

{kind=link}
Basis mannequin coaching has reached an inflection level the place conventional checkpoint-based restoration strategies have gotten a bottleneck to effectivity and cost-effectiveness. As fashions develop to trillions of parameters and coaching clusters broaden to 1000’s of AI accelerators, even minor disruptions can lead to vital prices and delays.
On this put up, we introduce checkpointless coaching on Amazon SageMaker HyperPod, a paradigm shift in mannequin coaching that reduces the want for conventional checkpointing by enabling peer-to-peer state restoration. Outcomes from production-scale validation present 80–93% discount in restoration time (from 15–half-hour or extra to beneath 2 minutes) and allows as much as 95% coaching goodput on cluster sizes with 1000’s of AI accelerators.
Understanding goodput
Basis mannequin coaching is among the most resource-intensive processes in AI, usually involving tens of millions of {dollars} in compute spend throughout 1000’s of AI accelerators working for days to months. Due to the inherent all-or-none distributed synchrony throughout all ranks, even a lack of a single rank due to software program or {hardware} faults brings the coaching workloads to a whole halt. To mitigate such localized faults, the business has relied on checkpoint-based restoration; periodically saving coaching states (checkpoints) to a sturdy retailer based mostly on a user-defined checkpoint interval. When a fault happens, the coaching workload resumes by restoring from the most recent saved checkpoint. This conventional restart-to-recover mannequin has turn into more and more untenable as mannequin sizes develop from billions to trillions of parameters and coaching workloads develop from a whole bunch to 1000’s of AI accelerators.
This problem of sustaining environment friendly coaching operations at scale has led to the idea of goodput—the precise helpful work completed in an AI coaching system in comparison with its theoretical most capability. In basis mannequin coaching, goodput is impacted by system failures and restoration overhead. The hole between the system’s theoretical most throughput and its precise productive output (goodput) grows bigger with: elevated frequency of failures (which rises with cluster measurement), longer restoration occasions (which scale with mannequin measurement and cluster measurement), and better prices of idle sources throughout restoration. This definition helps body why measuring and optimizing goodput turns into more and more essential as AI coaching scales to bigger clusters and extra advanced fashions, the place even small inefficiencies can lead to vital monetary and time prices.
A pre-training workload on a HyperPod cluster with 256 P5 cases, checkpointing each 20 minutes, faces two challenges when disrupted: 10 minutes of misplaced work plus 10 minutes for restoration. With ml.p5.24xlarge cases costing $55 per hour, every disruption prices $4,693 in compute time. For a month-long coaching, each day disruptions would accumulate to $141,000 in additional prices and delay completion by 10 hours.
As cluster sizes develop, the chance and frequency of failures can improve.
Because the coaching spans throughout 1000’s of nodes, disruptions brought on by faults turn into more and more frequent. In the meantime, restoration turns into slower as a result of the workload reinitialization overhead grows linearly with cluster measurement. The cumulative impression of large-scale AI coaching failures can attain tens of millions of {dollars} yearly and translate on to delayed time-to-market, slower mannequin iteration cycles, and aggressive drawback. Each hour of idle GPU time is an hour not spent advancing mannequin capabilities.
Checkpoint-based restoration
Checkpoint-based restoration in distributed coaching is way extra advanced and time-consuming than generally understood. When a failure happens in conventional distributed coaching, the restart course of includes excess of loading the final checkpoint. Understanding what occurs throughout restoration reveals why it takes so lengthy and why the complete cluster should sit idle.
The all-or-none cascade
A single failure—one GPU error, one community timeout, or one {hardware} fault—can set off a whole coaching cluster shutdown. As a result of distributed coaching treats all processes as tightly coupled, any single failure necessitates a whole restart. When any course of fails, the orchestration system (for instance, TorchElastic or Kubernetes) should terminate each course of throughout the job and restart from scratch. Every restart requires navigating a fancy, multi-stage restoration course of the place each stage is sequential and blocking:
- Stage 1: Coaching job restart – The coaching job orchestrator detects a failure, terminates all processes in all nodes adopted by a cluster-wide restart or the coaching job.
