
 – Half 1")
{kind=link}
This can be a visitor weblog submit by Richard Loveday, Head of Product at Graph.Construct, in partnership with Charles Ivie, Graph Architect at AWS.
The Graph.Construct platform is a devoted, no-code graph mannequin design studio and construct manufacturing facility, out there on AWS Market.
Data graphs have been extensively adopted by organizations, powering use instances reminiscent of social media networks, fraud detection, digital twin, and drug discovery. The rise of huge language fashions (LLMs) has accelerated curiosity, as data graphs present a great structured basis for LLM interactions. This has led to their adoption as major knowledge repositories for organizations of all sizes.
Nonetheless, widespread adoption is hindered by a scarcity of accessible tooling and the experience required to implement these techniques. Consequently, many organizations have struggled to reap the benefits of what’s in any other case an intuitive and highly effective method to knowledge modeling.
On this sequence of posts we reveal how you can construct and handle a whole data graph resolution from begin to end with out writing a single line of code, integrating Amazon Neptune with the next AWS Market tooling:
The lifecycle of a data graph resolution is a steady loop of 4 distinct phases:
- Schema Design: Set up the foundational blueprint (the schema or ontology) that defines the sorts of entities and relationships.
- Information Ingestion and Modeling: Ingest and map disparate knowledge sources to the ontology, constructing the graph mannequin.
- Persistence: Load the ensuing graph mannequin right into a native graph database for environment friendly storage and retrieval.
- Exploration and Discovery: Make the most of the graph by querying and analyzing its connections to find invaluable details and insights.
This sequence is cut up into two components, every specializing in a particular instrument to information you thru this lifecycle:
Half 1 (this submit): Design, ingestion, modelling and persistence
We use Graph.Construct to visually design our ontology, hook up with present knowledge sources like SQL and JSON to construct our graph mannequin, and persist the mannequin immediately into Amazon Neptune.
Half 2: Exploration and discovery
We’ll then use G.V() to hook up with our graph in Neptune, enabling no-code exploration, querying, and evaluation to find invaluable insights.
Answer overview
Each Neptune and Graph.Construct help Labeled Property Graph (LPG) and Useful resource Description Framework (RDF) fashions. On this submit, we reveal a typical LPG use case to establish monetary crimes.
Graph.Construct permits you to design and construct graph schemas and fashions visually.
We design and construct the next small instance schema and mannequin that represents the beginning of such a use case. The mannequin describes folks, possession of bank cards, and some associated properties.
Graph databases like Amazon Neptune allow highly effective, relationship-based queries as soon as knowledge is structured in a well-defined ontological mannequin. Designing these fashions and reworking structured or semi-structured knowledge into the required Labeled Property Graph (LPG) format is a crucial step on this course of. On this first a part of the submit, we discover how you can streamline this workflow utilizing Graph.Construct, making the method quicker and extra accessible—with out writing any code.
With Graph.Construct, you possibly can visually outline a graph schema (ontology) and generate an extract, remodel, and cargo (ETL) mannequin that robotically transforms various knowledge sources, together with SQL databases, CSV information, and JSON feeds, into graph fashions staged and prepared for ingestion into Neptune. This no-code method alleviates the necessity for handbook knowledge mapping and transformation logic, making it easy to construction and ingest knowledge effectively.
Graph.Construct can course of massive CSV information by configurable batch processing, and enormous numbers of small information by consuming a Kafka queue detailing the information.
After it’s created the Graph.Construct Author automates loading the brand new graph fashions into Neptune, finishing the end-to-end ETL workflow. For brevity, this submit gives an summary of the steps used within the Graph.Construct Studio. For detailed, step-by-step directions, discuss with the graph.construct documentation.
We carry out the next steps.
- Deploy and configure Graph.Construct on Amazon Elastic Container Service (Amazon ECS) utilizing AWS CloudFormation.
- Design a brand new property graph schema.
- Design Graph.Construct linked mappings conforming to the brand new schema:
- Supply and construct a graph mannequin from JSON information in Amazon Easy Storage Service (Amazon S3).
- Supply and construct a graph mannequin from Amazon RDS.
- Write the linked graph fashions to Amazon Neptune.
