

{kind=link}
Data is available in many shapes and types. Whereas retrieval-augmented era (RAG) primarily focuses on plain textual content, it overlooks huge quantities of knowledge alongside the way in which. Most enterprise data resides in complicated paperwork, slides, graphics, and different multimodal sources. But, extracting helpful data from these codecs utilizing optical character recognition (OCR) or different parsing methods is commonly low-fidelity, brittle, and costly.
Imaginative and prescient RAG makes complicated paperwork—together with their figures and tables—searchable by utilizing multimodal embeddings, eliminating the necessity for complicated and dear textual content extraction. This information explores how Voyage AI’s newest mannequin powers this functionality and offers a step-by-step implementation walkthrough.
Imaginative and prescient RAG: Constructing upon textual content RAG
Imaginative and prescient RAG is an evolution of conventional RAG constructed on the identical two parts: retrieval and era.
In conventional RAG, unstructured textual content information is listed for semantic search. At question time, the system retrieves related paperwork or chunks and appends them to the person’s immediate so the massive language mannequin (LLM) can produce extra grounded, context-aware solutions.
Determine 1. Textual content RAG with Voyage AI and MongoDB.
Enterprise information, nonetheless, isn’t simply clear plain textual content. Vital data typically lives in PDFs, slides, diagrams, dashboards, and different visible codecs. At the moment, that is sometimes dealt with by parsing instruments and OCR providers. These approaches create a number of issues:
-
Important engineering effort to deal with many file sorts, layouts, and edge instances
-
Accuracy points throughout completely different OCR or parsing setups
-
Excessive prices when scaled throughout giant doc collections
Subsequent-generation multimodal embedding fashions present an easier and less expensive different. They will ingest not solely textual content but additionally photographs or screenshots of complicated doc layouts, and generate vector representations that seize the which means and construction of that content material.
Imaginative and prescient RAG makes use of these multimodal embeddings to index total paperwork, slides, and pictures straight, even once they comprise interleaved textual content and pictures. This permits them to be searchable through vector search with out requiring heavy parsing or OCR. At question time, the system retrieves essentially the most related visible belongings and feeds them, together with the textual content immediate, right into a vision-capable LLM to tell its reply.
Determine 2. Imaginative and prescient RAG with Voyage AI and MongoDB.
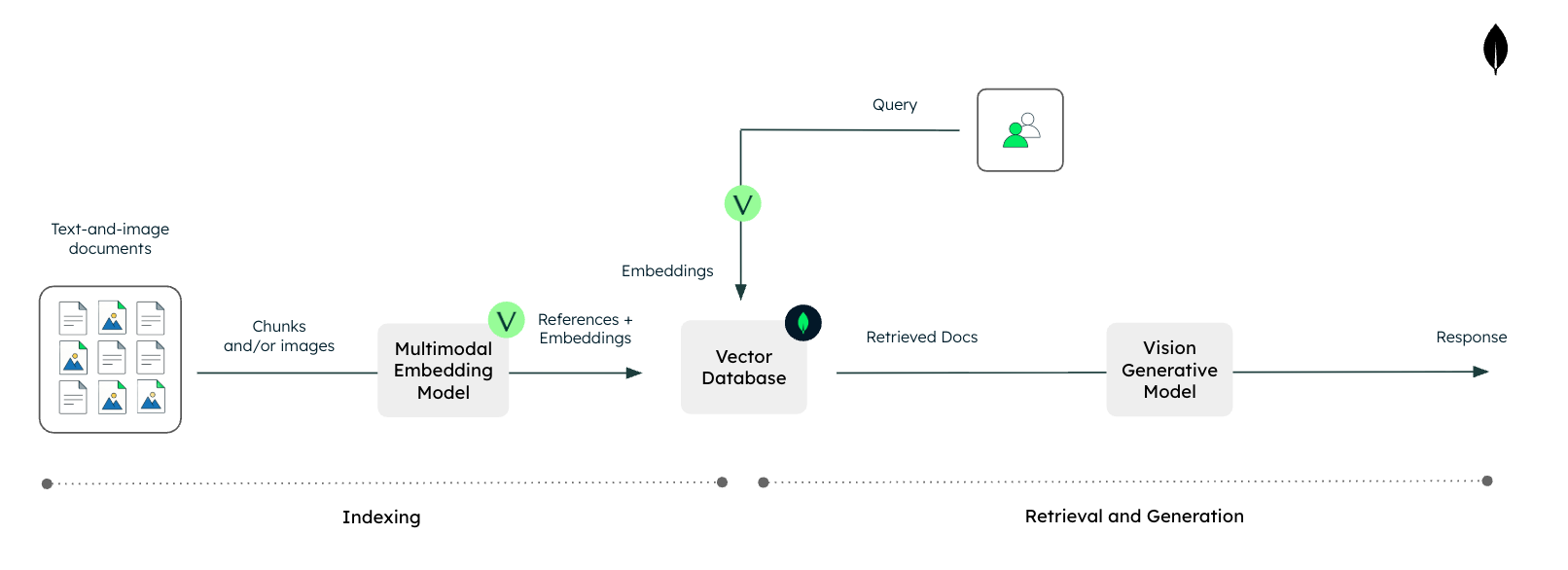
Consequently, imaginative and prescient RAG permits LLM-based programs with native entry to wealthy, multimodal enterprise information, whereas lowering engineering complexity and avoiding the efficiency and price pitfalls related to conventional text-focused preprocessing pipelines.
