
![How Does LLM Reminiscence Work? [Explained in 2 Minutes]](https://cdn.analyticsvidhya.com/wp-content/uploads/2026/01/LLM.webp "How Does LLM Reminiscence Work? [Explained in 2 Minutes]")
{kind=link}
LLMs like ChatGPT, Claude, and Gemini, are sometimes thought of clever as a result of they appear to recall previous conversations. The mannequin acts as if it bought the purpose, even after you made a follow-up query. That is the place LLM reminiscence turns out to be useful. It permits a chatbot to return to the purpose of what “it” or “that” means. Most LLMs are stateless by default. Due to this fact, every new consumer question is handled independently, with no information of previous exchanges.
Nonetheless, LLM reminiscence works very in a different way from human reminiscence. This reminiscence phantasm is among the fundamental components that decide how fashionable AI programs are perceived as being helpful in real-world functions. The fashions don’t “recall” within the typical means. As an alternative, they use architectural mechanisms, context home windows, and exterior reminiscence programs. On this weblog, we are going to focus on how LLM reminiscence capabilities, the assorted kinds of reminiscence which can be concerned, and the way present programs assist fashions in remembering what is absolutely essential.
What’s Reminiscence in LLMs?
Reminiscence in LLMs is an idea that allows LLMs to make use of earlier info as a foundation for creating new responses. Primarily, the time period “established reminiscence” defines how constructed reminiscences work inside LLMs, in comparison with established reminiscence in people, the place established reminiscence is used instead of established reminiscence as a system of storing and/ or recalling experiences.
As well as, the established reminiscence idea provides to the general functionality of LLMs to detect and higher perceive the context, the connection between previous exchanges and present enter tokens, in addition to the applying of not too long ago discovered patterns to new circumstances by means of an integration of enter tokens into established reminiscence.
Since established reminiscence is continually developed and utilized primarily based on what was discovered throughout prior interactions, info derived from established reminiscence allows a considerably extra complete understanding of context, earlier message exchanges, and new requests in comparison with the normal use of LLMs to reply to requests in the identical means as with present LLM strategies of operation.
What Does Reminiscence Imply in LLMs?
The big language mannequin (LLM) reminiscence allows using prior information in reasoning. The information could also be related to the present immediate. Previous dialog although is pulled from exterior information sources. Reminiscence doesn’t suggest that the mannequin has continuous consciousness of all the knowledge. Reasonably, it’s the mannequin that produces its output primarily based on the offered context. Builders are consistently pouring within the related info into every mannequin name, thus creating reminiscence.
Key Factors:
- The LLM reminiscence characteristic permits for retaining outdated textual content and using it in new textual content technology.
- The reminiscence can final for a short while (just for the continuing dialog) or a very long time (enter throughout consumer classes), as we are going to present all through the textual content.
- To people, it might be like evaluating the short-term and long-term reminiscence in our brains.
Reminiscence vs. Stateless Era
In an ordinary state of affairs, an LLM doesn’t retain any info between calls. For example, “every incoming question is processed independently” if there aren’t any express reminiscence mechanisms in place. This means that in answering the query “Who received the sport?” an LLM wouldn’t think about that “the sport” was beforehand referred to. The mannequin would require you to repeat all essential info each single time. Such a stateless character is commonly appropriate for single duties, nevertheless it will get problematic for conversations or multi-step duties.
In distinction, reminiscence programs permit for this example to be reversed. The inclusion of conversational reminiscence implies that the LLM’s inputs encompass the historical past of earlier conversations, which is often condensed or shortened to suit the context window. Consequently, the mannequin’s reply can depend on the earlier exchanges.
Core Elements of LLM Reminiscence
The reminiscence of LLM operates by means of the collaboration of varied layers. The mannequin that’s shaped by these components units the boundaries of the knowledge a mannequin can think about, the time it lasts, and the extent to which it influences the ultimate outcomes with certainty. The information of such elements empowers the engineers to create programs which can be scalable and keep the identical degree of significance.
