

{kind=link}
Audit logging has turn into a vital part of database safety and compliance, serving to organizations observe consumer actions, monitor knowledge entry patterns, and preserve detailed information for regulatory necessities and safety investigations. Database audit logs present a complete path of actions carried out throughout the database, together with queries executed, modifications made to knowledge, and consumer authentication makes an attempt. Managing these logs is extra simple with a strong storage answer resembling Amazon Easy Storage Service (Amazon S3).
Amazon Relational Database Service (Amazon RDS) for MySQL and Amazon Aurora MySQL-Suitable Version present built-in audit logging capabilities, however prospects would possibly must export and retailer these logs for long-term retention and evaluation. Amazon S3 affords an excellent vacation spot, offering sturdiness, cost-effectiveness, and integration with numerous analytics instruments.
On this put up, we discover two approaches for exporting MySQL audit logs to Amazon S3: both utilizing batching with a local export to Amazon S3 or processing logs in actual time with Amazon Information Firehose.
Answer overview
The primary answer entails batch processing by utilizing the built-in audit log export function in Amazon RDS for MySQL or Aurora MySQL-Suitable to export logs to Amazon CloudWatch Logs. Amazon EventBridge periodically triggers an AWS Lambda perform. This answer creates a CloudWatch export activity that sends the final one days’s of audit logs to Amazon S3. The interval (in the future) is configurable primarily based in your necessities. This answer is probably the most cost-effective and sensible in case you don’t require the audit logs to be accessible in real-time inside an S3 bucket. The next diagram illustrates this workflow.
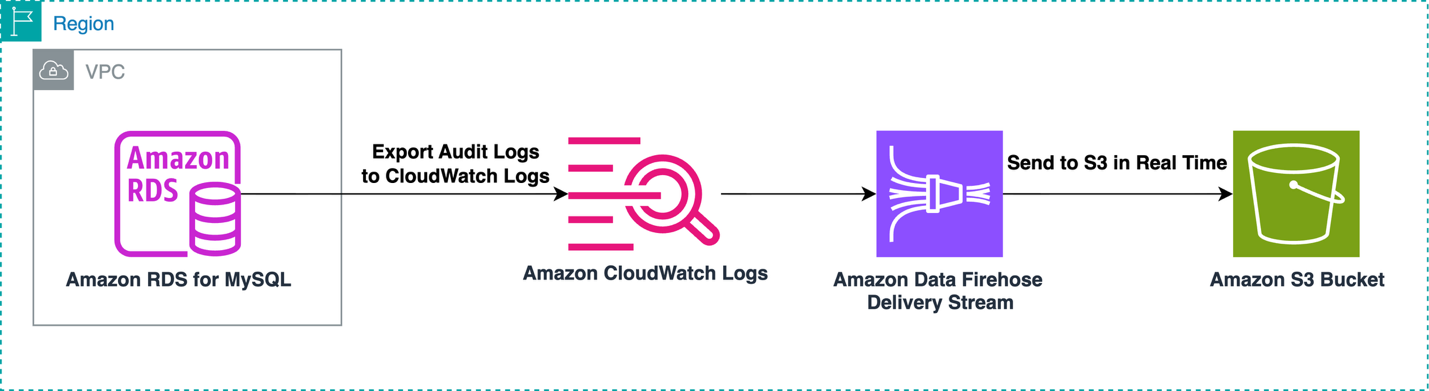
The opposite proposed answer makes use of Information Firehose to right away course of the MySQL audit logs inside CloudWatch Logs and ship them to an S3 bucket. This strategy is appropriate for enterprise use instances that require rapid export of audit logs after they’re accessible inside CloudWatch Logs. The next diagram illustrates this workflow.