- Stage 2: Course of and community initialization – Each course of should re-execute the coaching script from the start. That features rank initialization, loading of Python modules from sturdy retailer corresponding to Community File System (NFS) or object storage, establishing the coaching topology and communication backend by means of peer discovery and course of teams creation. The method group initialization alone can take tens of minutes on massive clusters.
- Stage 3: Checkpoint retrieval – Every course of should first establish the final utterly saved checkpoint, then retrieve it from persistent storage (for instance, NFS or object storage) and cargo a number of state dictionaries: the mannequin’s parameters and buffers, the optimizer’s inside state (momentum, variance, and so forth), the training price scheduler, and coaching loop metadata (epoch, batch quantity). This step can take tens of minutes or longer relying on cluster and mannequin measurement.
- Stage 4: Information loader initialization – The information-loading ranks have further accountability to initialize the information buffers. That features retrieving the information checkpoint from sturdy storage corresponding to Amazon FSx or Amazon Easy Storage Service (Amazon S3) and prefetching the coaching information to begin the coaching loop. Information checkpointing is an important step to keep away from processing the identical information samples a number of occasions or skipping samples upon coaching disruption. Relying on the information combine technique, information locality, and bandwidth, the method can take a couple of minutes.
- Stage 5: First step overhead – After checkpoint and coaching information are retrieved and loaded, there may be further overhead to run the primary coaching step, we name it first step overhead (FSO). Throughout this primary step, there may be sometimes time spent in reminiscence allocation, creating and establishing the CUDA context for communication with GPUs, and compilation a part of the CUDA graph, and so forth.
- Stage 6: Misplaced steps overhead – Solely in any case earlier phases full efficiently can the coaching loop resume its common progress. As a result of the coaching resumes from the final saved mannequin checkpoint, all of the steps computed between the checkpoint and the fault encountered are misplaced. These misplaced steps have to be recomputed, we name this misplaced steps overhead (LSO). Following the recomputation section, the coaching job resumes productive work that immediately contributes to goodput.
How checkpointless coaching eliminates these bottlenecks
The 5 phases outlined above—termination and restart, course of discovery and community setup, checkpoint retrieval, GPU context reinitialization, and coaching loop resumption—symbolize the elemental bottlenecks in checkpoint-based restoration. Every stage is sequential and blocking, and coaching restoration can take minutes to a number of hours for giant fashions. Critically, the complete cluster should wait for each stage to finish earlier than coaching can resume.
Checkpointless coaching eliminates this cascade. Checkpointless coaching preserves mannequin state coherence throughout the distributed cluster, eliminating the necessity for periodic snapshots. When failures happen, the system shortly recovers by utilizing wholesome friends, avoiding each storage I/O operations and full course of restarts sometimes required by conventional checkpointing approaches.
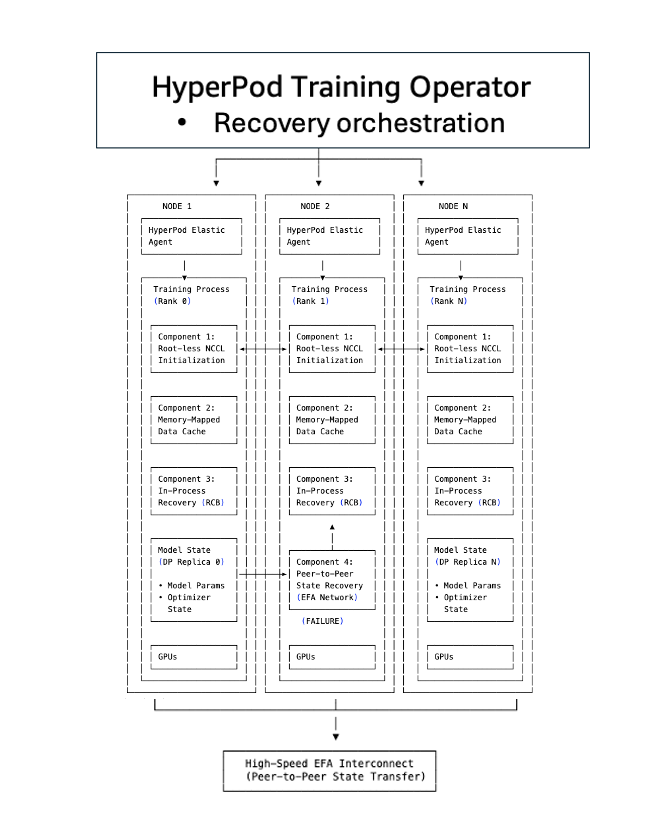
Checkpointless coaching structure
Checkpointless coaching is constructed on 5 elements that work collectively to remove the normal checkpoint-restart bottlenecks. Every part addresses a selected bottleneck within the restoration course of, and collectively they permit computerized detection and restoration of infrastructure faults in minutes with zero guide intervention, even with 1000’s of AI accelerators.
