

{kind=link}
At Amazon.ae, we serve roughly 10 million clients month-to-month throughout 5 nations within the Center East and North Africa area—United Arab Emirates (UAE), Saudi Arabia, Egypt, Türkiye, and South Africa. Our AMET (Africa, Center East, and Türkiye) Funds crew manages fee picks, transactions, experiences, and affordability options throughout these various nations, publishing on common 5 new options month-to-month. Every function requires complete check case era, which historically consumed 1 week of handbook effort per challenge. Our high quality assurance (QA) engineers spent this time analyzing enterprise requirement paperwork (BRDs), design paperwork, UI mocks, and historic check preparations—a course of that required one full-time engineer yearly merely for check case creation.
To enhance this handbook course of, we developed SAARAM (QA Lifecycle App), a multi-agent AI answer that helps scale back check case era from 1 week to hours. Utilizing Amazon Bedrock with Claude Sonnet by Anthropic and the Strands Brokers SDK, we diminished the time wanted to generate check circumstances from 1 week to mere hours whereas additionally bettering check protection high quality. Our answer demonstrates how learning human cognitive patterns, fairly than optimizing AI algorithms alone, can create production-ready techniques that improve fairly than change human experience.
On this publish, we clarify how we overcame the constraints of single-agent AI techniques by way of a human-centric method, applied structured outputs to considerably scale back hallucinations and constructed a scalable answer now positioned for enlargement throughout the AMET QA crew and later throughout different QA groups in Worldwide Rising Shops and Funds (IESP) Org.
Resolution overview
The AMET Funds QA crew validates code deployments affecting fee performance for hundreds of thousands of shoppers throughout various regulatory environments and fee strategies. Our handbook check case era course of added turnaround time (TAT) within the product cycle, consuming precious engineering assets on repetitive check prep and documentation duties fairly than strategic testing initiatives. We wanted an automatic answer that would preserve our high quality requirements whereas lowering the time funding.
Our aims included lowering check case creation time from 1 week to beneath a couple of hours, capturing institutional information from skilled testers, standardizing testing approaches throughout groups, and minimizing the hallucination points widespread in AI techniques. The answer wanted to deal with advanced enterprise necessities spanning a number of fee strategies, regional rules, and buyer segments whereas producing particular, actionable check circumstances aligned with our present check administration techniques.
The structure employs a complicated multi-agent workflow. To attain this, we went by way of 3 totally different iterations and proceed to enhance and improve as new methods are developed and new fashions are deployed.
The problem with conventional AI approaches
Our preliminary makes an attempt adopted standard AI approaches, feeding whole BRDs to a single AI agent for check case era. This technique regularly produced generic outputs like “confirm fee works appropriately” as a substitute of the precise, actionable check circumstances our QA crew requires. For instance, we want check circumstances as particular as “confirm that when a UAE buyer selects money on supply (COD) for an order above 1,000 AED with a saved bank card, the system shows the COD payment of 11 AED and processes the fee by way of the COD gateway with order state transitioning to ‘pending supply.’”
The only-agent method introduced a number of crucial limitations. Context size restrictions prevented processing giant paperwork successfully, however the lack of specialised processing phases meant the AI couldn’t perceive testing priorities or risk-based approaches. Moreover, hallucination points created irrelevant check eventualities that would mislead QA efforts. The basis trigger was clear: AI tried to compress advanced enterprise logic with out the iterative pondering course of that skilled testers make use of when analyzing necessities.
The next circulation chart illustrates our points when making an attempt to make use of a single agent with a complete immediate.
The human-centric breakthrough
Our breakthrough got here from a elementary shift in method. As a substitute of asking, “How ought to AI take into consideration testing?”, we requested, “How do skilled people take into consideration testing?” to give attention to following a particular step-by-step course of as a substitute of counting on the giant language mannequin (LLM) to comprehend this by itself. This philosophy change led us to conduct analysis interviews with senior QA professionals, learning their cognitive workflows intimately.
We found that skilled testers don’t course of paperwork holistically—they work by way of specialised psychological phases. First, they analyze paperwork by extracting acceptance standards, figuring out buyer journeys, understanding UX necessities, mapping product necessities, analyzing consumer information, and assessing workstream capabilities. Then they develop exams by way of a scientific course of: journey evaluation, situation identification, information circulation mapping, check case improvement, and eventually, group and prioritization.
We then decomposed our authentic agent into sequential pondering actions that served as particular person steps. We constructed and examined every step utilizing Amazon Q Developer for CLI to verify primary concepts have been sound and integrated each major and secondary inputs.
