

{kind=link}
This can be a visitor put up by Klaus Schaefers, Senior Software program Engineer at Reserving.com and Basak Eskili, Machine Studying Engineer at Reserving.com, in partnership with AWS.
As a worldwide chief within the on-line journey business, Reserving.com repeatedly works to enhance the journey expertise for its customers. Latency is a key consider attaining this—no one likes ready for his or her search outcomes to be returned.
Reserving.com generates a number of million real-time predictions per minute, supporting a wide range of algorithms, together with rating and fraud detection. Frequent to most algorithms is the necessity for ultra-low finish to finish latencies, usually lower than 100 milliseconds, to keep away from affecting the person expertise. To fulfill these calls for, Reserving.com developed an ultra-low latency characteristic platform, able to serving ML options with a p99.9 latency beneath 25 milliseconds at a scale of 200,000 requests per second.
On this put up, we share how Reserving.com designed a well-architected Amazon ElastiCache-based characteristic platform, attaining ultra-low latency and excessive throughput, to make sure the absolute best person expertise.
Amazon ElastiCache has lengthy been a dependable expertise inside Reserving.com, proving its worth throughout a wide range of use instances. Given its mixture of low latency, excessive throughput, and operational simplicity, Reserving.com selected to construct their characteristic retailer with ElastiCache at its core. The managed nature of ElastiCache means groups can give attention to improvement moderately than infrastructure, and its help for complicated knowledge varieties and aggressive pricing supplies flexibility and cost-effectiveness at scale.
Necessities
To fulfill the dimensions and efficiency expectations at Reserving.com, the characteristic retailer wanted to ship on a number of key necessities:
- Extremely-low latency – Latencies is a crucial side, as a result of it instantly impacts Reserving.com’s person expertise. We outlined our platform wanted to reply with a p99.9 client-side latency of lower than 25 ms.
- Excessive throughput – Workloads scale throughout peak hours, the place ML programs serve a number of million requests per minute. The characteristic retailer wanted to deal with roughly 10 million key lookups per second, whereas sustaining an ultra-low latency.
- Self-service – The characteristic retailer is utilized by many groups inside Reserving.com. To maintain the operational burden for the core group to a minimal, the inner purchasers had to have the ability to handle the characteristic retailer by themselves by way of a central git repository.
- Giant knowledge volumes – The dimensions of the datasets can attain as much as a number of TB of characteristic knowledge. The answer had to have the ability to scale cost-efficiently to particular use instances, with out sacrificing efficiency.
- Isolation of workloads – The characteristic retailer had to offer robust ranges of isolation for each use case if wanted to fulfill Service Stage Aims (SLOs) and enhance price transparency.
Resolution overview
The structure addresses scalability, latency, and suppleness. The principle parts of the system are an ingestion part and a serving part, which each work together with ElastiCache clusters. The next diagram depicts the primary parts.
A significant design determination was to delegate the characteristic computation to exterior programs, and focus the characteristic retailer on pace and scale. This implies, in apply, that programs corresponding to Snowflake, Apache Flink, or Apache Spark are used to compute the options. Snowflake is usually used when knowledge recency isn’t a significant concern, or options are seldom altering. When knowledge recency is vital, streaming primarily based options corresponding to Flink or Spark are used. As soon as a characteristic is computed, it’s revealed to Apache Kafka, from the place it’s consumed and ingested into ElastiCache through a devoted Java service.One other necessary attribute of the answer is that it spins up a cluster per use case to offer isolation. Every cluster is registered beneath an alias within the system. Every characteristic group is assigned to an ElastiCache cluster, so customers can separate workloads and tailor sources to particular use instances. This setup is managed by way of a centralized configuration, which maps characteristic teams on to their corresponding cluster aliases. The configuration is managed in a central Git repository, and modifications are pushed by way of steady integration and steady supply (CI/CD) duties into the manufacturing programs.The next diagram illustrates this setup.