The answer is deployed as follows
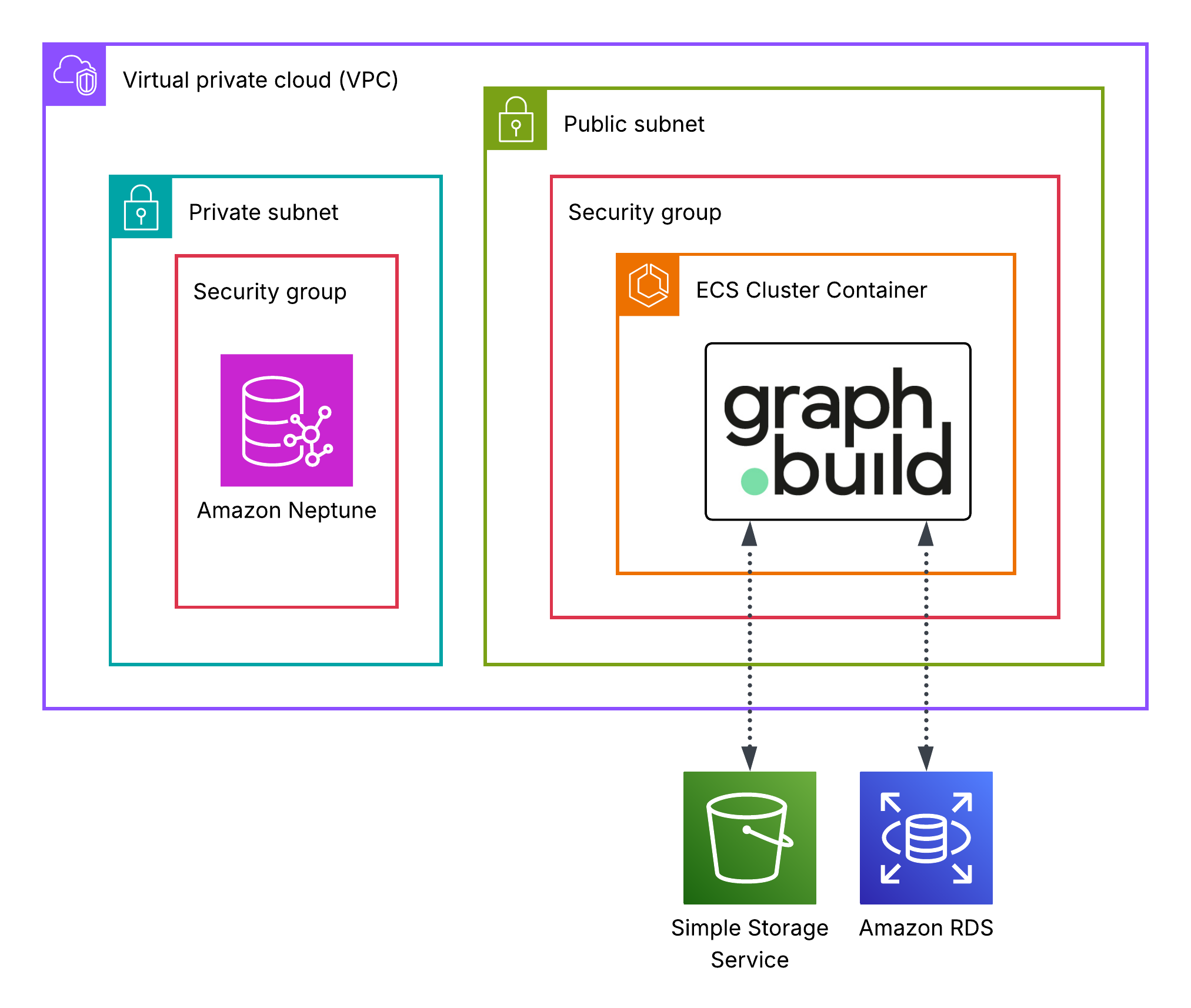
Stipulations
On this submit we present you how you can map knowledge from present knowledge sources to a newly designed graph schema after which construct a brand new Graph mannequin for Amazon Neptune. Though Graph.Construct removes the necessity for code on this course of, a primary understanding of Graph databases, SQL, JSON and AWS is required, in addition to the next
A operating Amazon Neptune database cluster.
