

{kind=link}
- February 24, 2014
- Vasilis Vryniotis
- . 3 Feedback
Information Envelopment Evaluation, also referred to as DEA, is a non-parametric technique for performing frontier evaluation. It makes use of linear programming to estimate the effectivity of a number of decision-making models and it’s generally utilized in manufacturing, administration and economics. The approach was first proposed by Charnes, Cooper and Rhodes in 1978 and since then it grew to become a invaluable instrument for estimating manufacturing frontiers.
Replace: The Datumbox Machine Studying Framework is now open-source and free to obtain. Try the bundle com.datumbox.framework.algorithms.dea to see the implementation of Information Envelopment Evaluation in Java.
Once I first encountered the tactic 5-6 years in the past, I used to be amazed by the originality of the algorithm, its simplicity and the cleverness of the concepts that it used. I used to be much more amazed to see that the approach labored properly outdoors of its typical functions (monetary, operation analysis and so forth) because it may very well be efficiently utilized in On-line Advertising and marketing, Search Engine Rating and for creating composite metrics. Regardless of this, at the moment DEA is sort of completely mentioned throughout the context of enterprise. That’s the reason, on this article, I’ll cowl the fundamental concepts and mathematical framework behind DEA and within the subsequent submit I’ll present you some novel functions of the algorithm on internet functions.
Why Information Envelopment Evaluation is attention-grabbing?
Information Envelopment Evaluation is a technique that allows us evaluate and rank information (shops, workers, factories, webpages, advertising campaigns and so forth) based mostly on their options (weight, measurement, value, revenues and different metrics or KPIs) with out making any prior assumptions concerning the significance or weights of the options. Essentially the most attention-grabbing a part of this method is that it permits us to check information comprised of a number of options which have completely completely different models of measurement. Which means we are able to have information with options measured in kilometers, kilograms or financial models and nonetheless be capable to evaluate, rank them and discover the very best/worst and common performing information. Sounds attention-grabbing? Maintain studying.
The outline and assumptions of Information Envelopment Evaluation
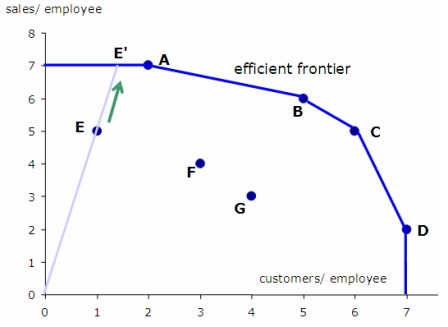
As we mentioned earlier, DEA is a technique which was invented to measure productiveness in enterprise. Thus a number of of its concepts come from the best way that productiveness is measured on this context. One of many core traits of the tactic is the separation of the file options into two classes: enter and output. For instance if we measure the effectivity of a automotive, let’s imagine that the enter is the liters of petrol and the output is the variety of kilometers that it travels.
In DEA, all options have to be optimistic and it’s assumed that the upper their worth, the extra their enter/output is. Moreover Information Envelopment Evaluation assumes that the options may be mixed linearly as a weighted sum of non-negative weights and kind a ratio between enter and output that can measure the effectivity of every file. For a file to be environment friendly it should give us a “good” output relative to the offered enter. The effectivity is measured by the ratio between output and enter after which in comparison with the ratio of the opposite information.
The ingenious thought behind DEA
What we coated to this point is a standard sense/apply. We use enter and outputs, weighted sums and ratios to rank our information. The intelligent thought of DEA is in the best way that the weights of the options are calculated. As an alternative of getting to set the weights of the options and deciding on their significance earlier than we run the evaluation, the Information Envelopment Evaluation calculates them from the info. Furthermore the weights are NOT the identical for each file!
Right here is how DEA selects the weights: We attempt to maximize the ratio of each file by choosing the suitable function weights; on the identical time although we should be certain that if we use the identical weights to calculate the ratios of all the opposite information, none of them will turn into bigger than 1.
The concept sounds a bit unusual at the start. Gained’t this result in the calculation of otherwise weighted ratios? The reply is sure. Doesn’t this imply that we really calculate otherwise the ratios for each file? The reply is once more sure. So how does this work? The reply is straightforward: For each file, given its traits we attempt to discover the “excellent state of affairs” (weights) through which its ratio could be as excessive as attainable and thus making it as efficient as attainable. BUT on the identical time, given this “excellent state of affairs” not one of the output/enter ratios of the opposite information must be bigger than 1, which means that they’ll’t be simpler than 100%! As soon as we calculate the ratios of all information beneath every “excellent state of affairs”, we use their ratios to rank them.