Use instances
When you’ve carried out both of those options, you’ll have your Aurora MySQL or RDS for MySQL audit logs saved securely in Amazon S3. This opens up a wealth of prospects for evaluation, monitoring, and compliance reporting. Right here’s what you are able to do together with your exported audit logs:
- Run Amazon Athena queries: Along with your audit logs in S3, you should utilize Amazon Athena to run SQL queries immediately in opposition to your log knowledge. This lets you shortly analyze consumer actions, determine uncommon patterns, or generate compliance stories. For instance, you may question for all actions carried out by a selected consumer, or discover all failed login makes an attempt inside a sure time-frame.
- Create Amazon Fast Sight dashboards: Utilizing Amazon Fast Sight at the side of Athena, you possibly can create visible dashboards of your audit log knowledge. This might help you see developments over time, resembling peak utilization hours, most energetic customers, or continuously accessed database objects.
- Arrange automated alerting: By combining your S3-stored logs with AWS Lambda and Amazon SNS, you possibly can create automated alerts for particular occasions. For example, you may arrange a system to inform safety personnel if there’s an uncommon spike in failed login makes an attempt or if delicate tables are accessed outdoors of enterprise hours.
- Carry out long-term evaluation: Along with your audit logs centralized in S3, you possibly can carry out long-term pattern evaluation. This might show you how to perceive how database utilization patterns change over time, informing capability planning and safety insurance policies.
- Meet compliance necessities: Many regulatory frameworks require retention and evaluation of database audit logs. Along with your logs in S3, you possibly can simply reveal compliance with these necessities, working stories as wanted for auditors.
By leveraging these capabilities, you possibly can flip your audit logs from a passive safety measure into an energetic instrument for database administration, safety enhancement, and enterprise intelligence.
Evaluating options
The primary answer used EventBridge to periodically set off a Lambda perform. This perform creates a CloudWatch Log export activity that sends a batch of log knowledge to Amazon S3 at common intervals. This methodology is well-suited for eventualities the place you favor to course of logs in batches to optimize prices and assets.
The second answer makes use of Information Firehose to create a real-time audit log processing pipeline. This strategy streams logs immediately from CloudWatch to an S3 bucket, offering close to real-time entry to your audit knowledge. On this context, “real-time” signifies that log knowledge is processed and delivered synchronously as it’s generated, somewhat than being despatched in a pre-defined interval. This answer is good for eventualities requiring rapid entry to log knowledge or for high-volume logging environments.
Whether or not you select the close to real-time streaming strategy or the scheduled export methodology, you may be well-equipped to managed your Aurora MySQL and RDS for MySQL audit logs successfully.
Stipulations for each options
Earlier than getting began, full the next conditions:
- Create or have an present RDS for MySQL occasion or Aurora MySQL cluster.
- Allow audit logging:
- For Amazon RDS, add the MariaDB Audit Plugin inside your possibility group.
- For Aurora, allow Superior Auditing inside your parameter group.
Word: In audit logging, by default all customers are logged which might doubtlessly be pricey.
- Publish MySQL audit logs to CloudWatch Logs.
- Ensure you have a terminal with the AWS Command Line Interface (AWS CLI) put in or use AWS CloudShell inside your console.
- Create an S3 bucket to retailer the MySQL audit logs utilizing the under AWS CLI command:
aws s3api create-bucket --bucket
After the command is full, you will note an output just like the next:
Word: Every answer has particular service parts that are mentioned of their respective sections.
Answer #1: Peform audit log batch processing with EventBridge and Lambda
On this answer, we create a Lambda perform to export your audit log to Amazon S3 primarily based on the schedule you set utilizing EventBridge Scheduler. This answer affords a cost-efficient strategy to switch audit log recordsdata inside an S3 bucket in a scheduled method.
Create IAM function for EventBridge Scheduler
Step one is to create an AWS Id and Entry Administration (IAM) function answerable for permitting EventBridge Scheduler to invoke the Lambda perform we are going to create later. Full the next steps to create this function:
- Hook up with a terminal with the AWS CLI or CloudShell.
- Create a file named
TrustPolicyForEventBridgeScheduler.jsonutilizing your most popular textual content editor:
nano TrustPolicyForEventBridgeScheduler.json
- Insert the next belief coverage into the JSON file:
Word: Ensure to amend SourceAccount earlier than saving right into a file. The situation is used to prevents unauthorized entry from different AWS accounts.