Comply with the information on the Amazon Neptune documentation for creating an Amazon Neptune cluster.
Go to the Amazon Neptune documentation for extra details about graph databases.
AWS Market subscription to the required Graph.Construct companies.
The Graph.Construct platform is out there on AWS Market, with a free 14-day trial. Every service solely prices when it’s operating. As soon as the free 14-day trial is accomplished, companies will incur their particular person per-hour value:
Examples are from the N. Virginia area.
|
Graph Construct Studio Small |
14-day free trial, then $0.41 per hour |
|
Semi-Structured Transformer |
14-day free trial, then $2.14 per hour |
|
SQL Transformer |
14-day free trial, then $2.56 per hour |
|
Graph Author |
14-day free trial, then $1.70 per hour |
To observe alongside, subscribe to the next Graph.Construct companies:
All pricing is along with the prices of the AWS infrastructure which it’s operating on.
Deploy and configure Graph.Construct on ECS utilizing AWS CloudFormation
Comply with the information on the Graph.Construct documentation to deploy a Graph.Construct cluster on Amazon Elastic Container Service (ECS) utilizing AWS CloudFormation, taking care to observe the trail for the AWS market template.
As soon as the AWS CloudFormation template completes efficiently, within the outputs tab, pay attention to the ApplicationURL and StudioAdminPasswordSecret worth’s, as you have to them within the subsequent step.
Design a brand new property graph schema
Amazon Neptune doesn’t require, and can’t implement a predefined schema, however schema’s are a strong approach to make sure knowledge consistency. Graph.Construct allows you to design a schema that guides the information modeling course of, in order that the graph written to Neptune conforms to your supposed construction.In your browser, navigate to the ApplicationURL famous down from the earlier step.