This perception led us to design SAARAM with specialised brokers that mirror these skilled testing approaches. Every agent focuses on a particular facet of the testing course of, comparable to how human consultants mentally compartmentalize totally different evaluation phases.
Multi-agent structure with Strands Brokers
Primarily based on our understanding of human QA workflows, we initially tried to construct our personal brokers from scratch. We needed to create our personal looping, serial, or parallel execution. We additionally created our personal orchestration and workflow graphs, which demanded appreciable handbook effort. To handle these challenges, we migrated to Strands Brokers SDK. This offered the multi-agent orchestration capabilities important for coordinating advanced, interdependent duties whereas sustaining clear execution paths, serving to enhance our efficiency and scale back our improvement time.
Workflow iteration 1: Finish-to-end check era
Our first iteration of SAARAM consisted of a single enter and created our first specialised brokers. It concerned processing a piece doc by way of 5 specialised brokers to generate complete check protection.
Agent 1 is named the Buyer Section Creator, and it focuses on buyer segmentation evaluation, utilizing 4 subagents:
- Buyer Section Discovery identifies product consumer segments
- Determination Matrix Generator creates parameter-based matrices
- E2E Situation Creation develops end-to-end (E2E) eventualities per phase
- Check Steps Era detailed check case improvement
Agent 2 is named the Consumer Journey Mapper, and it employs 4 subagents to map product journeys comprehensively:
- The Stream Diagram and Sequence Diagram are creators utilizing Mermaid syntax.
- The E2E Situations generator builds upon these diagrams.
- The Check Steps Generator is used for detailed check documentation.
Agent 3 is named Buyer Section x Journey Protection, and it combines inputs from brokers 1 and a pair of to create detailed segment-specific analyses. It makes use of 4 subagents:
Agent 4 is named the State Transition Agent. It analyzes numerous product state factors in buyer journey flows. Its sub-agents create Mermaid state diagrams representing totally different journey states, segment-specific state situation diagrams, and generate associated check eventualities and steps.
The workflow, proven within the following diagram, concludes with a primary extract, rework, and cargo (ETL) course of that consolidates and deduplicates the information from the brokers, saving the ultimate output as a textual content file.