Part 1: TCPStore-less/root-less NCCL and Gloo initialization (optimizing stage 2)
In a typical distributed coaching setup (for instance, utilizing torch.distributed), all ranks should initialize a course of group. The method group creates a communication layer, permitting all processes (or ranks, that’s, particular person nodes) to pay attention to one another and alternate info. A TCPStore is commonly used as a rendezvous level the place all ranks test in to find one another’s connection info. When 1000’s of ranks attempt to contact a designated root server (sometimes rank 0) concurrently, it turns into a bottleneck. This results in a flood of simultaneous community requests to a single root server that may trigger community congestion, improve latency by tens of minutes, and additional sluggish the communication course of.
Checkpointless coaching eliminates this centralized dependency. As an alternative of funneling all connection requests by means of a single root server, the system makes use of a symmetric tackle sample the place every rank independently computes peer connection info utilizing a worldwide group counter. Ranks join immediately to one another utilizing predetermined port assignments, avoiding the TCPStore bottleneck. Course of group initialization drops from tens of minutes to seconds, even on clusters with 1000’s of nodes. The system additionally eliminates the single-point-of-failure threat inherent in root-based initialization.
Part 2: Reminiscence-mapped information loading (optimizing stage 4)
One of many hidden prices in conventional restoration is reloading coaching information. When a course of restarts, it should reload batches from disk, rebuild information loader state, and punctiliously place itself to keep away from processing duplicate samples or skipping information. On large-scale coaching runs, this information loading can add minutes to each restoration cycle.
Checkpointless coaching makes use of memory-mapped information loading to keep up cached information throughout accelerators. Coaching information is mapped into shared reminiscence areas that persist even when particular person processes fail. When a node recovers, it doesn’t reload information from disk however reconnects to the prevailing memory-mapped cache. The information loader state is preserved, serving to to make sure that coaching continues from the right place with out duplicate or skipped samples. MMAP additionally reduces host CPU reminiscence utilization by sustaining just one copy of knowledge per node (in comparison with eight copies with conventional information loaders on 8-GPU nodes), and coaching can resume instantly utilizing cached batches whereas the information loader concurrently prefetches the following information within the background.
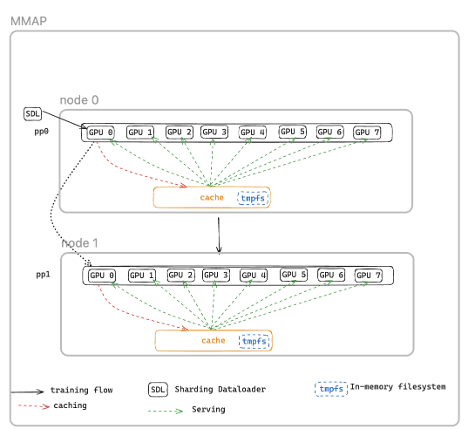
Reminiscence-mapped information loading workflow
Part 3: In-process restoration (optimizing stage 1, 2, and 5)
Conventional checkpoint-based restoration treats failures as job-level occasions: a single GPU error triggers termination of the complete distributed coaching job. Each course of throughout the cluster have to be killed and restarted, although just one part failed.
Checkpointless coaching makes use of in-process restoration to isolate failures on the course of stage. When a GPU or course of fails, solely the failed course of executes an in-process restoration to rejoin the coaching loop inside seconds, overcoming recoverable or transient errors. Wholesome processes proceed working with out interruption. The failed course of stays alive (avoiding full course of teardown), preserving the CUDA context, compiler cache, and GPU state, therefore eliminating minutes of reinitialization overhead. In circumstances the place the error is non-recoverable (corresponding to {hardware} failure), the system robotically swaps the defective part with a pre-warmed scorching spare, enabling coaching to proceed with out disruptions.