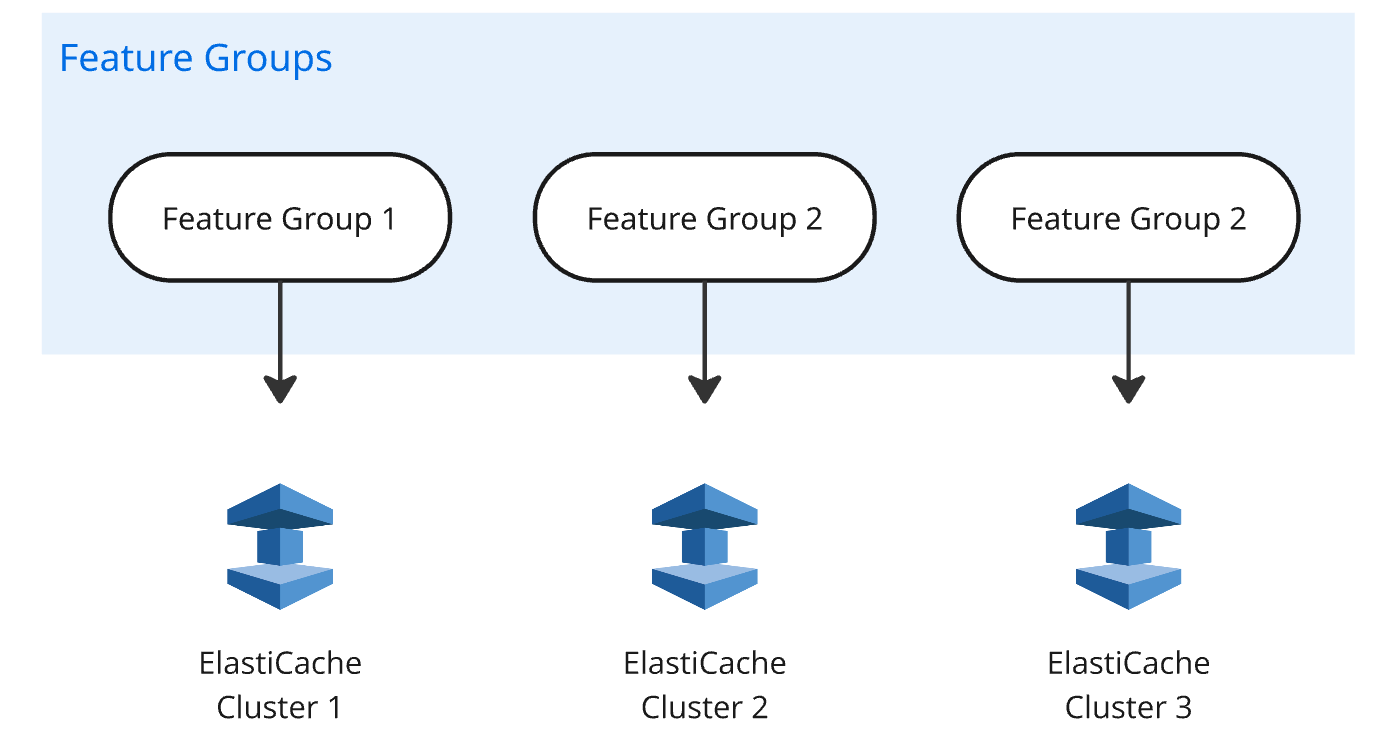
For characteristic teams which have larger storage necessities however don’t require ultra-low latency, ElastiCache with Knowledge Tiering is a superb choice. Right here, ElastiCache offloads a few of their knowledge to native SSD to offer ample capability whereas nonetheless sustaining affordable efficiency.
ElastiCache replication helps keep excessive availability and supply knowledge resiliency. This method helps safeguard in opposition to node failures by replicating knowledge throughout a number of cases. Moreover, learn replicas deal with excessive question volumes, so the answer can distribute the load and persistently ship low-latency responses even during times of heavy visitors.Within the following sections, we focus on the important thing parts of the answer in additional element.
Schema help
Within the characteristic retailer, knowledge is organized into characteristic teams. Every characteristic group accommodates a number of options, that are outlined by a schema. The information are saved in a characteristic group, and include the precise typed characteristic values. One characteristic should be the so-called record_id which specifies the important thing the report is saved beneath.
A characteristic group is specified by the next attributes:
- The title area defines the distinctive identifier for the characteristic group.
- The outline area supplies a human-readable abstract of the characteristic group’s function. This knowledge is mirrored in Reserving.com’s Central Machine Studying Registry so ML practitioners can reuse current characteristic teams.
- The storage_engine area specifies the backend storage, and storage_layout defines the info format.
- The schema part defines the options and is strongly impressed by JSON schema. The properties worth lists the options, together with its title, knowledge sort, and non-compulsory metadata (for instance, descriptions and examples).
- The record_id area is marked with is_record_identifier: true, figuring out it as the first key for every report.
- Extra options are described with their knowledge varieties and function.
- The kafka part specifies the supply of knowledge ingestion, together with the Kafka matter and federation accountable for publishing updates.