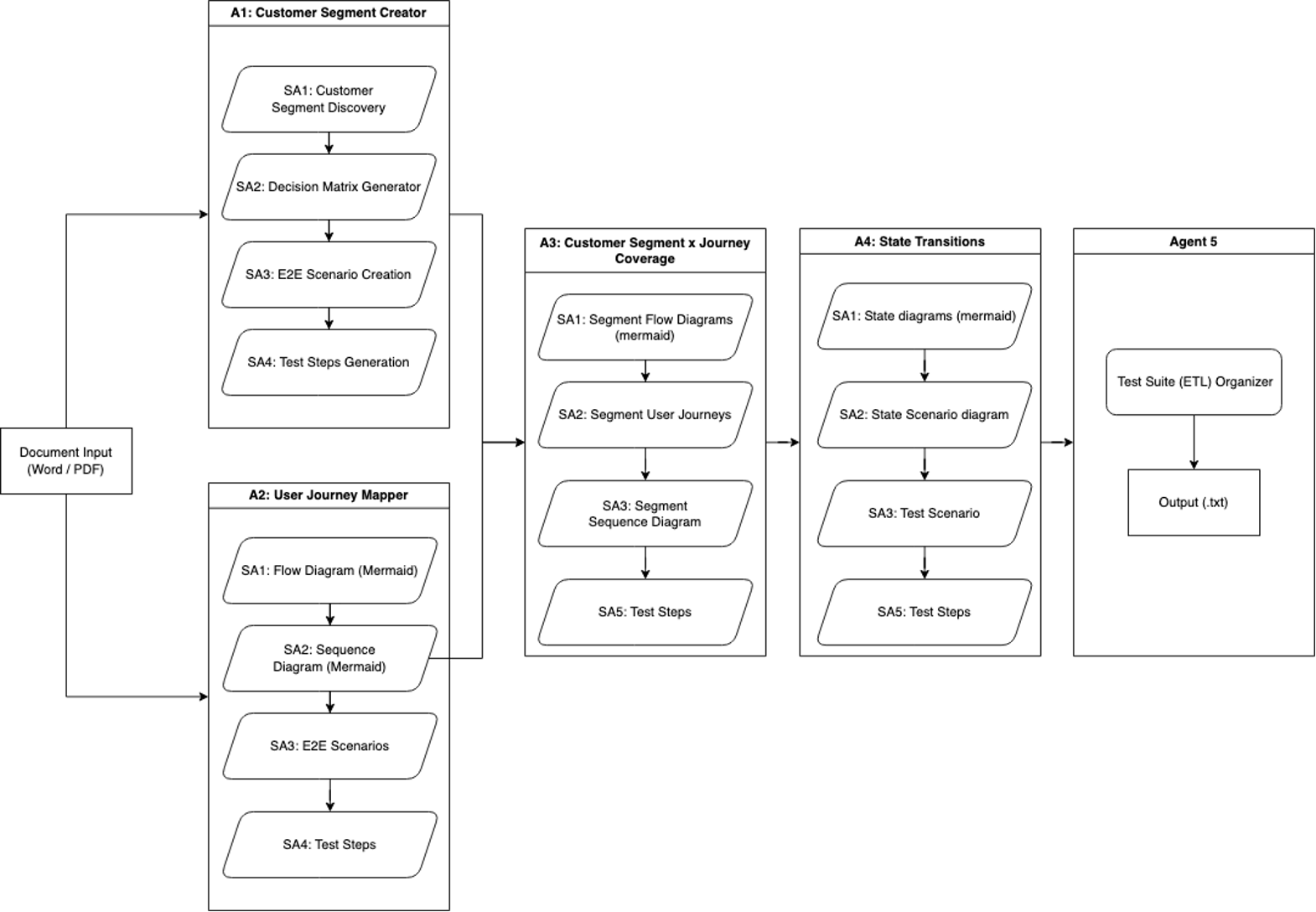
This systematic method facilitates complete protection of buyer journeys, segments, and numerous diagram sorts, enabling thorough check protection era by way of iterative processing by brokers and subagents.
Addressing limitations and enhancing capabilities
In our journey to develop a extra sturdy and environment friendly device utilizing Strands Brokers, we recognized 5 essential limitations in our preliminary method:
- Context and hallucination challenges – Our first workflow confronted limitations from segregated agent operations the place particular person brokers independently collected information and created visible representations. This isolation led to restricted contextual understanding, leading to diminished accuracy and elevated hallucinations within the outputs.
- Information era inefficiencies – The restricted context accessible to brokers brought on one other crucial situation: the era of extreme irrelevant information. With out correct contextual consciousness, brokers produced much less targeted outputs, resulting in noise that obscured precious insights.
- Restricted parsing capabilities – The preliminary system’s information parsing scope proved too slender, restricted to solely buyer segments, journey mapping, and primary necessities. This restriction prevented brokers from accessing the complete spectrum of data wanted for complete evaluation.
- Single-source enter constraint – The workflow may solely course of Phrase paperwork, creating a big bottleneck. Trendy improvement environments require information from a number of sources, and this limitation prevented holistic information assortment.
- Inflexible structure issues – Importantly, the primary workflow employed a tightly coupled system with inflexible orchestration. This structure made it tough to switch, prolong, or reuse parts, limiting the system’s adaptability to altering necessities.
In our second iteration, we wanted to implement strategic options to deal with these points.
Workflow iteration 2: Complete evaluation workflow
Our second iteration represents a whole reimagining of the agentic workflow structure. Quite than patching particular person issues, we rebuilt from the bottom up with modularity, context-awareness, and extensibility as core rules:
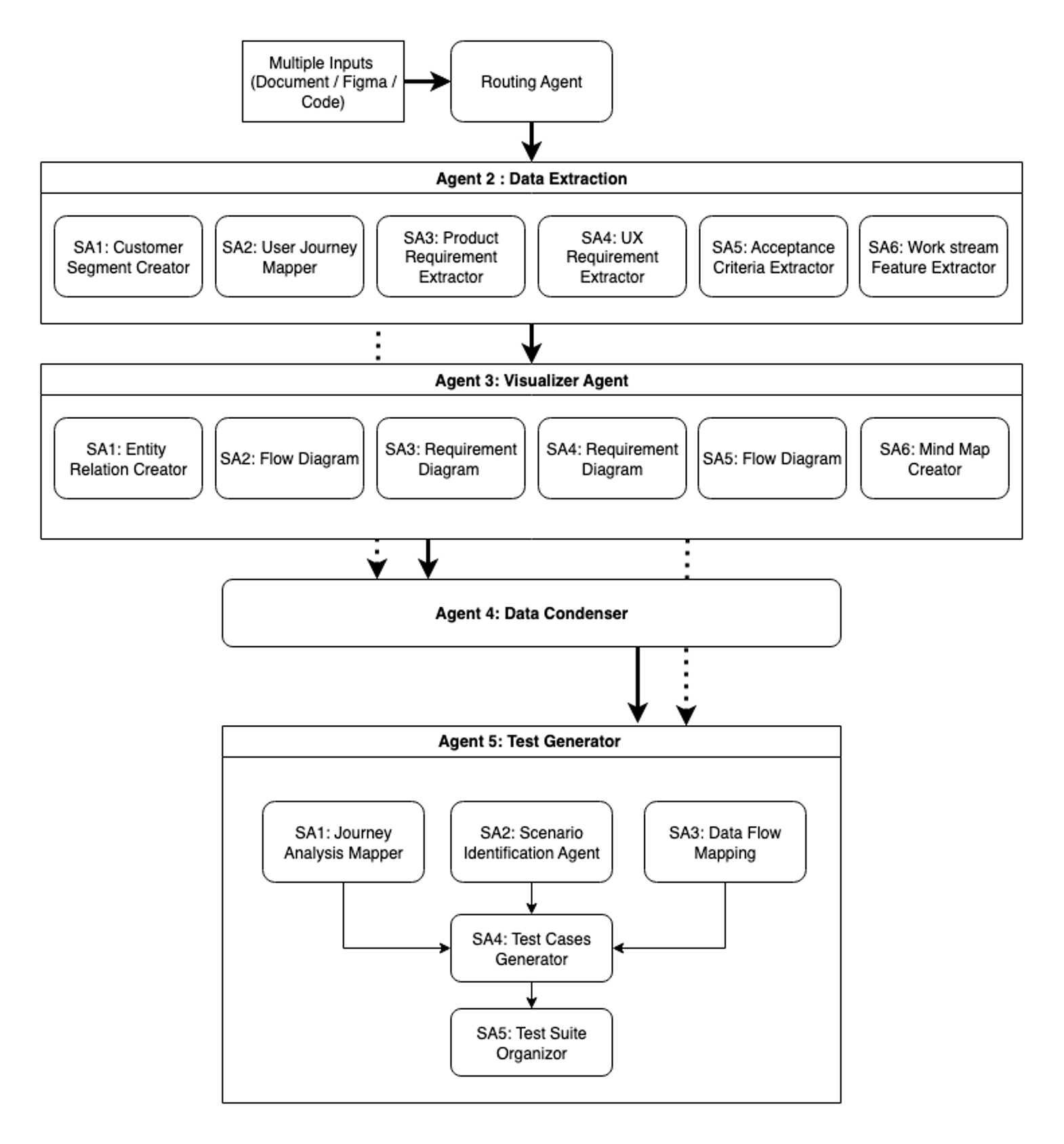