So the primary thought of DEA may be summed within the following: “Discover the best state of affairs through which we are able to obtain the very best ratio rating based mostly on the traits of every file. Then calculate this excellent ratio of every file and use it to check their effectiveness”.
Let’s see an instance
Let’s see an instance the place we may use DEA.
Suppose that we’re concerned about evaluating the effectivity of the grocery store shops of a selected chain based mostly on quite a lot of traits: the whole variety of workers, the dimensions of retailer in sq. meters, the quantity of gross sales that they generate and the variety of prospects that they serve each month on common. It turns into apparent that discovering probably the most environment friendly shops requires us to check information with a number of options.
To use DEA we should outline which is our enter and output. On this case the output is clearly the quantity of gross sales and the variety of prospects that they serve. The enter is the variety of workers and the dimensions of the shop. If we run DEA, we are going to estimate the output to enter ratio for each retailer beneath the best weights (as mentioned above). As soon as we’ve got their ratios we are going to rank them in line with their effectivity.
It’s math time!
Now that we acquired an instinct of how DEA works, it’s time to dig into the maths.
The effectivity ratio of a selected file i with x enter and y output (each function vectors with optimistic values) is estimated through the use of the next components:
![]()
The place u and v are the weights of every output and enter of the file, s is the variety of output options and m is the variety of enter options.
The issue of discovering the very best/excellent weights for a selected file i may be formulated as follows:
![]()
![]()
![]()
Once more the above is simply the mathematical method of discovering the weights u and v that maximize the effectivity of file i, offered that these weights is not going to make any of the opposite information extra environment friendly than 100%.
To resolve this drawback we should use linear programming. Sadly linear programming doesn’t permit us to make use of fractions and thus we have to rework the formulation of the issue as following:
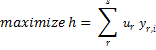
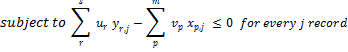
![]()
![]()
We should always stress that the above linear programming drawback will provides us the very best weights for file i and calculate its effectivity beneath these optimum weights. The identical have to be repeated for each file in our dataset. So if we’ve got n information, we’ve got to unravel n separate linear issues. Right here is the pseudocode of how DEA works:
ratio_scores = [];
for each file i {
i_ratio = get_maximum_effectiveness();
ratio_scores[i] = i_ratio;
}
Limitations of Information Envelopment Evaluation
DEA is a good approach however it has its limitations. You will need to perceive that DEA is sort of a black field. Because the weights which can be used within the effectiveness ratio of every file are completely different, making an attempt to clarify how and why every rating was calculated is pointless. Normally we concentrate on the rating of the information somewhat than on the precise values of the effectiveness scores. Additionally notice that the existence of extremums may cause the scores to have very low values.
Take note of that DEA makes use of linear combos of the options to estimate the ratios. Thus if combining them linearly shouldn’t be applicable in our utility, we should apply transformations on the options and make them attainable to be linearly mixed. One other disadvantage of this method is that we’ve got to unravel as many linear programming issues because the variety of information, one thing that requires lots of computational sources.
One other drawback that DEA faces is that it doesn’t work properly with excessive dimensional information. To make use of DEA the variety of dimensions d = m + s have to be vital decrease than the variety of observations. Operating DEA when d could be very shut or bigger than n doesn’t present helpful outcomes since almost certainly all of the information will probably be discovered to be optimum. Notice that as you add a brand new output variable (dimension), all of the information with most worth on this dimension will probably be discovered optimum.
Lastly we must always notice that within the common type of the algorithm, the weights of the options in DEA are estimated from the info and thus they don’t use any prior details about the significance of options that we’d have in our drawback (in fact it’s attainable to include this data as constrains in our linear drawback). Moreover the effectivity scores which can be calculated are literally the higher restrict effectivity ratios of every file since they’re calculated beneath “excellent conditions”. Which means DEA is usually a good answer when it isn’t attainable to make any assumptions concerning the significance of the options but when we do have any prior data or we are able to quantify their significance then utilizing different strategies is suggested.
Within the subsequent article, I’ll present you easy methods to develop an implementation of Information Envelopment Evaluation in JAVA and we are going to use the tactic to estimate the recognition of internet pages and articles in social media networks.
Should you just like the article, take a second to share it on Twitter or Fb. 🙂