This eliminates the necessity for full cluster termination and restart, dramatically lowering restoration overhead.
Part 4: Peer-to-peer state replication (optimizing stage 3 and 6)
Checkpoint-based restoration requires loading mannequin and optimizer state from persistent storage (corresponding to Amazon S3 or FSx for Lustre). For fashions with billions to trillions of parameters, this implies transferring tens to a whole bunch of gigabytes over the community, deserializing state dictionaries, and reconstructing optimizer buffers which might take tens of minutes and create a large I/O bottleneck.
Essentially the most vital innovation in checkpointless coaching is steady peer-to-peer state replication. As an alternative of periodically saving mannequin state to centralized storage, every GPU maintains redundant copies of its mannequin shards on peer GPUs. When a failure happens, the recovering course of doesn’t load from Amazon S3. It copies state immediately from a wholesome peer over the high-speed Elastic Material Adapter (EFA) community interconnect. This peer-to-peer structure eliminates the I/O bottleneck that dominates conventional checkpoint restoration. State switch occurs in seconds, in comparison with minutes for loading multi-gigabyte checkpoints from storage. The recovering node pulls solely the particular shards it wants, additional lowering switch time.
Part 5: SageMaker HyperPod coaching operator (optimizing all phases)
The SageMaker HyperPod coaching operator orchestrates the checkpointless coaching elements, serving because the coordination layer that ties collectively initialization, information loading, checkpointless restoration, and checkpoint fallback mechanisms. It maintains a centralized management aircraft with a worldwide view of coaching course of well being throughout the complete cluster, coordinating fault detection, restoration choices, and cluster-wide synchronization.
The operator implements clever restoration escalation: it first makes an attempt in-process restart for failed elements, and if that’s not possible (for instance, due to container crashes or node failures), it escalates to process-level restoration. Throughout a process-level restoration, as an alternative of restarting the complete job when failures happen, the operator restarts solely coaching processes, protecting the containers alive. Because of this, the restoration occasions are sooner than a job-level restart, which requires tearing down and recreating the coaching infrastructure, involving pod rescheduling, container pulls, setting initialization, and re-loading from checkpoints. When failures happen, the operator broadcasts coordinated cease indicators to forestall cascading timeouts and integrates with the SageMaker HyperPod health-monitoring agent to robotically detect {hardware} points and set off restoration with out guide intervention.
Getting began with checkpointless coaching
This part guides you thru establishing and configuring checkpointless coaching on SageMaker HyperPod to scale back fault restoration from hours to minutes.
Stipulations
Earlier than integrating checkpointless coaching into your coaching workload, confirm that your setting meets the next necessities:
Infrastructure necessities:
Software program necessities:
- Supported frameworks: Nemo, PyTorch, PyTorch Lightning
- Coaching information codecs: JSON, JSONGZ (compressed JSON), or ARROW
- Amazon Elastic Container Registry (Amazon ECR) repository for container pictures. Use the HyperPod checkpointless coaching container—required for rootless NCCL initialization (Tier 1) and peer-to-peer checkpointless restoration (Tier 4)
Checkpointless coaching workflow
Checkpointless coaching is designed for incremental adoption. You can begin with primary capabilities and progressively allow superior options as your coaching scales. The combination is organized into 4 tiers, every constructing on the earlier one:
Tier 1: NCCL initialization optimization
NCCL initialization optimization eliminates the centralized root course of bottleneck throughout initialization. Nodes uncover and hook up with friends independently utilizing infrastructure indicators. This permits sooner course of group initialization (seconds as an alternative of minutes) and elimination of single-point-of-failure throughout startup.
Integration steps: Allow an setting variable as a part of the job specification and confirm that the job runs with the checkpointless coaching container.
Tier 2: Reminiscence-mapped information loading
Reminiscence mapped information loading retains coaching information cached in shared reminiscence throughout course of restarts, eliminating information reload overhead throughout restoration. This permits immediate information entry throughout restoration. No must reload or re-shuffle information when a course of restarts.