Login to Graph.Construct studio with the next credentials.
Username = SuperAdmin
Password = { StudioAdminPassword }
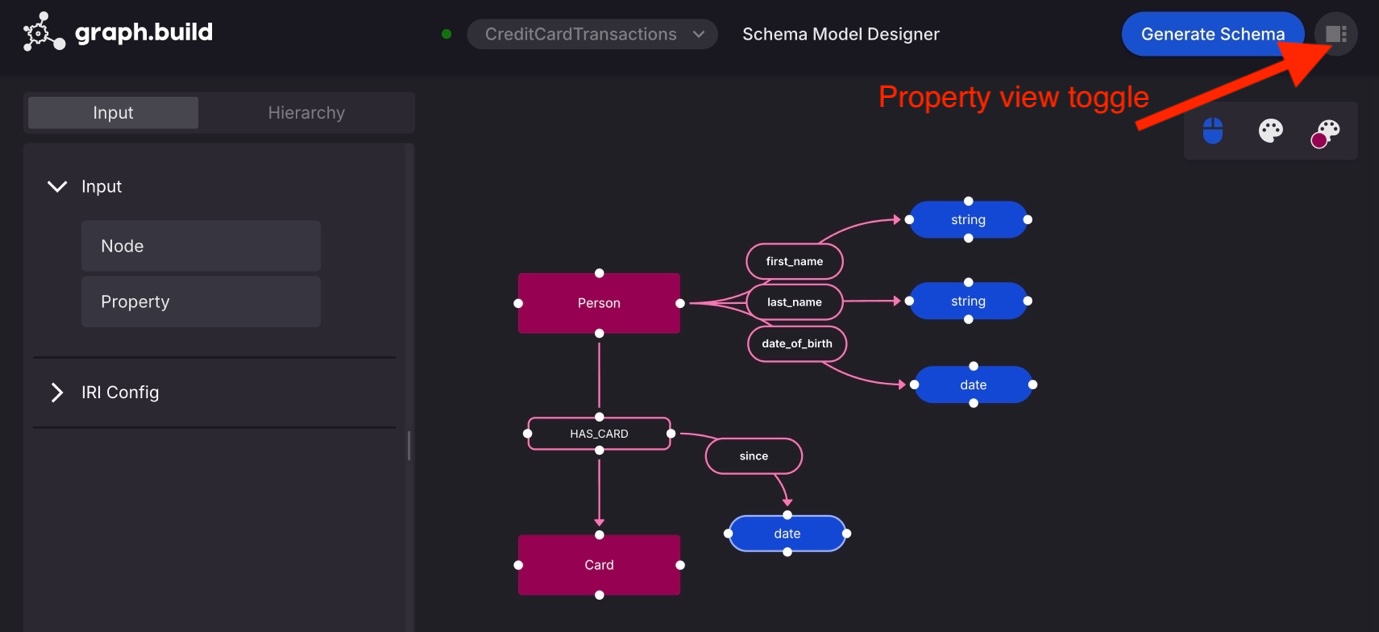
Select Schema / Ontology Fashions, New Mannequin

- In step 1, Select Property Graph, skip step 2 and for step 3, title your property graph schema
Credit score Card Transactions - Drag in a brand new Node to the canvas, add select the label
Individual - Choose the
Individualnode, and add a property referred to asfirst_nameof kindString
Repeat the method so as to add the properties last_name (String) and date_of_birth (Date) - Create one other Node referred to as
Cardand draw a brand new connection ranging fromIndividualand terminating atCard. Title the stingHAS_CARD - Add a property referred to as
sincewith knowledge kind date to the brand newHAS_CARDedge, utilizing the identical course of as including a property to a node. - Select Generate Schema, Publish Schema
(OPTIONAL) Toggle the properties view mode button to edit properties in an expanded view.
Supply and construct a graph mannequin from JSON information in S3
Now that we’ve our schema, we will construct graph fashions that map our schema to every supply’s schema.
For the primary knowledge supply we select JSON, in S3.
- Select the
graph.constructemblem, then navigate to Designs, Semi Structured Fashions, New Mannequin.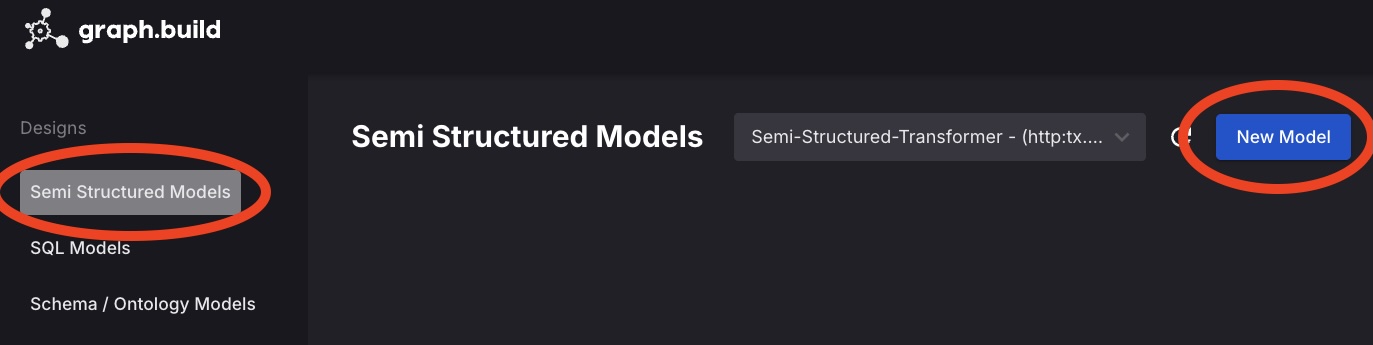
- Copy the next artificial JSON knowledge and retailer it in a file referred to as
pattern.json.The JSON pattern is meant to be a pattern of a bigger JSON knowledge mannequin that you simply want to remodel to Graph. As soon as the next design has been accomplished, a change might be executed in opposition to as many JSON information as you want, offered they’ve the identical construction, they are going to behave in the identical approach.