Voyage AI’s newest multimodal embedding mannequin
The multimodal embedding mannequin is the place the magic occurs. Traditionally, constructing such a system was difficult because of the modality hole. Early multimodal embedding fashions, reminiscent of contrastive language-image pretraining (CLIP)-based fashions, processed textual content and pictures utilizing separate encoders. As a result of the outputs have been generated independently, outcomes have been typically biased towards one modality, making retrieval throughout combined content material unreliable. These fashions additionally struggled to deal with interleaved textual content and pictures, a vital limitation for imaginative and prescient RAG in real-world environments.
Voyage-multimodal-3 adopts an structure just like trendy vision-capable LLMs. It makes use of a single encoder for each textual content and visible inputs, closing the modality hole and producing unified representations. This ensures that textual and visible options are handled persistently and precisely throughout the similar vector house.
Determine 3. CLIP-based structure vs. voyage-multimodal-3’s structure.
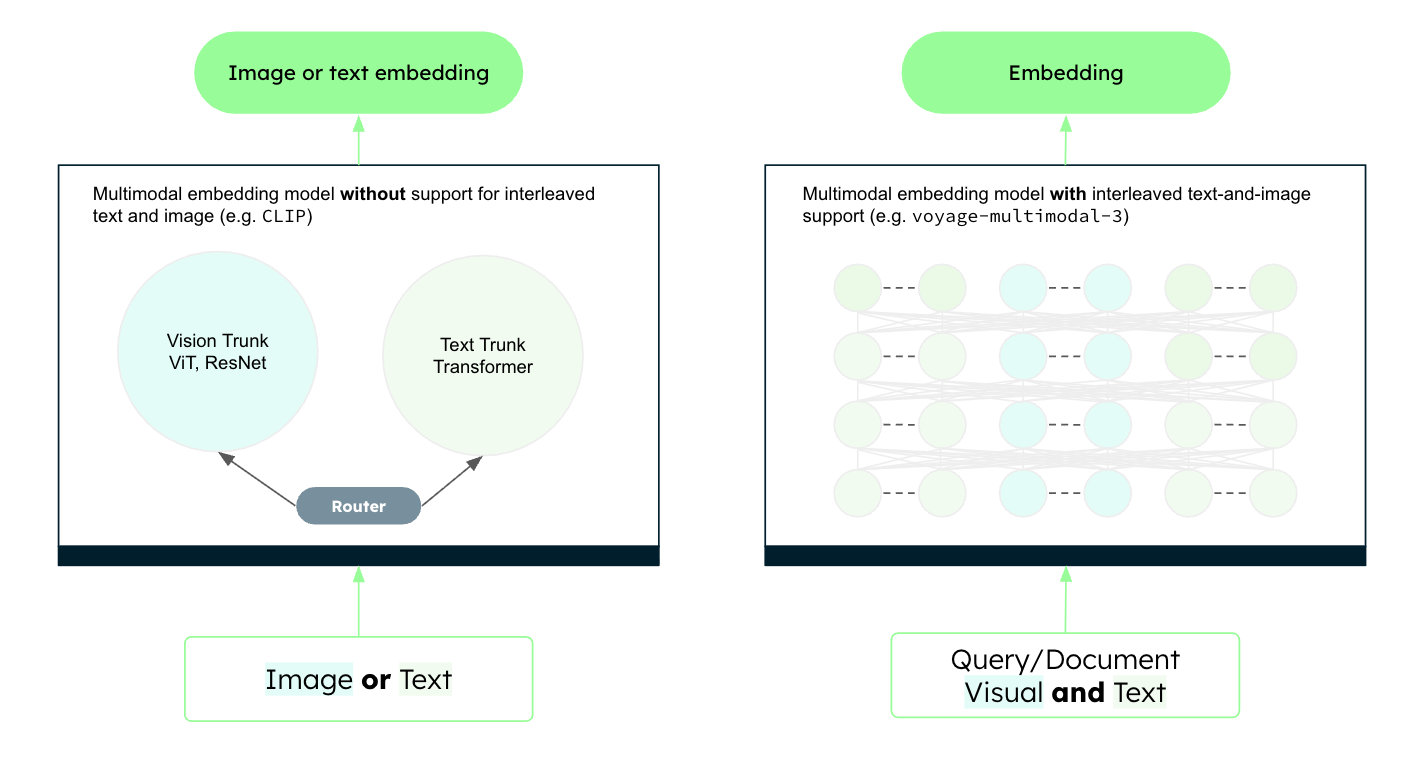
This architectural shift permits true multimodal retrieval, making imaginative and prescient RAG a viable and environment friendly resolution. For extra particulars, check with the voyage-multimodal-3 weblog announcement.