Agent 1 is the clever gateway. The file sort choice agent serves because the system’s entry level and router. Processing documentation recordsdata, Figma designs, and code repositories, it categorizes and directs information to acceptable downstream brokers. This clever routing is crucial for sustaining each effectivity and accuracy all through the workflow.
Agent 2 is for specialised information extraction. The Information Extractor agent employs six specialised subagents, every targeted on particular extraction domains. This parallel processing method facilitates thorough protection whereas sustaining sensible velocity. Every subagent operates with domain-specific information, extracting nuanced info that generalized approaches may overlook.
Agent 3 is the Visualizer agent, and it transforms extracted information into six distinct Mermaid diagram sorts, every serving particular analytical functions. Entity relation diagrams map information relationships and constructions, and circulation diagrams visualize processes and workflows. Requirement diagrams make clear product specs, and UX requirement visualizations illustrate consumer expertise flows. Course of circulation diagrams element system operations, and thoughts maps reveal function relationships and hierarchies. These visualizations present a number of views on the identical info, serving to each human reviewers and downstream brokers perceive patterns and connections inside advanced datasets.
Agent 4 is the Information Condenser agent, and it performs essential synthesis by way of clever context distillation, ensuring every downstream agent receives precisely the data wanted for its specialised process. This agent, powered by its condensed info generator, merges outputs from each the Information Extractor and Visualizer brokers whereas performing subtle evaluation.
The agent extracts crucial parts from the complete textual content context—acceptance standards, enterprise guidelines, buyer segments, and edge circumstances—creating structured summaries that protect important particulars whereas lowering token utilization. It compares every textual content file with its corresponding Mermaid diagram, capturing info that is perhaps missed in visible representations alone. This cautious processing maintains info integrity throughout agent handoffs, ensuring necessary information shouldn’t be misplaced because it flows by way of the system. The result’s a set of condensed addendums that enrich the Mermaid diagrams with complete context. This synthesis makes certain that when info strikes to check era, it arrives full, structured, and optimized for processing.