- Select Property Graph, then
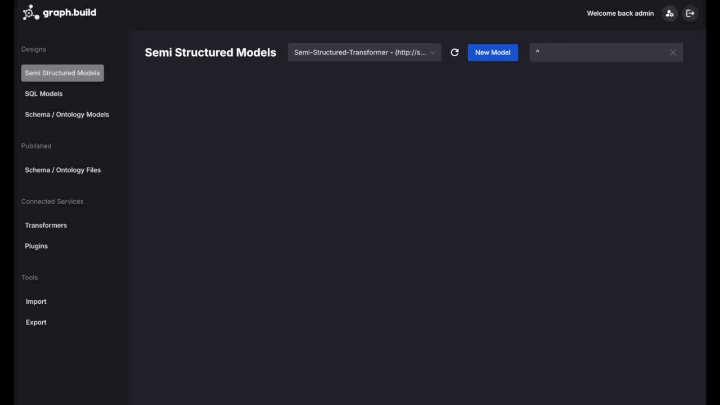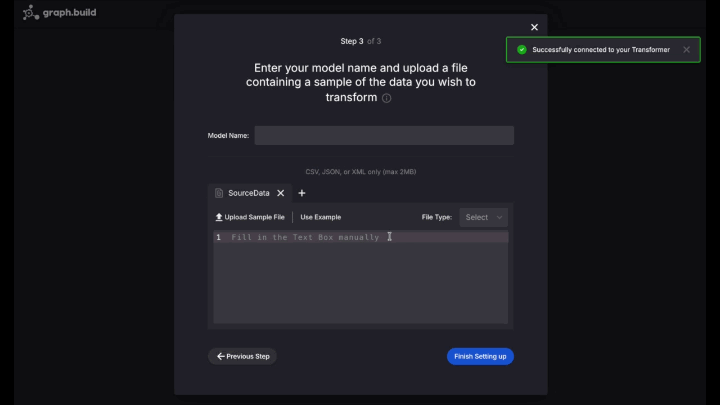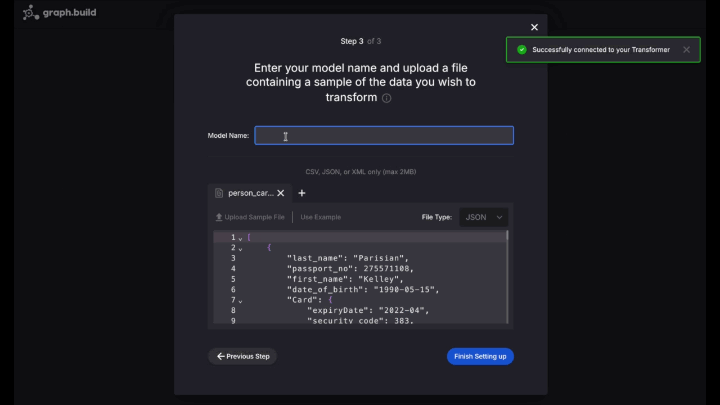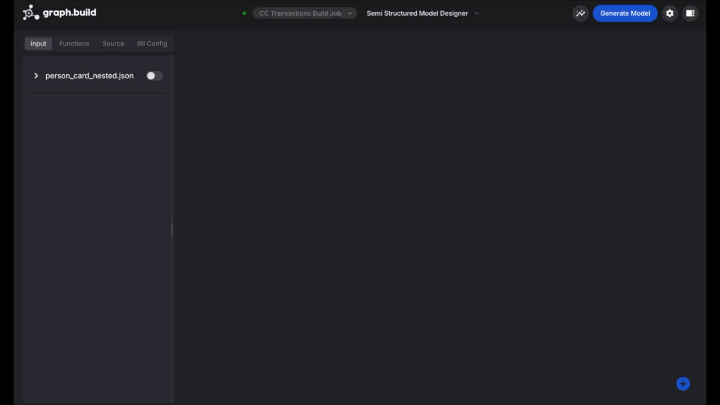
Credit score Card Transactionsschema, Subsequent Step. - Title your new mannequin
PersonCard - Select Add Pattern File, and select the
pattern.jsonknowledge file, then End Setting Up
The following display screen exhibits all of the JSON keys which might be out there to construct the Graph mannequin. These JSON keys are generally known as ‘enter blocks’.
Create your first Node / Vertex.
- Drag the
CardNoenter block onto the canvas, select Node and beneath Node Settings, Label, select Card and Apply. - Repeat the method to create the
Individualnode, utilizingPassportNobecause the enter block, then draw a brand new edge between the nodes. Observe that theHAS_CARDedge is robotically populated, as it’s the solely legitimate edge between theIndividualandCardnodes. - Add the properties to the mannequin by deciding on a node or edge, selecting the property key, knowledge kind and template mapping to the supply JSON.