Implementation of imaginative and prescient RAG
Let’s take a easy instance and showcase implement imaginative and prescient RAG. Conventional text-based RAG typically struggles with complicated paperwork, reminiscent of slide decks, monetary stories, or technical papers, the place vital data is commonly locked inside charts, diagrams, and figures.
By utilizing Voyage AI’s multimodal embedding fashions alongside Anthropic’s vision-capable LLMs, we are able to bridge this hole. We are going to deal with photographs (or screenshots of doc pages) as first-class residents, retrieving them straight based mostly on their visible and semantic content material and passing them to a vision-capable LLM for reasoning.
To reveal this, we are going to construct a pipeline that extracts insights from the charts and figures of the GitHub Octoverse 2025 survey, which simulates the kind of data sometimes present in enterprise information.
The Jupyter Pocket book for this tutorial is on the market on GitHub in our GenAI Showcase repository. To comply with alongside, run the pocket book in Google Colab (or comparable), and check with this tutorial for explanations of key code blocks.
Step 1: Set up needed libraries
First, we have to arrange our Python setting. We are going to set up the voyageai consumer for producing embeddings and the anthropic consumer for our generative mannequin.
Step 2: Initialize API shoppers
To work together with the fashions, it’s essential to initialize the consumer objects along with your API keys. You will want a Voyage AI API key (for the voyage-multimodal-3 mannequin) and an Anthropic API key (for claude-sonnet-4.5).
Be aware: It’s best follow to make use of setting variables or a secret supervisor relatively than hardcoding keys in manufacturing.
Step 3: Extract visible content material
For this instance, we are going to scrape charts and infographics straight from the GitHub Octoverse weblog publish. In a manufacturing setting, this step would possibly contain changing PDF pages to photographs or processing a listing of PNGs.
We’ll begin by importing the usual utilities we want for net requests, picture processing, and math operations.
Subsequent, we outline a helper operate extract_image_urls to parse the article’s HTML and seize picture hyperlinks, filtering out small icons or logos.
Now let’s run the extraction on the particular URL.
The scraping would possibly return basic weblog belongings. To make sure excessive relevance, we are going to filter the record to solely embody photographs containing “octoverse-2025” of their URL, which targets the report’s charts.
Step 4: Construct the multimodal index
That is the core indexing step. We loop via our filtered URLs, obtain the pictures domestically, after which move them to Voyage AI’s voyage-multimodal-3 mannequin. This mannequin converts the visible content material right into a dense vector embedding.
Step 5: Outline RAG parts
We want three particular capabilities to make our RAG pipeline work:
-
Picture Encoding: Changing photographs to base64 to allow them to be despatched to the Anthropic API
-
Vector Retrieval: Looking our array of embeddings to search out the picture most semantically just like the person’s textual content question
-
Technology: Sending the retrieved picture and the person’s question to a VLM to get a pure language reply.
Let’s outline helper features for every.
In order for you a full end-to-end instance utilizing MongoDB, see this tutorial: Constructing Multimodal AI Functions with MongoDB, Voyage AI, and Gemini.
Step 6: Mix the parts into a whole pipeline
We are able to now wrap these steps right into a single entry level, vision_rag. This operate accepts a person question, performs the retrieval to search out the right chart, shows it, after which solutions the query.
Step 7: Run queries
Let’s check our pipeline. We are going to ask a particular query about developer communities. The system ought to determine the right infographic from the report and skim the info straight from it.
Now we are able to attempt a quantitative query concerning open-source repositories.
And at last, a rating query about programming languages.
Conclusion
Multimodal embeddings, paired with vision-capable LLMs, allow programs to course of and cause throughout numerous information sorts like textual content and pictures concurrently. Imaginative and prescient RAG particularly unlocks the huge quantity of data trapped in visible codecs containing interleaved textual content and pictures —reminiscent of slide decks, images, PDF stories, and technical diagrams—that conventional text-only pipelines wrestle with.
On this tutorial, we applied a minimalist imaginative and prescient RAG pipeline from scratch. We extracted wealthy visible information from the GitHub Octoverse report, generated multimodal embeddings utilizing Voyage AI, and used Anthropic’s mannequin to reply complicated questions grounded in visible proof.
As you progress ahead, contemplate how this structure might be utilized to your personal proprietary datasets, from monetary stories to inside diagrams. If you find yourself able to take this into manufacturing, discover utilizing a sturdy database like MongoDB to deal with scale. For extra examples and superior methods, take a look at the Voyage AI documentation to proceed constructing the subsequent era of multimodal functions.
In the event you loved studying this tutorial, you may discover extra such content material on our AI Studying Hub. If you wish to go straight to code, we’ve a number of extra examples of construct RAG, agentic functions, evals, and so forth., in our Gen AI Showcase GitHub repository. As at all times, you probably have additional questions as you construct your AI functions, please attain out to us in our generative AI group boards.