Agent 5 is the Check Generator agent brings collectively the collected, visualized, and condensed info to provide complete check suites. Working with six Mermaid diagrams plus condensed info from Agent 4, this agent employs a pipeline of 5 subagents. The Journey Evaluation Mapper, Situation Identification Agent, and the Information Stream Mapping subagents generate complete check circumstances primarily based on their take of the enter information flowing from Agent 4.With the check circumstances generated throughout three crucial views, the Check Instances Generator evaluates them, reformatting based on inner pointers for consistency. Lastly, the Check Suite Organizer performs deduplication and optimization, delivering a closing check suite that balances comprehensiveness with effectivity.
The system now handles excess of the essential necessities and journey mapping of Workflow 1—it processes product necessities, UX specs, acceptance standards, and workstream extraction whereas accepting inputs from Figma designs, code repositories, and a number of doc sorts. Most significantly, the shift to modular structure essentially modified how the system operates and evolves. Not like our inflexible first workflow, this design permits for reusing outputs from earlier brokers, integrating new testing sort brokers, and intelligently deciding on check case mills primarily based on consumer necessities, positioning the system for steady adaptation.
The next determine exhibits our second iteration of SAARAM with 5 principal brokers and a number of subagents with context engineering and compression.
Extra Strands Brokers options
Strands Brokers offered the muse for our multi-agent system, providing a model-driven method that simplified advanced agent improvement. As a result of the SDK can join fashions with instruments by way of superior reasoning capabilities, we constructed subtle workflows with only some strains of code. Past its core performance, two key options proved important for our manufacturing deployment: lowering hallucinations with structured outputs and workflow orchestration.
Lowering hallucinations with structured outputs
The structured output function of Strands Brokers makes use of Pydantic fashions to rework historically unpredictable LLM outputs into dependable, type-safe responses. This method addresses a elementary problem in generative AI: though LLMs excel at producing humanlike textual content, they will wrestle with constantly formatted outputs wanted for manufacturing techniques. By imposing schemas by way of Pydantic validation, we make it possible for responses conform to predefined constructions, enabling seamless integration with present check administration techniques.
The next pattern implementation demonstrates how structured outputs work in apply:
Pydantic routinely validates LLM responses in opposition to outlined schemas to facilitate sort correctness and required subject presence. When responses don’t match the anticipated construction, validation errors present clear suggestions about what wants correction, serving to stop malformed information from propagating by way of the system. In our surroundings, this method delivered constant, predictable outputs throughout the brokers no matter immediate variations or mannequin updates, minimizing a whole class of knowledge formatting errors. Because of this, our improvement crew labored extra effectively with full IDE assist.
Workflow orchestration advantages
The Strands Brokers workflow structure offered the delicate coordination capabilities our multi-agent system required. The framework enabled structured coordination with specific process definitions, computerized parallel execution for impartial duties, and sequential processing for dependent operations. This meant we may construct advanced agent-to-agent communication patterns that might have been tough to implement manually.
The next pattern snippet exhibits how you can create a workflow in Strands Brokers SDK:
The workflow system delivered three crucial capabilities for our use case. First, parallel processing optimization allowed journey evaluation, situation identification, and protection evaluation to run concurrently, with impartial brokers processing totally different elements with out blocking one another. The system routinely allotted assets primarily based on availability, maximizing throughput.
Second, clever dependency administration made certain that check improvement waited for situation identification to be accomplished, and group duties trusted the check circumstances being generated. Context was preserved and handed effectively between dependent levels, sustaining info integrity all through the workflow.
Lastly, the built-in reliability options offered the resilience our system required. Computerized retry mechanisms dealt with transient failures gracefully, state persistence enabled pause and resume capabilities for long-running workflows, and complete audit logging supported each debugging and efficiency optimization efforts.