Context Window: The Working Reminiscence of LLMs
The context window defines what number of tokens an LLM can course of without delay. It acts because the mannequin’s short-term working reminiscence.
Every thing contained in the context window influences the mannequin’s response. As soon as tokens fall exterior this window, the mannequin loses entry to them solely.
Challenges with Massive Context Home windows
Longer context home windows enrich reminiscence capability however pose a sure problem. They increase the bills for computation, trigger a delay, and in some circumstances, scale back the standard of the eye paid. The fashions might not be capable of successfully discriminate between salient and non-salient with the rise within the context size.
For instance, if an 8000-token context window mannequin is used, then it will likely be in a position to perceive solely the newest 8000 tokens out of the dialogue, paperwork, or directions mixed. Every thing that goes past this should be both shortened or discarded. The context window contains all that you just transmit to the mannequin: system prompts, all the historical past of the dialog, and any related paperwork. With a much bigger context window, extra fascinating and sophisticated conversations can happen.
Parametric vs Non-Parametric Reminiscence in LLMs
Once we say reminiscence in LLM, it may be considered by way of the place it’s saved. We make a distinction between two sorts of reminiscence: parametric and non-parametric. Now we’ll focus on it briefly.
- Parametric reminiscence means the information that was saved within the mannequin weights throughout the coaching part. This may very well be a mix of varied issues, similar to language patterns, world information, and the power to purpose. That is how a GPT mannequin might have labored with historic details as much as its coaching cutoff date as a result of they’re saved within the parametric reminiscence.
- Non-parametric reminiscence is maintained exterior of the mannequin. It consists of databases, paperwork, embeddings, and dialog historical past which can be all added on-the-fly. Non-parametric reminiscence is what fashionable LLM programs closely depend upon to supply each accuracy and freshness. For instance, a information base in a vector database is non-parametric. As it may be added to or corrected at any time limit, the mannequin can nonetheless entry info from it throughout the inference course of.
Varieties of LLM Reminiscence
LLM reminiscence is a time period used to confer with the identical idea, however in several methods. The commonest technique to inform them aside is by the short-term (contextual) reminiscence and the long-term (persistent) reminiscence. The opposite perspective takes phrases from cognitive psychology: semantic reminiscence (information and details), episodic reminiscence (occasions), and procedural reminiscence (performing). We are going to describe every one.
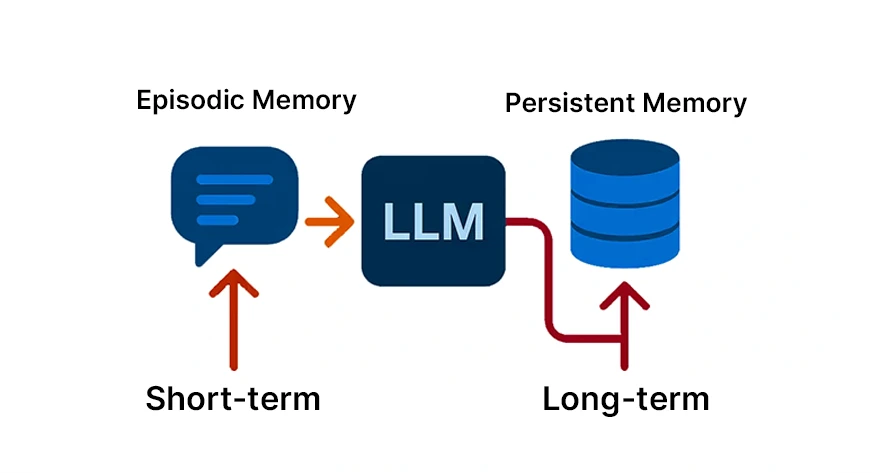
Contextual Reminiscence or Brief-Time period Reminiscence
Brief-term reminiscence, also referred to as contextual, is the reminiscence that comprises the knowledge that’s presently being talked about. It’s the digital counterpart of your short-term recall. One of these reminiscence is often stored within the current context window or a dialog buffer.