Integration steps: Increase the prevailing information loader with a reminiscence mapped cache
Tier 3: In-process restoration
In-process restoration isolates failures to particular person processes as an alternative of requiring full job restarts. Failed processes get well independently whereas wholesome processes proceed coaching. It allows sub-minute restoration from process-level failures. Wholesome processes keep alive, whereas failed processes get well independently.
Integration steps:
Tier 4: Checkpointless (peer-to-peer restoration) (NeMo integration)
Checkpointless restoration allows full peer-to-peer state replication and restoration. Failed processes get well mannequin and optimizer state immediately from wholesome friends with out loading from storage. This step allows elimination of checkpoint loading. Failed processes get well mannequin and optimizer state from wholesome replicas over the high-speed EFA interconnect.
Integration steps:
wait_rank: All ranks will look forward to the rank info from the Hyperod coaching operator infrastructure.
HPWrapper: Python perform wrapper that permits restart capabilities for a restart code block (RCB). The implementation makes use of a context supervisor as an alternative of a Python decorator as a result of the decision wrapper lacks details about the variety of RCBs it ought to monitor.
CudaHealthCheck: Helps make sure that the CUDA context for the present course of is in a wholesome state. It synchronizes with the GPU and makes use of the machine similar to LOCAL_RANK setting variable, or the principle thread’s default CUDA machine if LOCAL_RANK was not specified within the setting.