The next desk exhibits examples of enter into the workflow and the potential outputs.
| Enter: Enterprise requirement doc | Output: Check circumstances generated |
Purposeful necessities:
|
TC006: Bank card fee success Situation: Buyer completes buy utilizing legitimate bank card Steps: 1. Add gadgets to cart and proceed to checkout. Anticipated outcome: Checkout type displayed. 2. Enter delivery info. Anticipated outcome: Transport particulars saved. 3. Choose bank card fee technique. Anticipated outcome: Card type proven. 4. Enter legitimate card particulars. Anticipated outcome: Card validated. 5. Submit fee. Anticipated outcome: Cost processed, order confirmed.TC008: Cost failure dealing with Situation: Cost fails on account of inadequate funds or card decline Steps: 1. Enter card with inadequate funds. Anticipated outcome: Cost declined message. 2. System gives retry possibility. Anticipated outcome: Cost type redisplayed. 3. Attempt various fee technique. Anticipated outcome: Different fee profitable. TC009: Cost gateway timeout TC010: Refund processing |
Integration with Amazon Bedrock
Amazon Bedrock served as the muse for our AI capabilities, offering seamless entry to Claude Sonnet by Anthropic by way of the Strands Brokers built-in AWS service integration. We chosen Claude Sonnet by Anthropic for its distinctive reasoning capabilities and talent to grasp advanced fee area necessities. The Strands Brokers versatile LLM API integration made this implementation easy. The next snippet exhibits how you can effortlessly create an agent in Strands Brokers:
The managed service structure of Amazon Bedrock diminished infrastructure complexity from our deployment. The service offered computerized scaling that adjusted to our workload calls for, facilitating constant efficiency throughout the brokers no matter visitors patterns. Constructed-in retry logic and error dealing with improved system reliability considerably, lowering the operational overhead sometimes related to managing AI infrastructure at scale. The mixture of the delicate orchestration capabilities of Strands Brokers and the sturdy infrastructure of Amazon Bedrock created a production-ready system that would deal with advanced check era workflows whereas sustaining excessive reliability and efficiency requirements.
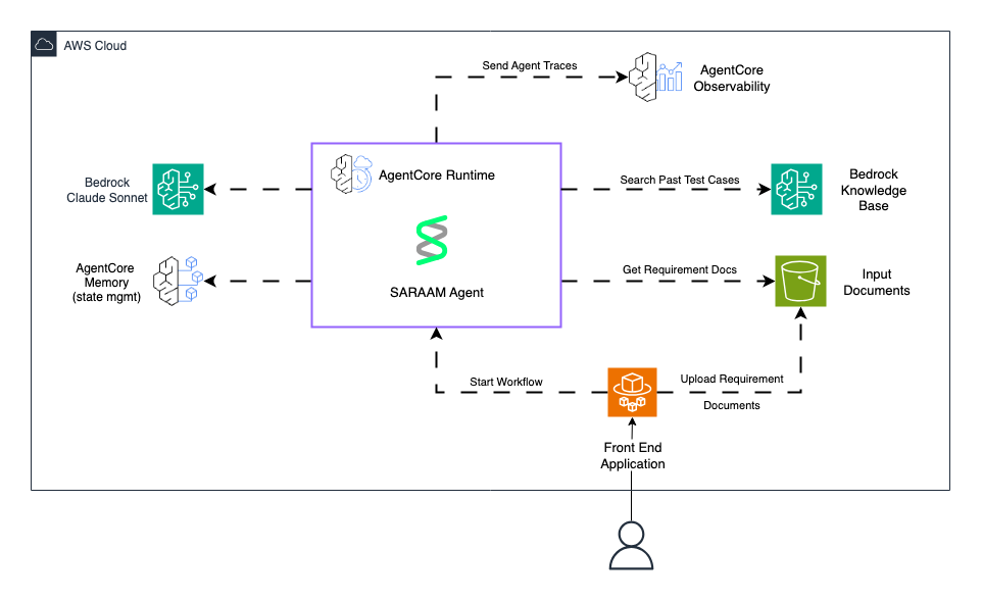
The next diagram exhibits the deployment of the SARAAM agent with Amazon Bedrock AgentCore and Amazon Bedrock.
Outcomes and enterprise affect
The implementation of SAARAM has improved our QA processes with measurable enhancements throughout a number of dimensions. Earlier than SAARAM, our QA engineers spent 3–5 days manually analyzing BRD paperwork and UI mocks to create complete check circumstances. This handbook course of is now diminished to hours, with the system reaching:
- Check case era time: Potential diminished from 1 week to hours
- Useful resource optimization: QA effort decreased from 1.0 full-time worker (FTE) to 0.2 FTE for validation
- Protection enchancment: 40% extra edge circumstances recognized in comparison with handbook course of
- Consistency: 100% adherence to check case requirements and codecs
The accelerated check case era has pushed enhancements in our core enterprise metrics:
- Cost success fee: Elevated by way of complete edge case testing and risk-based check prioritization
- Cost expertise: Enhanced buyer satisfaction as a result of groups can now iterate on check protection through the design section
- Developer velocity: Product and improvement groups generate preliminary check circumstances throughout design, enabling early high quality suggestions
SAARAM captures and preserves institutional information that was beforehand depending on particular person QA engineers:
- Testing patterns from skilled professionals are actually codified
- Historic check case learnings are routinely utilized to new options
- Constant testing approaches throughout totally different fee strategies and industries
- Decreased onboarding time for brand spanking new QA crew members
This iterative enchancment implies that the system turns into extra precious over time.