- Create a file named
PermissionsForEventBridgeScheduler.jsonutilizing your most popular textual content editor:
nano PermissionsForEventBridgeScheduler.json
- Insert the next permissions into the JSON file:
Word: Exchange
- Use the next AWS CLI command to create the IAM function for EventBridge Scheduler to invoke the Lambda perform:
- Create the IAM coverage and fix it to the beforehand created IAM function:
On this part, we created an IAM function with applicable belief and permissions insurance policies that enable EventBridge Scheduler to securely invoke Lambda features out of your AWS account. Subsequent, we’ll create one other IAM function that defines the permissions that your Lambda perform must execute its duties.
Create IAM function for Lambda
The following step is to create an IAM function answerable for permitting Lambda to place information from CloudWatch into your S3 bucket. Full the next steps to create this function:
- Hook up with a terminal with the AWS CLI or CloudShell.
- Create and write to a JSON file for the IAM belief coverage utilizing your most popular textual content editor:
nano TrustPolicyForLambda.json
- Insert the next belief coverage into the JSON file:
- Use the next AWS CLI command to create the IAM function for Lambda to insert information from CloudWatch to Amazon S3:
- Create a file named
PermissionsForLambda.jsonutilizing your most popular textual content editor:
nano PermissionsForLambda.json
- Insert the next permissions into the JSON file:
- Create the IAM coverage and fix it to the beforehand created IAM function:
Create ZIP file for the Python Lambda perform
To create a file with the code the Lambda perform will invoke, full the next steps:
- Create and write to a file named
lambda_function.pyutilizing your most popular textual content editor:
nano lambda_function.py
- Inside the file, insert the next code:
- Zip the file utilizing the next command:
zip perform.zip lambda_function.py
Create Lambda perform
Full the next steps to create a Lambda perform:
- Hook up with a terminal with the AWS CLI or CloudShell.
- Run the next command, which references the zip file beforehand created:
The NDAYS variable within the previous command will decide the dates of audit logs exported per invocation of the Lambda perform. For instance, in case you plan on exporting logs one time per day to Amazon S3, set NDAYS=1, as proven within the previous command.
- Add concurrency limits to maintain executions in management:
Word: Reserved concurrency in Lambda units a set restrict on what number of cases of your perform can run concurrently, like having a selected variety of staff for a activity. On this database export situation, we’re limiting it to 2 concurrent executions to forestall overwhelming the database, keep away from API throttling, and guarantee clean, managed exports. This limitation helps preserve system stability, prevents useful resource rivalry, and retains prices in verify
On this part, we created a Lambda perform that can deal with the CloudWatch log exports, configured its important parameters together with surroundings variables, and set a concurrency restrict to make sure managed execution. Subsequent, we’ll create an EventBridge schedule that can routinely set off this Lambda perform at specified intervals to carry out the log exports.
Create EventBridge schedule
Full the next steps to create an EventBridge schedule to invoke the Lambda perform at an interval of your selecting:
- Hook up with a terminal with the AWS CLI or CloudShell.
- Run the next command:
The schedule-expression parameter within the previous command should be equal to the environmental variable NDAYS within the beforehand created Lambda perform.
This answer gives an environment friendly, scheduled strategy to exporting RDS audit logs to Amazon S3 utilizing AWS Lambda and EventBridge Scheduler. By leveraging these serverless parts, we’ve created a cheap, automated system that periodically transfers audit logs to S3 for long-term storage and evaluation. This methodology is especially helpful for organizations that want common, batch-style exports of their database audit logs, permitting for simpler compliance reporting and historic knowledge evaluation.
Whereas the primary answer affords a scheduled, batch-processing strategy, some eventualities require a extra real-time answer for audit log processing. In our subsequent answer, we’ll discover how you can create a close to real-time audit log processing system utilizing Amazon Kinesis Information Firehose. This strategy will enable for steady streaming of audit logs from RDS to S3, offering nearly rapid entry to log knowledge.
