+ complete courses • 115+ hours hours of on-demand code walkthrough movies • Final up to date: January 2026
★★★★★ 4.84 (128 Rankings) • 16,000+ College students Enrolled
I strongly consider that in the event you had the precise instructor you could possibly grasp laptop imaginative and prescient and deep studying.
Do you suppose studying laptop imaginative and prescient and deep studying must be time-consuming, overwhelming, and complex? Or has to contain complicated arithmetic and equations? Or requires a level in laptop science?
That’s not the case.
All you’ll want to grasp laptop imaginative and prescient and deep studying is for somebody to clarify issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter training and the way complicated Synthetic Intelligence subjects are taught.
In case you’re severe about studying laptop imaginative and prescient, your subsequent cease ought to be PyImageSearch College, probably the most complete laptop imaginative and prescient, deep studying, and OpenCV course on-line right this moment. Right here you’ll discover ways to efficiently and confidently apply laptop imaginative and prescient to your work, analysis, and initiatives. Be a part of me in laptop imaginative and prescient mastery.
Inside PyImageSearch College you may discover:
- &examine; 86+ programs on important laptop imaginative and prescient, deep studying, and OpenCV subjects
- &examine; 86 Certificates of Completion
- &examine; 115+ hours hours of on-demand video
- &examine; Model new programs launched usually, guaranteeing you possibly can sustain with state-of-the-art strategies
- &examine; Pre-configured Jupyter Notebooks in Google Colab
- &examine; Run all code examples in your net browser — works on Home windows, macOS, and Linux (no dev surroundings configuration required!)
- &examine; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
- &examine; Simple one-click downloads for code, datasets, pre-trained fashions, and many others.
- &examine; Entry on cellular, laptop computer, desktop, and many others.
Abstract
On this tutorial, we explored how the discharge of Section Something Mannequin 3 (SAM 3) represents a elementary shift in laptop imaginative and prescient — from geometry-driven segmentation to concept-driven visible understanding. In contrast to SAM 1 and SAM 2, which relied on exterior cues to establish the place an object is, SAM 3 internalizes semantic recognition and permits customers to instantly question what they wish to phase utilizing pure language or visible exemplars.
We examined how this transition is enabled by a unified structure constructed round a shared Notion Encoder, an open-vocabulary DETR-based detector with a Presence Head, and a memory-based tracker for movies. We additionally mentioned how the huge SA-Co dataset and a rigorously staged coaching pipeline permit SAM 3 to scale to thousands and thousands of ideas whereas sustaining sturdy calibration and zero-shot efficiency.
Via sensible examples, we demonstrated find out how to arrange SAM 3 in your growth surroundings and implement single textual content immediate segmentation throughout varied eventualities — from detecting ears on a cat to figuring out birds in a flock and taxis in site visitors.
In Half 2, we’ll dive deeper into superior prompting strategies, together with multi-prompt segmentation, bounding field steerage, unfavourable prompts, and totally interactive segmentation workflows that provide you with pixel-perfect management over your outcomes. Whether or not you’re constructing annotation pipelines, video enhancing instruments, or robotics purposes, Half 2 will present you find out how to harness SAM 3’s full potential by means of refined immediate engineering.
Quotation Data
Thakur, P. “SAM 3: Idea-Primarily based Visible Understanding and Segmentation,” PyImageSearch, P. Chugh, S. Huot, G. Kudriavtsev, and A. Sharma, eds., 2026, https://pyimg.co/uming
@incollection{Thakur_2026_sam-3-concept-based-visual-understanding-and-segmentation,
creator = {Piyush Thakur},
title = {{SAM 3: Idea-Primarily based Visible Understanding and Segmentation}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Georgii Kudriavtsev and Aditya Sharma},
yr = {2026},
url = {https://pyimg.co/uming},
}
To obtain the supply code to this submit (and be notified when future tutorials are printed right here on PyImageSearch), merely enter your e mail handle within the kind under!

Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your e mail handle under to get a .zip of the code and a FREE 17-page Useful resource Information on Laptop Imaginative and prescient, OpenCV, and Deep Studying. Inside you may discover my hand-picked tutorials, books, programs, and libraries that will help you grasp CV and DL!
The submit SAM 3: Idea-Primarily based Visible Understanding and Segmentation appeared first on PyImageSearch.