Classes discovered
Our journey growing SAARAM offered essential insights for constructing production-ready AI techniques. Our breakthrough got here from learning how area consultants suppose fairly than optimizing how AI processes info. Understanding the cognitive patterns of testers and QA professionals led to an structure that naturally aligns with human reasoning. This method produced higher outcomes in comparison with purely technical optimizations. Organizations constructing comparable techniques ought to make investments time observing and interviewing area consultants earlier than designing their AI structure—the insights gained straight translate to more practical agent design.
Breaking advanced duties into specialised brokers dramatically improved each accuracy and reliability. Our multi-agent structure, enabled by the orchestration capabilities of Strands Brokers, handles nuances that monolithic approaches constantly miss. Every agent’s targeted accountability permits deeper area experience whereas offering higher error isolation and debugging capabilities.
A key discovery was that the Strands Brokers workflow and graph-based orchestration patterns considerably outperformed conventional supervisor agent approaches. Though supervisor brokers make dynamic routing selections that may introduce variability, workflows present “brokers on rails”—a structured path facilitating constant, reproducible outcomes. Strands Brokers gives a number of patterns, together with supervisor-based routing, workflow orchestration for sequential processing with dependencies, and graph-based coordination for advanced eventualities. For check era the place consistency is paramount, the workflow sample with its specific process dependencies and parallel execution capabilities delivered the optimum stability of flexibility and management. This structured method aligns completely with manufacturing environments the place reliability issues greater than theoretical flexibility.
Implementing Pydantic fashions by way of the Strands Brokers structured output function successfully diminished type-related hallucinations in our system. By imposing AI responses to adapt to strict schemas, we facilitate dependable, programmatically usable outputs. This method has confirmed important when consistency and reliability are nonnegotiable. The kind-safe responses and computerized validation have turn out to be foundational to our system’s reliability.
Our condensed info generator sample demonstrates how clever context administration maintains high quality all through multistage processing. This method of figuring out what to protect, condense, and go between brokers helps stop the context degradation that sometimes happens in token-limited environments. The sample is broadly relevant to multistage AI techniques going through comparable constraints.
What’s subsequent
The modular structure we’ve constructed with Strands Brokers permits easy adaptation to different domains inside Amazon. The identical patterns that generate fee check circumstances could be utilized to retail techniques testing, customer support situation era for assist workflows, and cellular software UI and UX check case era. Every adaptation requires solely domain-specific prompts and schemas whereas reusing the core orchestration logic. All through the event of SAARAM, the crew efficiently addressed many challenges in check case era—from lowering hallucinations by way of structured outputs to implementing subtle multi-agent workflows. Nevertheless, one crucial hole stays: the system hasn’t but been supplied with examples of what high-quality check circumstances truly seem like in apply.
To bridge this hole, integrating Amazon Bedrock Information Bases with a curated repository of historic check circumstances would offer SAARAM with concrete, real-world examples through the era course of. By utilizing the combination capabilities of Strands Brokers with Amazon Bedrock Information Bases, the system may search by way of previous profitable check circumstances to search out comparable eventualities earlier than producing new ones. When processing a BRD for a brand new fee function, SAARAM would first question the information base for comparable check circumstances—whether or not for comparable fee strategies, buyer segments, or transaction flows—and use these as contextual examples to information its output.
Future deployment will use Amazon Bedrock AgentCore for complete agent lifecycle administration. Amazon Bedrock AgentCore Runtime offers the manufacturing execution atmosphere with ephemeral, session-specific state administration that maintains conversational context throughout lively classes whereas facilitating isolation between totally different consumer interactions. The observability capabilities of Bedrock AgentCore assist ship detailed visualizations of every step in SAARAM’s multi-agent workflow, which the crew can use to hint execution paths by way of the 5 brokers, audit intermediate outputs from the Information Condenser and Check Generator brokers, and determine efficiency bottlenecks by way of real-time dashboards powered by Amazon CloudWatch with standardized OpenTelemetry-compatible telemetry.