Key Factors:
- The current questions of the consumer and the solutions of the mannequin are saved in reminiscence throughout the session. There is no such thing as a long-lasting reminiscence. Usually, this reminiscence is eliminated after the dialog, until it’s saved.
- It is vitally quick and doesn’t eat a lot reminiscence. It doesn’t want a database or sophisticated infrastructure. It’s merely the tokens within the present immediate.
- It will increase coherence, i.e., the mannequin “understands” what was not too long ago mentioned and may precisely confer with it utilizing phrases similar to “he” or “the earlier instance”.
For example, a assist chatbot might keep in mind that the client had earlier inquired a few defective widget, after which, inside the similar dialog, it might ask the client if he had tried rebooting the widget. That’s short-term reminiscence going into motion.

Persistent Reminiscence or Lengthy-Time period Reminiscence
Persistent reminiscence is a characteristic that persistently exists in fashionable computing programs and historically retains info by means of numerous consumer classes. Among the many various kinds of system retains are consumer preferences, software information, and former interactions. As a matter of truth, builders should depend on exterior sources like databases, caches, or vector shops for a brief answer, as fashions should not have the power to retailer these internally, thus, long-term reminiscence simulation.
For example, an AI writing assistant that might overlook that your most popular tone is “formal and concise” or which initiatives you wrote about final week. While you return the following day, the assistant nonetheless remembers your preferences. To implement such a characteristic, builders often undertake the next measures:
- Embedding shops or vector databases: They hold paperwork or details within the type of high-dimensional vectors. The big language mannequin (LLM) is able to conducting a semantic search on these vectors to acquire reminiscences which can be related.
- Positive-tuned fashions or reminiscence weights: In sure setups, the mannequin is periodically fine-tuned or up to date to encode the brand new info offered by the consumer long-term. That is akin to embedding reminiscence into the weights.
- Exterior databases and APIs: Structured information (like consumer profiles) is saved in a database and fetched as wanted.

Vector Databases & Retrieval-Augmented Era (RAG)
A serious technique for executing long-term reminiscence is vector databases together with retrieval-augmented technology (RAG). RAG is a way that locations the technology part of the LLM together with the retrieval part, dynamically combining them in an LLM method.
In a RAG system, when the consumer submits a question, the system first makes use of the retriever to scan an exterior information retailer, often a vector database, for pertinent information. The retriever identifies the closest entries to the question and fetches these corresponding textual content segments. The subsequent step is to insert these retrieved segments into the context window of the LLM as supplementary context. The LLM supplies the reply primarily based on the consumer’s enter in addition to the retrieved information. RAG gives important benefits:
- Grounded solutions: It combats hallucination by counting on precise paperwork for solutions.
- Up-to-date information: It grants the mannequin entry to contemporary info or proprietary information with out going by means of all the retraining course of.
- Scalability: The mannequin just isn’t required to carry every little thing in reminiscence without delay; it retrieves solely what is important.
For instance, allow us to take an AI that summarizes analysis papers. RAG might allow it to get related educational papers, which might then be fed to the LLM. This hybrid system merges transitional reminiscence with lasting reminiscence, yielding tremendously highly effective outcomes.

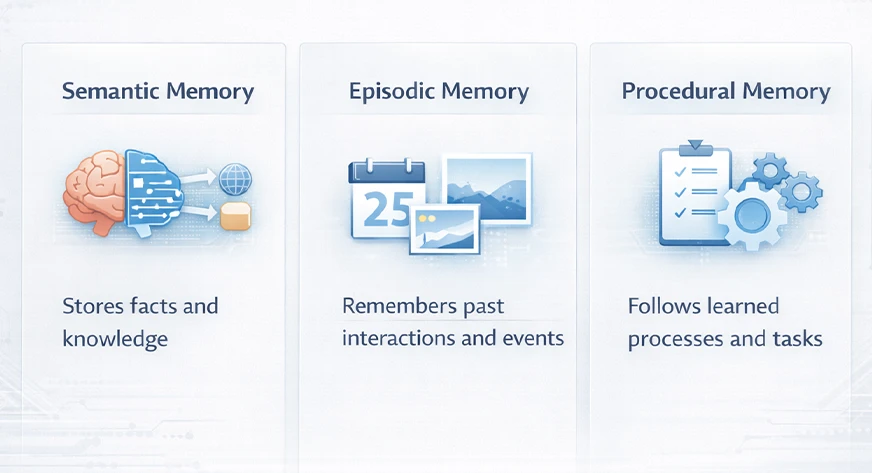
Episodic, Semantic & Procedural Reminiscence in LLMs
Cognitive science phrases are often utilized by researchers to characterize LLM reminiscence. They often categorize reminiscence into three varieties: semantic, episodic, and procedural reminiscence:
- Semantic Reminiscence: This represents the stock or storage of details and common information pertaining to the mannequin. One sensible facet of that is that it contains exterior information bases or doc shops. The LLM might have gained in depth information throughout the coaching part. Nonetheless, the newest or most detailed details are in databases.