The schema-driven design supplies the next advantages:
- Knowledge integrity – Knowledge adheres to a predefined construction, stopping errors brought on by lacking or sudden fields
- Schema evolution – New options could be added to the schema with out requiring current knowledge to be backfilled
- Developer readability – The answer supplies a transparent contract between knowledge producers and customers, making it easy to onboard new groups or prolong current workflows
Storage structure
ElastiCache is, in precept, a key-value retailer. The Reserving.com group constructed storage structure parts as adapters to attach ElastiCache with the schema mannequin. Every storage structure implements completely different methods to serialize the information into singular values (byte arrays). Two major layouts have been chosen for the characteristic retailer: Key-JSON and Key-Kryo serialization:
- Key-JSON structure – Knowledge is saved as JSON objects, with all options of a report encapsulated in a single key. Every secret is constructed by combining the characteristic group and report ID, making it easy to retrieve or replace full information.
- Professionals – Helps nested buildings, permits partial updates, and integrates properly with schema-on-read approaches.
- Cons – Increased latency as a result of overhead of JSON serialization and deserialization. JSON payloads are bigger in comparison with serialized codecs.
The next represents a pattern key and its related (JSON) worth.:group_1.record_id_1 = { “feature1”: 1, “feature2”: 2, “feature3”: “abc”}
- Key-Kryo serialization structure – Knowledge is saved as serialized object arrays utilizing Kryo, compact and environment friendly serialization framework for the JVM. The order of the objects corresponds to a selected characteristic. This structure is optimized for performance-critical use instances requiring minimal latency.
- Professionals – Compact knowledge illustration considerably reduces reminiscence utilization and community switch occasions. It affords wonderful efficiency for batch queries.
- Cons – No help for partial updates instantly; your entire report should be learn, up to date, and written again. Debugging is more difficult as a result of binary storage.
The next represents a pattern key and its related (JSON) worth.group_1.record_id_1 = [1, 2, “abc”] //
Self-service
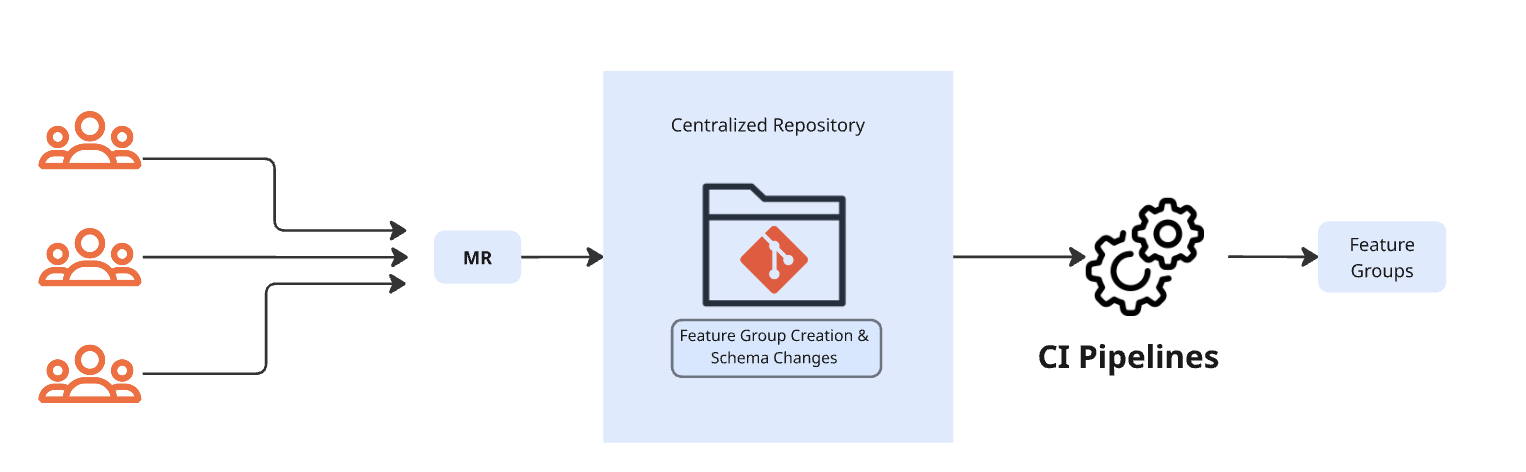
The characteristic retailer structure at Reserving.com has been deliberately designed to facilitate self-service operations amongst a various set of inside groups, thereby minimizing the operational calls for positioned on the core improvement group. The configuration is managed by way of a shared Git repository, the place schema modifications could be submitted by way of merge requests. After a merge request is reviewed and authorized by the group, a devoted CI pipeline pushes the updates into the system. The accompanying diagram supplies a schematic illustration of this end-to-end workflow, highlighting the interplay between contributors, the evaluation course of, and automatic deployment mechanisms.
API service
Entry to the characteristic retailer is supplied by way of a safe REST API, which is applied as a devoted service, so customers can retrieve options. The API service additionally ensures authorization and enforces role-based entry insurance policies. This service was designed, developed, and deployed on Amazon Elastic Kubernetes Service (Amazon EKS) to offer excessive availability and scalability.