The service permits a number of superior capabilities important for manufacturing deployment: centralized agent administration and versioning by way of the Amazon Bedrock AgentCore management aircraft, A/B testing of various workflow methods and immediate variations throughout the 5 subagents inside the Check Generator, efficiency monitoring with metrics monitoring token utilization and latency throughout the parallel execution phases, automated agent updates with out disrupting lively check era workflows, and session persistence for sustaining context when QA engineers iteratively refine check suite outputs. This integration positions SAARAM for enterprise-scale deployment whereas offering the operational visibility and reliability controls that rework it from a proof of idea right into a manufacturing system able to dealing with the AMET crew’s bold purpose of increasing past Funds QA to serve the broader group.
Conclusion
SAARAM demonstrates how AI can change conventional QA processes when designed with human experience at its core. By lowering check case creation from 1 week to hours whereas bettering high quality and protection, we’ve enabled quicker function deployment and enhanced fee experiences for hundreds of thousands of shoppers throughout the MENA area. The important thing to our success wasn’t merely superior AI expertise—it was the mixture of human experience, considerate structure design, and sturdy engineering practices. By means of cautious research of how skilled QA professionals suppose, implementation of multi-agent techniques that mirror these cognitive patterns, and minimization of AI limitations by way of structured outputs and context engineering, we’ve created a system that enhances fairly than replaces human experience.
For groups contemplating comparable initiatives, our expertise emphasizes three crucial success components: make investments time understanding the cognitive processes of area consultants, implement structured outputs to attenuate hallucinations, and design multi-agent architectures that mirror human problem-solving approaches. These QA instruments aren’t supposed to interchange human testers, they amplify their experience by way of clever automation. For those who’re taken with beginning your journey on brokers with AWS, take a look at our pattern Strands Brokers implementations repo or our latest launch, Amazon Bedrock AgentCore, and the end-to-end examples with deployment on our Amazon Bedrock AgentCore samples repo.
Concerning the authors
 Jayashree is a High quality Assurance Engineer at Amazon Music Tech, the place she combines rigorous handbook testing experience with an rising ardour for GenAI-powered automation. Her work focuses on sustaining excessive system high quality requirements whereas exploring modern approaches to make testing extra clever and environment friendly. Dedicated to lowering testing monotony and enhancing product high quality throughout Amazon’s ecosystem, Jayashree is on the forefront of integrating synthetic intelligence into high quality assurance practices.
Jayashree is a High quality Assurance Engineer at Amazon Music Tech, the place she combines rigorous handbook testing experience with an rising ardour for GenAI-powered automation. Her work focuses on sustaining excessive system high quality requirements whereas exploring modern approaches to make testing extra clever and environment friendly. Dedicated to lowering testing monotony and enhancing product high quality throughout Amazon’s ecosystem, Jayashree is on the forefront of integrating synthetic intelligence into high quality assurance practices.
 Harsha Pradha G is a Snr. High quality Assurance Engineer half in MENA Funds at Amazon. With a powerful basis in constructing complete high quality methods, she brings a novel perspective to the intersection of QA and AI as an rising QA-AI integrator. Her work focuses on bridging the hole between conventional testing methodologies and cutting-edge AI improvements, whereas additionally serving as an AI content material strategist and AI Writer.
Harsha Pradha G is a Snr. High quality Assurance Engineer half in MENA Funds at Amazon. With a powerful basis in constructing complete high quality methods, she brings a novel perspective to the intersection of QA and AI as an rising QA-AI integrator. Her work focuses on bridging the hole between conventional testing methodologies and cutting-edge AI improvements, whereas additionally serving as an AI content material strategist and AI Writer.
 Fahim Surani is Senior Options Architect as AWS, serving to clients throughout Monetary Companies, Vitality, and Telecommunications design and construct cloud and generative AI options. His focus since 2022 has been driving enterprise cloud adoption, spanning cloud migrations, price optimization, event-driven architectures, together with main implementations acknowledged as early adopters of Amazon’s newest AI capabilities. Fahim’s work covers a variety of use circumstances, with a major curiosity in generative AI, agentic architectures. He’s a daily speaker at AWS summits and trade occasions throughout the area.
Fahim Surani is Senior Options Architect as AWS, serving to clients throughout Monetary Companies, Vitality, and Telecommunications design and construct cloud and generative AI options. His focus since 2022 has been driving enterprise cloud adoption, spanning cloud migrations, price optimization, event-driven architectures, together with main implementations acknowledged as early adopters of Amazon’s newest AI capabilities. Fahim’s work covers a variety of use circumstances, with a major curiosity in generative AI, agentic architectures. He’s a daily speaker at AWS summits and trade occasions throughout the area.