- Episodic Reminiscence: It contains particular person occasions or dialogue historical past. An LLM makes use of its episodic reminiscence to maintain monitor of what simply befell in a dialog. This reminiscence supplies the reply to inquiries like “What was spoken earlier on this session?”
- Procedural Reminiscence: That is the algorithm the mannequin has acquired on the right way to act. Within the case of LLM, procedural reminiscence comprises the system immediate and the foundations or heuristics that the mannequin is given. For instance, instructing the mannequin to “All the time reply in bullet factors” or “Be formal” is equal to setting the procedural reminiscence.
How LLM Reminiscence Works in Actual Programs
In growing an LLM system with reminiscence capabilities, the builders incorporate the context and the exterior storage within the mannequin’s structure in addition to within the immediate design.
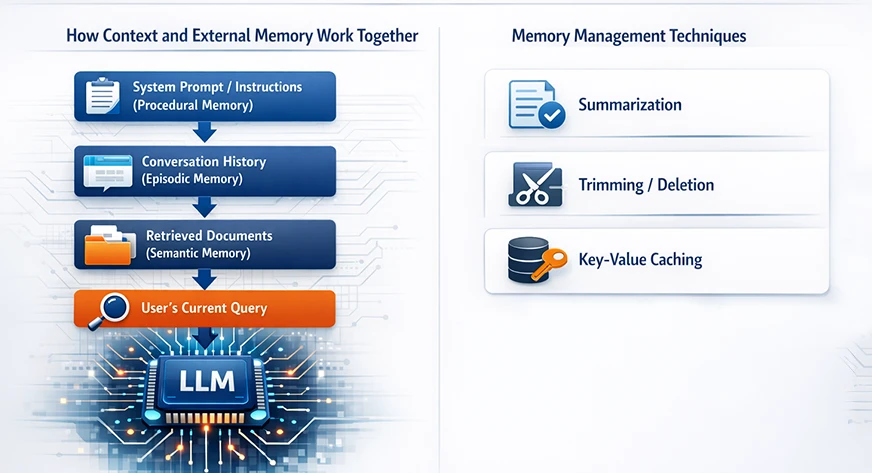
How Context and Exterior Reminiscence Work Collectively
The reminiscence of huge language fashions just isn’t thought to be a unitary component. Reasonably, it outcomes from the mixed interactivity of consideration, embeddings, and exterior retrieval programs. Usually, it comprises:
- A system immediate or directions (a part of procedural reminiscence).
- The dialog historical past (contextual/episodic reminiscence).
- Any retrieved exterior paperwork (semantic/persistent reminiscence).
- The consumer’s present question.
All this info is then merged into one immediate that’s inside the context window.
Reminiscence Administration Strategies
The mannequin could be simply defeated by uncooked reminiscence, even when the structure is sweet. Engineers make use of numerous strategies to regulate the reminiscence in order that the mannequin stays environment friendly:
- Summarization: As an alternative of maintaining complete transcripts of prolonged discussions, the system can do a abstract of the sooner components of the dialog at common intervals.
