

{kind=link}
Liquid AI has launched LFM2-2.6B-Exp, an experimental checkpoint of its LFM2-2.6B language mannequin that’s skilled with pure reinforcement studying on prime of the present LFM2 stack. The aim is straightforward, enhance instruction following, data duties, and math for a small 3B class mannequin that also targets on system and edge deployment.
The place LFM2-2.6B-Exp Suits within the LFM2 Household?
LFM2 is the second technology of Liquid Basis Fashions. It’s designed for environment friendly deployment on telephones, laptops, and different edge units. Liquid AI describes LFM2 as a hybrid mannequin that mixes brief vary LIV convolution blocks with grouped question consideration blocks, managed by multiplicative gates.
The household contains 4 dense sizes, LFM2-350M, LFM2-700M, LFM2-1.2B, and LFM2-2.6B. All share a context size of 32,768 tokens, a vocabulary measurement of 65,536, and bfloat16 precision. The two.6B mannequin makes use of 30 layers, with 22 convolution layers and eight consideration layers. Every measurement is skilled on a ten trillion token funds.
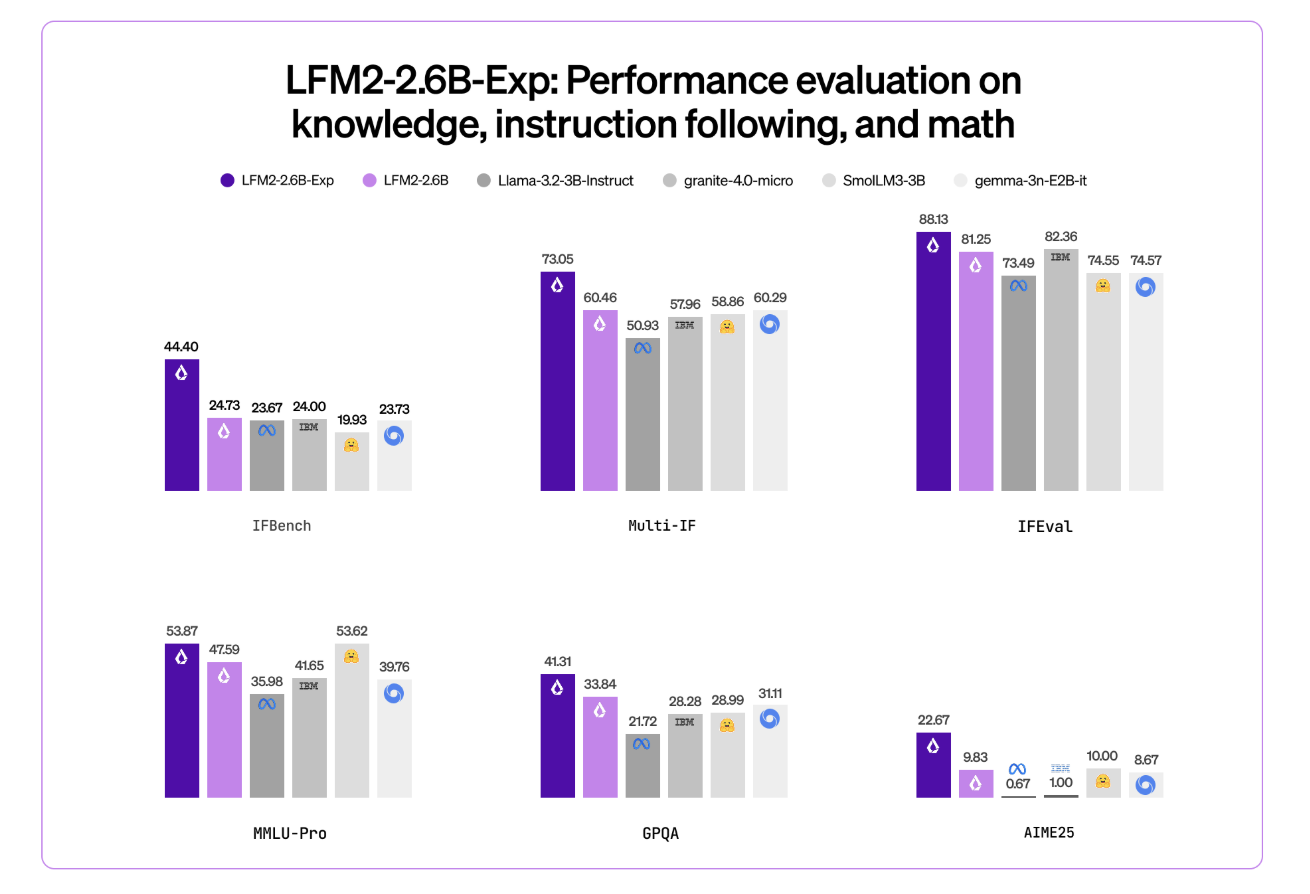
LFM2-2.6B is already positioned as a excessive effectivity mannequin. It reaches 82.41 p.c on GSM8K and 79.56 p.c on IFEval. This locations it forward of a number of 3B class fashions corresponding to Llama 3.2 3B Instruct, Gemma 3 4B it, and SmolLM3 3B on these benchmarks.