HPAgentK8sAPIFactory: That is the API that checkpointless coaching will use to grasp the coaching standing from the opposite pods in a K8s coaching cluster. It additionally gives an infrastructure-level barrier, which makes certain each rank can efficiently carry out the abort and restart.
CheckpointManager: Manages in-memory checkpoints and peer-to-peer restoration for checkpointless fault tolerance.
We advocate beginning with Tier 1 and validating it in your setting. Add Tier 2 when information loading overhead turns into a bottleneck. Undertake Tier 3 and Tier 4 for optimum resilience on the most important coaching clusters.
For NeMo customers and HyperPod recipe customers, Tier 4 is out there out-of-the-box with minimal configuration modifications for Llama and GPT open supply recipes. NeMo examples for Llama and GPT open supply fashions may be present in SageMaker HyperPod checkpointless coaching.
Efficiency outcomes
Checkpointless coaching has been validated at manufacturing scale throughout a number of cluster configurations. The most recent Amazon Nova fashions have been skilled utilizing this know-how on tens of 1000’s of AI accelerators.
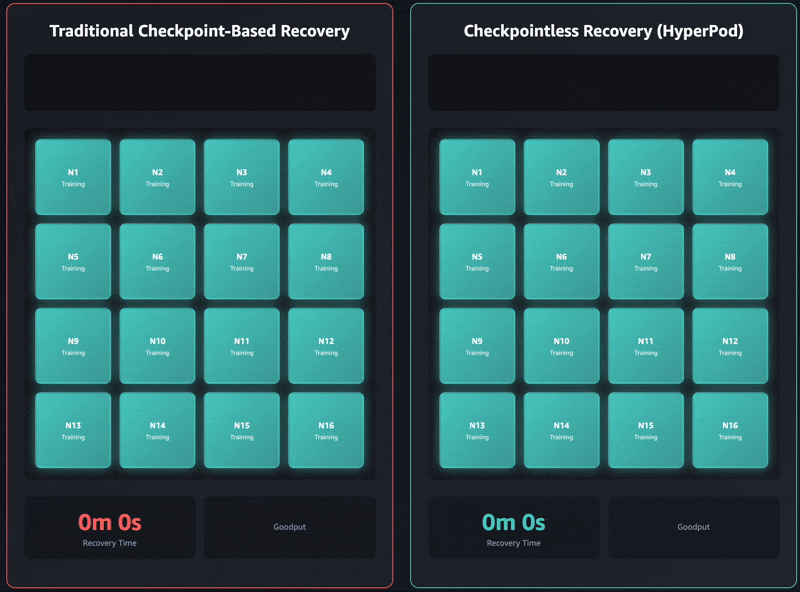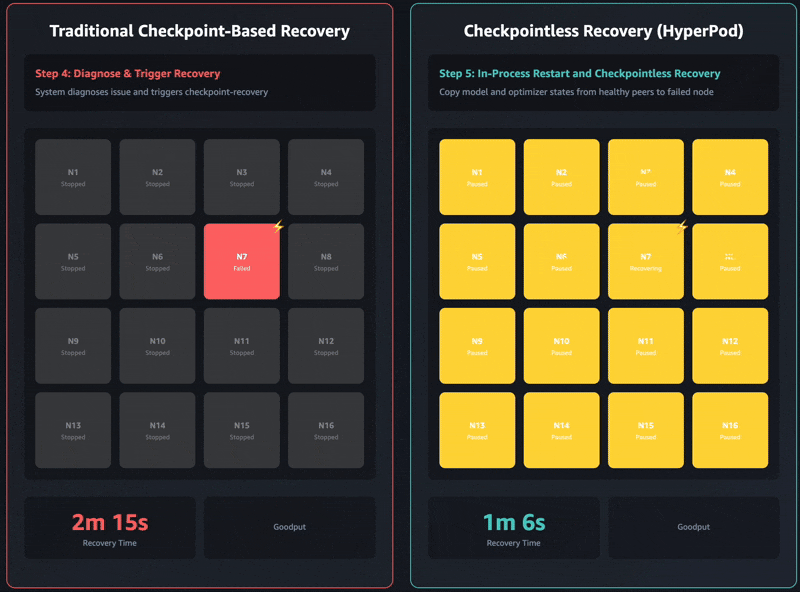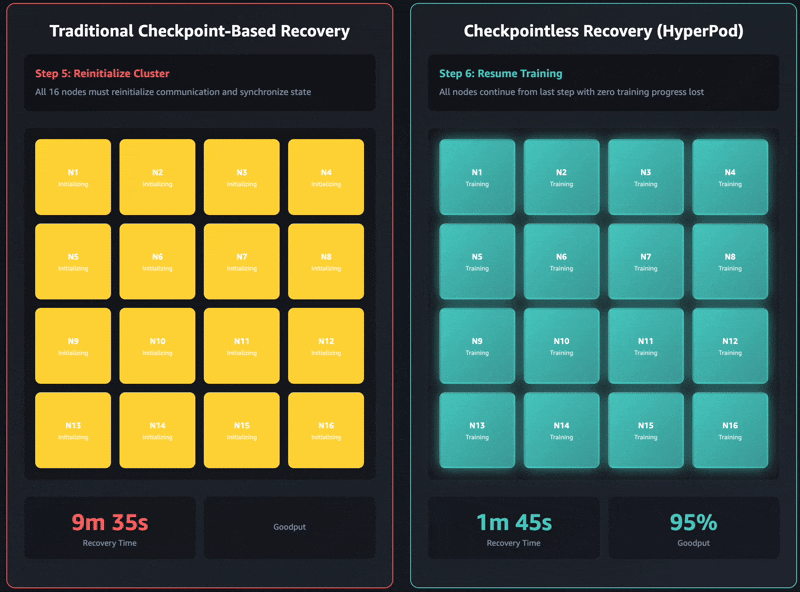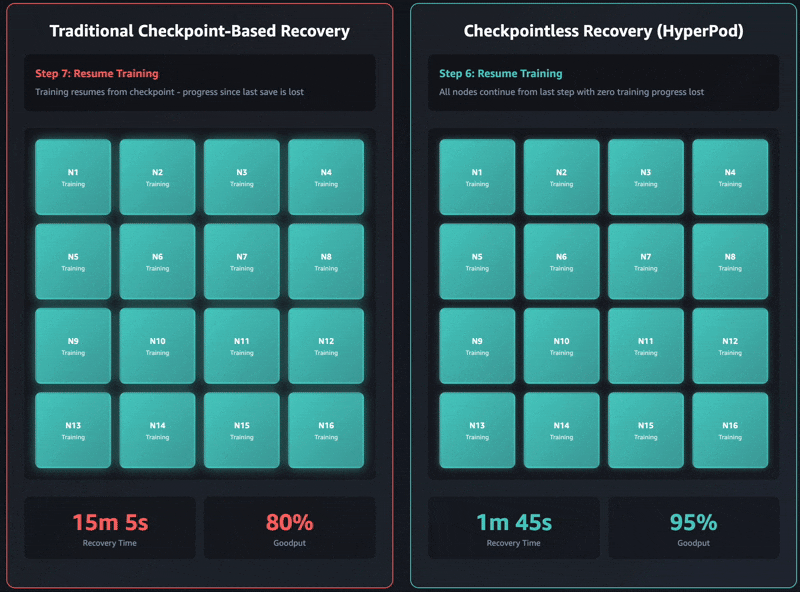
On this part, we exhibit outcomes from intensive testing throughout a variety of cluster sizes, spanning 16 GPUs to 2,304 GPUs. Checkpointless coaching demonstrated vital enhancements in restoration time, persistently lowering downtime by 80–93% in comparison with conventional checkpoint-based restoration.