- Trimming/Deletion: Essentially the most primary strategy is to do away with messages which can be outdated or not related. For example, while you exceed the preliminary 100 messages in a chat, you possibly can do away with the oldest ones if they’re now not wanted. Hierarchical Group: Reminiscence could be organized by subject or time. For instance, the older conversations could be categorized by subject after which stored as a narrative, whereas the brand new ones are stored verbatim.
- Key-Worth Caching: On the mannequin’s facet, Transformers apply a way named KV (key-value) caching. KV caching doesn’t improve the mannequin’s information, nevertheless it makes the lengthy context sequence technology quicker by reusing earlier computations.
Challenges & Limitations of LLM Reminiscence
The addition of reminiscence to massive language fashions is a major benefit, nevertheless it additionally comes with a set of recent difficulties. Among the many high issues are the price of computation, hallucinations, and privateness points.
Computational Bottlenecks & Prices
Reminiscence is each extremely efficient and really pricey. Each the lengthy context home windows and reminiscence retrieval are the primary causes for requiring extra computation. To offer a tough instance, doubling the context size roughly quadruples the computation for the eye layers of the Transformer. In actuality, each further token or reminiscence lookup makes use of each GPU and CPU energy.
Hallucination & Context Misalignment
One other problem is the hallucination. This example arises when the LLM offers out unsuitable info that’s nonetheless convincing. For example, if the exterior information base has outdated and outdated information, the LLM might current an outdated truth as if it have been new. Or, if the retrieval step fetches a doc that’s solely loosely associated to the subject, the mannequin might find yourself deciphering it into a solution that’s solely totally different.
Privateness & Moral Concerns
Retaining dialog historical past and private information creates critical issues relating to privateness. If an LLM retains consumer preferences or details about the consumer that’s of a private or delicate nature, then such information should be handled with the best degree of safety. Truly, the designers must comply with the rules (similar to GDPR) and the practices which can be thought of finest within the business. Which means they must get the consumer’s consent for reminiscence, holding the minimal attainable information, and ensuring that one consumer’s reminiscences are by no means combined with one other’s.

Additionally Learn: What’s Mannequin Collapse? Examples, Causes and Fixes
Conclusion
LLM reminiscence isn’t just one characteristic however slightly a classy system that has been designed with nice care. It mimics good recall by merging context home windows, exterior retrieval, and architectural design selections. The fashions nonetheless keep their primary core of being stateless, however the present reminiscence programs give them an impression of being persistent, contextual, and adaptive.
With the developments in analysis, LLM reminiscence will more and more turn into extra human-like in its effectivity, selectivity, and reminiscence traits. A deep comprehension of the working of those programs will allow the builders to create AI functions that may be capable of keep in mind what’s essential, with out the drawbacks of precision, price, or belief.
Continuously Requested Questions
A. LLMs don’t keep in mind previous conversations by default. They’re stateless programs that generate responses solely from the knowledge included within the present immediate. Any obvious reminiscence comes from dialog historical past or exterior information that builders explicitly go to the mannequin.
A. LLM reminiscence refers back to the methods used to supply massive language fashions with related previous info. This contains context home windows, dialog historical past, summaries, vector databases, and retrieval programs that assist fashions generate coherent and context-aware responses.
A. A context window defines what number of tokens an LLM can course of without delay. Reminiscence is broader and contains how previous info is saved, retrieved, summarized, and injected into the context window throughout every mannequin name.
A. Retrieval-Augmented Era (RAG) improves LLM reminiscence by retrieving related paperwork from an exterior information base and including them to the immediate. This helps scale back hallucinations and permits fashions to make use of up-to-date or personal info with out retraining.
A. Most LLMs are stateless by design. Every request is processed independently until exterior reminiscence programs are used. Statefulness is simulated by storing and re-injecting dialog historical past or retrieved information with each request.
Hiya! I am Vipin, a passionate information science and machine studying fanatic with a robust basis in information evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy information, and fixing real-world issues. My purpose is to use data-driven insights to create sensible options that drive outcomes. I am desirous to contribute my abilities in a collaborative atmosphere whereas persevering with to be taught and develop within the fields of Knowledge Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.