LFM2-2.6B-Exp retains this structure. It reuses the identical tokenization, context window, and {hardware} profile. The checkpoint focuses solely on altering conduct by way of a reinforcement studying stage.
Pure RL on High of a Pretrained, Aligned Base
This checkpoint is constructed on LFM2-2.6B utilizing pure reinforcement studying. It’s particularly skilled on instruction following, data, and math.
The underlying LFM2 coaching stack combines a number of levels. It contains very giant scale supervised nice tuning on a mixture of downstream duties and normal domains, customized Direct Desire Optimization with size normalization, iterative mannequin merging, and reinforcement studying with verifiable rewards.
However precisely ‘pure reinforcement studying’ means? LFM2-2.6B-Exp begins from the present LFM2-2.6B checkpoint after which goes by way of a sequential RL coaching schedule. It start with instruction following, then prolong RL coaching to data oriented prompts, math, and a small quantity of software use, with out an extra SFT heat up or distillation step in that closing part.
The necessary level is that LFM2-2.6B-Exp doesn’t change the bottom structure or pre coaching. It modifications the coverage by way of an RL stage that makes use of verifiable rewards, on a focused set of domains, on prime of a mannequin that’s already supervised and desire aligned.
Benchmark Sign, Particularly On IFBench
Liquid AI group highlights IFBench as the principle headline metric. IFBench is an instruction following benchmark that checks how reliably a mannequin follows complicated, constrained directions. On this benchmark, LFM2-2.6B-Exp surpasses DeepSeek R1-0528, which is reported as 263 occasions bigger in parameter rely.
LFM2 fashions present robust efficiency throughout an ordinary set of benchmarks corresponding to MMLU, GPQA, IFEval, GSM8K, and associated suites. The two.6B base mannequin already competes properly within the 3B phase. The RL checkpoint then pushes instruction following and math additional, whereas staying in the identical 3B parameter funds.
Structure and Capabilities that Issues
The structure makes use of 10 double gated brief vary LIV convolution blocks and 6 grouped question consideration blocks, organized in a hybrid stack. This design reduces KV cache value and retains inference quick on shopper GPUs and NPUs.
The pre coaching combination makes use of roughly 75 p.c English, 20 p.c multilingual knowledge, and 5 p.c code. The supported languages embrace English, Arabic, Chinese language, French, German, Japanese, Korean, and Spanish.
LFM2 fashions expose a ChatML like template and native software use tokens. Instruments are described as JSON between devoted software listing markers. The mannequin then emits Python like calls between software name markers and reads software responses between software response markers. This construction makes the mannequin appropriate because the agent core for software calling stacks with out customized immediate engineering.
LFM2-2.6B, and by extension LFM2-2.6B-Exp, can also be the one mannequin within the household that allows dynamic hybrid reasoning by way of particular assume tokens for complicated or multilingual inputs. That functionality stays out there as a result of the RL checkpoint doesn’t change tokenization or structure.
Key Takeaways
- LFM2-2.6B-Exp is an experimental checkpoint of LFM2-2.6B that provides a pure reinforcement studying stage on prime of a pretrained, supervised and desire aligned base, focused at instruction following, data duties, and math.
- The LFM2-2.6B spine makes use of a hybrid structure that mixes double gated brief vary LIV convolution blocks and grouped question consideration blocks, with 30 layers, 22 convolution layers and eight consideration layers, 32,768 token context size, and a ten trillion token coaching funds at 2.6B parameters.
- LFM2-2.6B already achieves robust benchmark scores within the 3B class, round 82.41 p.c on GSM8K and 79.56 p.c on IFEval, and the LFM2-2.6B-Exp RL checkpoint additional improves instruction following and math efficiency with out altering the structure or reminiscence profile.
- Liquid AI studies that on IFBench, an instruction following benchmark, LFM2-2.6B-Exp surpasses DeepSeek R1-0528 although the latter has many extra parameters, which reveals a robust efficiency per parameter for constrained deployment settings.
- LFM2-2.6B-Exp is launched on Hugging Face with open weights below the LFM Open License v1.0 and is supported by way of Transformers, vLLM, llama.cpp GGUF quantizations, and ONNXRuntime, making it appropriate for agentic programs, structured knowledge extraction, retrieval augmented technology, and on system assistants the place a compact 3B mannequin is required.
Take a look at the Mannequin right here. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as properly.
Max is an AI analyst at MarkTechPost, primarily based in Silicon Valley, who actively shapes the way forward for know-how. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI every day to translate complicated tech developments into clear, comprehensible insights