| Cluster (H100s) | Mannequin | Conventional restoration | Checkpointless restoration | Enchancment |
|---|---|---|---|---|
| 2,304 GPUs | Inside mannequin | 15–half-hour | Lower than 2 minutes | ~87–93% sooner |
| 256 GPUs | Llama-3 70B (pre-training) | 4 min, 52 sec | 47 seconds | ~84% sooner |
| 16 GPUs | Llama-3 70B (fine-tuning) | 5 min 10 sec | 50 seconds | ~84% sooner |
These restoration time enhancements have a direct relationship to ML goodput, outlined as the share of time your cluster spends making ahead progress on coaching quite than sitting idle throughout failures. As clusters scale to 1000’s of nodes, failure frequency will increase proportionally. On the similar time, conventional checkpoint-based restoration occasions additionally improve with cluster measurement resulting from rising coordination overhead. This creates a compounding downside: extra frequent failures mixed with longer restoration occasions quickly erode goodput at scale.
Checkpointless coaching makes optimizations throughout the complete restoration stack, enabling greater than 95% goodput even on clusters with 1000’s of AI accelerators. Based mostly on our inside research, we persistently noticed goodput upwards of 95% throughout massive-scale deployments that exceeded 2,300 GPUs.
We additionally verified that mannequin coaching accuracy isn’t impacted by checkpointless coaching. Particularly, we measured checksum matching for conventional checkpoint-based coaching and checkpointless coaching, and at each coaching step verified a bit-wise match on coaching loss. The next is a plot for the coaching loss for a Llama-3 70B pre-training workload on 32 x ml.p5.48xlarge cases for each conventional checkpointing versus checkpointless coaching.

Conclusion
Basis mannequin coaching has reached an inflection level. As clusters scale to 1000’s of AI accelerators and coaching runs lengthen to months, the normal checkpoint-based restoration paradigm is more and more changing into a bottleneck. A single GPU failure that beforehand would have brought about minutes of downtime now triggers tens of minutes of cluster-wide idle time on 1000’s of AI accelerators, with cumulative prices reaching tens of millions of {dollars} yearly.
Checkpointless coaching rethinks this paradigm completely by treating failures as native, recoverable occasions quite than cluster-wide catastrophes. Failed processes get well state from wholesome friends in seconds, enabling the remainder of the cluster to proceed making ahead progress. The shift is key: from How can we restart shortly? to How can we keep away from stopping in any respect?
This know-how has enabled greater than 95% goodput when coaching on SageMaker HyperPod. Our inside research on 2,304 GPUs present restoration occasions dropped from 15–half-hour to beneath 90 seconds, translating to over 80% discount in idle GPU time per failure.
To get began, discover What’s Amazon SageMaker AI?. Pattern implementations and recipes can be found within the AWS GitHub HyperPod checkpointless coaching and SageMaker HyperPod recipes repositories.
In regards to the Authors
 Anirudh Viswanathan is a Senior Product Supervisor, Technical, at AWS with the SageMaker staff, the place he focuses on Machine Studying. He holds a Grasp’s in Robotics from Carnegie Mellon College and an MBA from the Wharton College of Enterprise. Anirudh is a named inventor on greater than 50 AI/ML patents. He enjoys long-distance working, exploring artwork galleries, and attending Broadway reveals. You’ll be able to join with Anirudh on LinkedIn.