- Select Generate Mannequin, Check Mannequin to assessment the graph mannequin.
- Obtain the check consequence and examine the nodes and edges information. These information are suitable with Amazon Neptune and might be loaded into Amazon Neptune utilizing the bulk loader.
- Shut the check consequence window, select Generate Mannequin, Publish Mannequin to arrange the transformation job to course of any file of the identical format.
Execute the brand new transformation job on a file positioned in S3
Now you may have printed your transformation mannequin, you possibly can execute the job on any file with the identical construction that resides in S3. Select the execute button, set the Enter File to:
Choose person_card_nested.json for the mannequin reference.
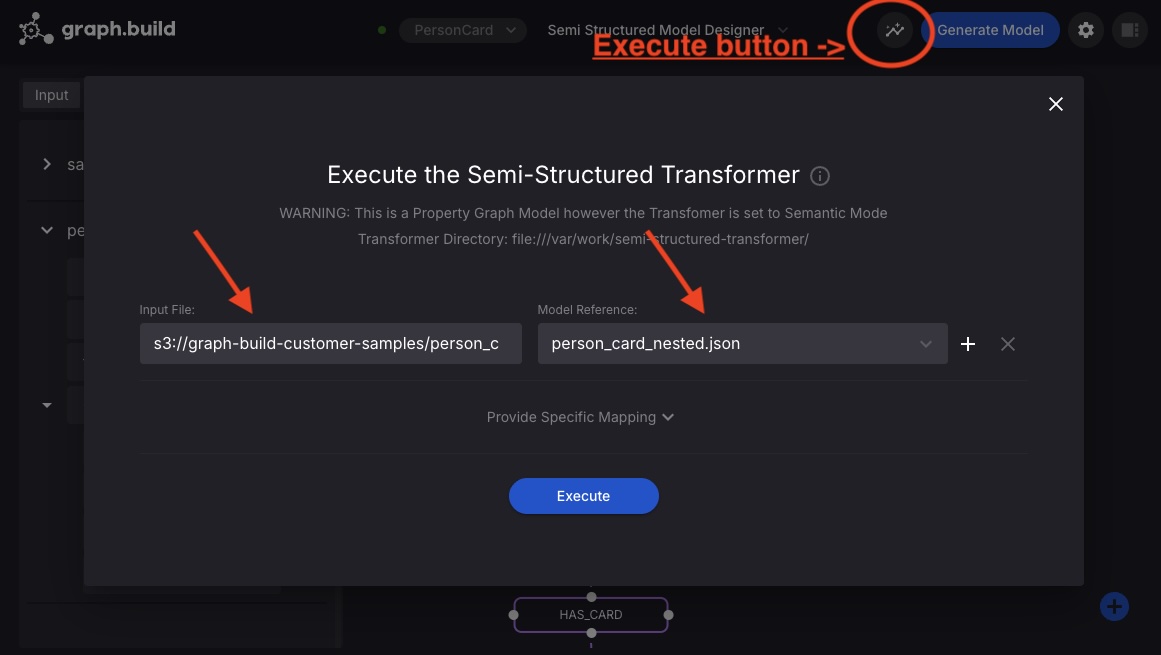
Discuss with the graph.construct documentation for how you can set off transformations utilizing REST.
As soon as the execution is full, the brand new graph mannequin endured again to the outputs folder for the Semi Structured transformer within the S3 bucket created throughout AWS CloudFormation.
Discuss with the graph.construct documentation to processing massive or quite a few information of JSON, XML or CSV that reside in S3, and automate replace and insert graph mannequin operations to Amazon Neptune utilizing the Graph.Construct Author.
Supply and construct a graph mannequin from a SQL database
In addition to constructing Graph fashions from information in JSON, CSV, and XML format, Graph.Construct can even pull knowledge from a SQL endpoint through a JDBC connection.
Connection sorts embody Amazon Athena, Amazon RDS, Amazon Aurora, and another JDBC connection.
Artificial knowledge has been created and saved in an RDS database.
This database is publicly out there and free to make use of for experimentation with Graph.Construct.