Answer 2: Create close to real-time audit log processing with Amazon Information Firehose
On this part, we evaluation how you can create a close to real-time audit log export to Amazon S3 utilizing the facility of Information Firehose. With this answer, you possibly can immediately load the most recent audit log recordsdata to an S3 bucket for fast evaluation, manipulation, or different functions.
Create IAM function for CloudWatch Logs
Step one is to create an IAM function answerable for permitting CloudWatch Logs to place information into the Firehose supply stream (CWLtoDataFirehoseRole). Full the next steps to create this function:
- Hook up with a terminal with the AWS CLI or CloudShell.
- Create and write to a JSON file for the IAM belief coverage utilizing your most popular textual content editor:
nano TrustPolicyForCWL.json
- Insert the next belief coverage into the JSON file:
- Create and write to a brand new JSON file for the IAM permissions coverage utilizing your most popular textual content editor:
nano PermissionsForCWL.json
- Insert the next permissions into the JSON file:
- Use the next AWS CLI command to create the IAM function for CloudWatch Logs to insert information into the Firehose supply stream:
- Create the IAM coverage and fix it to the beforehand created IAM function:
Create IAM function for Firehose supply stream
The following step is to create an IAM function (DataFirehosetoS3Role) answerable for permitting the Firehose supply stream to insert the audit logs into an S3 bucket. Full the next steps to create this function:
- Hook up with a terminal with the AWS CLI or CloudShell.
- Create and write to a JSON file for the IAM belief coverage utilizing your most popular textual content editor:
nano PermissionsForCWL.json
- Insert the next belief coverage into the JSON file:
- Create and write to a brand new JSON file for the IAM permissions utilizing your most popular textual content editor:
nano PermissionsForCWL.json
- Insert the next permissions into the JSON file:
- Use the next AWS CLI command to create the IAM function for Information Firehose to carry out operations on the S3 bucket:
- Create the IAM coverage and fix it to the beforehand created IAM function:
Create the Firehose supply stream
Now you create the Firehose supply stream to permit close to real-time switch of MySQL audit logs from CloudWatch Logs to your S3 bucket. Full the next steps:
- Create the Firehose supply stream with the next AWS CLI command. Setting the buffer interval and dimension determines how lengthy your knowledge is buffered earlier than being delivered to the S3 bucket. For extra data, seek advice from AWS documentation. On this instance, we use the default values:
- Wait till the Firehose supply stream turns into energetic (this would possibly take a couple of minutes). You should use the Firehose CLI
describe-delivery-streamcommand to verify the standing of the supply stream. Word theDeliveryStreamDescription.DeliveryStreamARNworth, to make use of in a later step:
aws firehose describe-delivery-stream --delivery-stream-name
- After the Firehose supply stream is in an energetic state, create a CloudWatch Logs subscription filter. This subscription filter instantly begins the circulate of close to real-time log knowledge from the chosen log group to your Firehose supply stream. Ensure to supply the log group title that you simply wish to push to Amazon S3 and correctly copy the
destination-arnof your Firehose supply stream:
Your close to real-time MySQL audit log answer is now correctly configured and can start delivering MySQL audit logs to your S3 bucket via the Firehose supply stream.
Clear up
To wash up your assets, full the next steps (relying on which answer you used):
- Delete the RDS occasion or Aurora cluster.
- Delete the Lambda features.
- Delete the EventBridge rule.
- Delete the S3 bucket.
- Delete the Firehose supply stream.
Conclusion
On this put up, we’ve offered two options for managing Aurora MySQL or RDS for MySQL audit logs, every providing distinctive advantages for various enterprise use instances.
We encourage you to implement these options in your individual surroundings and share your experiences, challenges, and success tales within the feedback part. Your suggestions and real-world implementations might help fellow AWS customers select and adapt these options to greatest match their particular audit logging wants.
Concerning the authors