Anirudh Viswanathan is a Senior Product Supervisor, Technical, at AWS with the SageMaker staff, the place he focuses on Machine Studying. He holds a Grasp’s in Robotics from Carnegie Mellon College and an MBA from the Wharton College of Enterprise. Anirudh is a named inventor on greater than 50 AI/ML patents. He enjoys long-distance working, exploring artwork galleries, and attending Broadway reveals. You’ll be able to join with Anirudh on LinkedIn.
 Roy Allela is a Senior AI/ML Specialist Options Architect at AWS. He helps AWS prospects, from small startups to massive enterprises to coach and deploy basis fashions effectively on AWS. He has a background in Microprocessor Engineering enthusiastic about computational optimization issues and enhancing the efficiency of AI workloads. You’ll be able to join with Roy on LinkedIn.
Roy Allela is a Senior AI/ML Specialist Options Architect at AWS. He helps AWS prospects, from small startups to massive enterprises to coach and deploy basis fashions effectively on AWS. He has a background in Microprocessor Engineering enthusiastic about computational optimization issues and enhancing the efficiency of AI workloads. You’ll be able to join with Roy on LinkedIn.
 Fei Wu is a Senior Software program Developer at AWS with Sagemaker staff. Fei’s focus is on ML system and distributed coaching strategies. He holds a PhD in Electrical Engineering from StonyBrook College. When exterior of labor, Fei enjoys taking part in basketball and watching motion pictures. You’ll be able to join with Fei on LinkedIn.
Fei Wu is a Senior Software program Developer at AWS with Sagemaker staff. Fei’s focus is on ML system and distributed coaching strategies. He holds a PhD in Electrical Engineering from StonyBrook College. When exterior of labor, Fei enjoys taking part in basketball and watching motion pictures. You’ll be able to join with Fei on LinkedIn.
 Trevor Harvey is a Principal Specialist in Generative AI at Amazon Internet Providers (AWS) and an AWS Licensed Options Architect – Skilled. At AWS, Trevor works with prospects to design and implement machine studying options and leads go-to-market methods for generative AI companies.
Trevor Harvey is a Principal Specialist in Generative AI at Amazon Internet Providers (AWS) and an AWS Licensed Options Architect – Skilled. At AWS, Trevor works with prospects to design and implement machine studying options and leads go-to-market methods for generative AI companies.
 Anirban Roy is a Principal Engineer at AWS with the SageMaker staff, primarily focussing on AI coaching infra, resiliency and observability. He holds a Grasp’s in Laptop Science from Indian Statistical Institute in Kolkata. Anirban is a seasoned distributed software program system builder with greater than 20 years of expertise and a number of patents and publications. He enjoys street biking, studying non-fiction, gardening and nature touring. You’ll be able to join with Anirban on LinkedIn
Anirban Roy is a Principal Engineer at AWS with the SageMaker staff, primarily focussing on AI coaching infra, resiliency and observability. He holds a Grasp’s in Laptop Science from Indian Statistical Institute in Kolkata. Anirban is a seasoned distributed software program system builder with greater than 20 years of expertise and a number of patents and publications. He enjoys street biking, studying non-fiction, gardening and nature touring. You’ll be able to join with Anirban on LinkedIn
 Arun Nagarajan is a Principal Engineer on the Amazon SageMaker AI staff, the place he at present focuses on distributed coaching throughout the complete stack. Since becoming a member of the SageMaker staff throughout its launch yr, Arun has contributed to a number of merchandise inside SageMaker AI, together with real-time inference and MLOps options. When he’s not engaged on machine studying infrastructure, he enjoys exploring the outside within the Pacific Northwest and hitting the slopes for snowboarding.
Arun Nagarajan is a Principal Engineer on the Amazon SageMaker AI staff, the place he at present focuses on distributed coaching throughout the complete stack. Since becoming a member of the SageMaker staff throughout its launch yr, Arun has contributed to a number of merchandise inside SageMaker AI, together with real-time inference and MLOps options. When he’s not engaged on machine studying infrastructure, he enjoys exploring the outside within the Pacific Northwest and hitting the slopes for snowboarding.