The API exposes RESTful endpoints for retrieving, streaming, and deleting options.
Ingestion pipeline and offline retailer
Ingestion isn’t dealt with by way of direct API calls to ElastiCache. The ingestion is Kafka-based to offer scalability, reliability, and suppleness. The method is designed to deal with high-throughput necessities whereas sustaining knowledge integrity.Every characteristic group has a corresponding Kafka matter. The Kafka customers are dynamically initialized utilizing the characteristic group configuration, which is pushed from a Git repository to every shopper pod, permitting them to map Avro-encoded messages on to the corresponding characteristic group columns. After the info is mapped, the customers write the info to ElastiCache. One of many key causes for selecting Kafka is its complete logging and message retention capabilities, which drastically improve the power to hint and debug knowledge ingestion workflows. This degree of transparency helps determine and resolve points rapidly, contributing to the operational resilience of the programs. As well as, Kafka makes it very simple for us to scale the ingestion to our wants. By choosing the proper partitioning scheme for our messages, we will simply ingest 50,000 information per second right into a single characteristic group in ElastiCache.Reserving.com has a deep integration between Kafka and Snowflake, which permits them to materialize matters into offline datasets. Within the context of the characteristic retailer, these materializations are the offline retailer. The offline retailer is utilized by knowledge scientists and engineers to question timestamped options for analytics and mannequin coaching and run time journey queries, the place they’ll reconstruct the system’s state at a given second in time.By utilizing Kafka because the central streaming spine, knowledge workflows are each clear and extremely adaptable, supporting all kinds of use instances throughout the group.Reserving.com picked ElastiCache primarily as a result of following capabilities:
Latency
Our preliminary assessments have proven that ElastiCache can ship single-digit server-side latencies. That is necessary when dealing with thousands and thousands of real-time predictions per minute, because it provides us sufficient room to use knowledge transformations and account for community entry. To be used instances that require ultra-low latency, in-memory clusters guarantee sub-millisecond responses, whereas SSD-backed clusters can be found for workloads that want extra storage capability however can tolerate barely larger latencies.
Scale
ElastiCache clusters can help as much as 500 million requests per second, simply assembly Reserving.com’s necessities for managing 200,000 requests per second, even whereas ingesting at a charge of fifty,000 per second. Its excessive throughput capability and skill to distribute reads throughout a number of replicas assist keep constant efficiency throughout peak visitors. Replication throughout nodes additionally provides resiliency and excessive availability.
Manageability
The managed nature of ElastiCache reduces operational overhead. By way of Terraform, we will handle many clusters centrally and right-size them primarily based on every use case’s demand profile. The system additionally permits workload isolation by spinning up separate clusters per use case, every registered beneath an alias, guaranteeing groups can scale independently with out interference.
Price
In distinction to totally managed options billed per request, ElastiCache is billed primarily based on Amazon Elastic Compute Cloud (Amazon EC2) occasion utilization. This makes it a great and cost-effective answer for prime throughput use instances like ours. Mixed with its flexibility in knowledge varieties and aggressive pricing, ElastiCache permits us to optimize efficiency with out overpaying for infrastructure.
Enterprise outcomes
A major share of ML groups throughout Reserving.com have already built-in the characteristic retailer into their real-time ML pipelines, bringing significant enterprise worth. The platform helps a wide range of use instances, from enhancing fraud detection accuracy and lowering operational prices to enhancing user-facing predictions. Its low-latency API, self-service schema administration, and high-throughput ingestion pipelines assist groups innovate sooner—with out worrying about infrastructure complexity or efficiency bottlenecks.
One of the impactful migrations was in our rating programs, the place transferring to the ElastiCache-backed characteristic platform led to important infrastructure price avoidance, all whereas sustaining ultra-low latency and assembly stricter efficiency necessities than earlier than.
Conclusion
In on-line commerce, latency is a characteristic: if it feels gradual, individuals bounce and enterprise alternatives are misplaced. With AI purposes, the problem will get more durable, because the complicated algorithms and fashions devour a substantial chunk of the latency price range. That’s why you will need to ship the characteristic knowledge as quick as doable to the fashions.
At Reserving.com, we constructed a customized characteristic retailer utilizing Amazon ElastiCache to realize p99.9 beneath 25 ms at roughly 200,000 RPS. The characteristic retailer is constructed on Amazon ElastiCache as its efficiency basis and prolonged with extra performance to ease integration into Reserving.com system panorama, standardize improvement efforts, isolate workloads and optimize price attribution.
This work was made doable by our superb group: Fan Tune, Nithin Kamath, Provide Sharabi, Oleg Taykalo, Rafael Ribeiro, Sagiv Avraham, Sandra Gergawi, and Tolga Eren, alongside us.
In regards to the authors