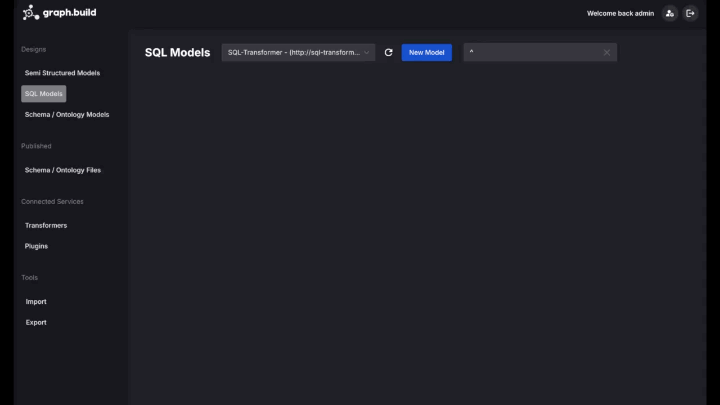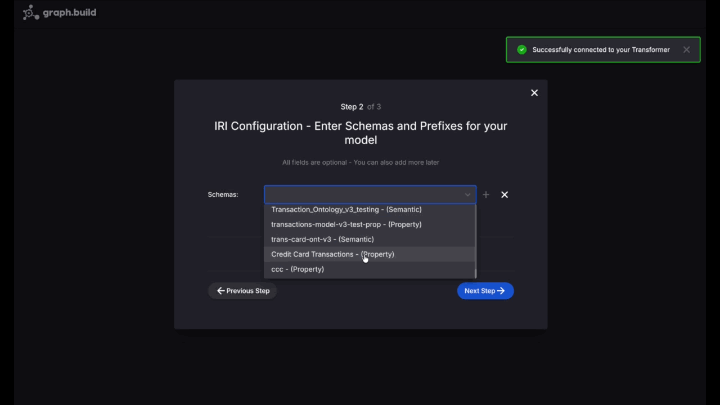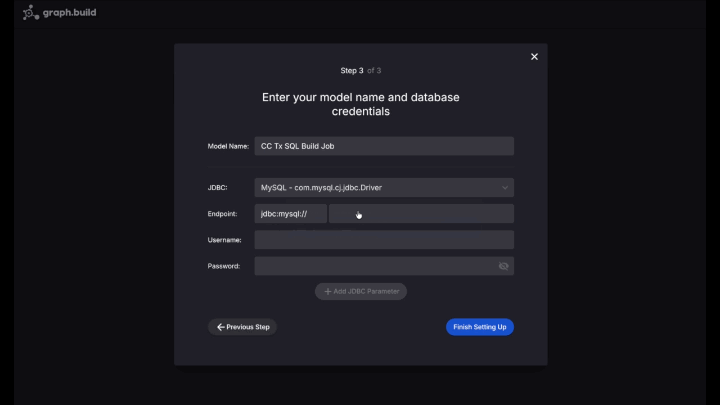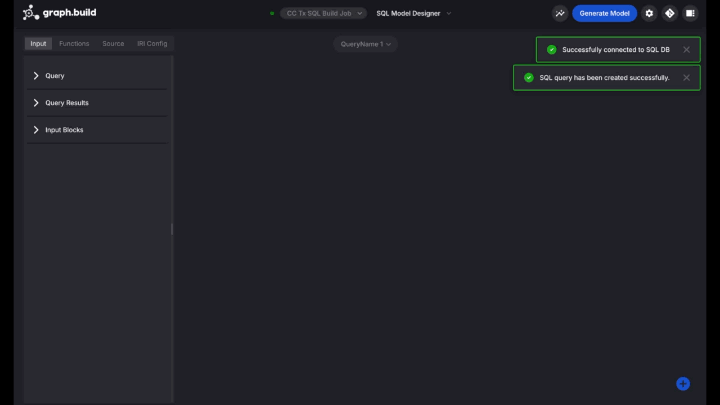
Select the graph.construct emblem, then navigate to Designs, SQL Fashions, New Mannequin, step thorough the setup as earlier than, inputting the next connection particulars for the SQL endpoint.
|
Driver |
com.mysql.cj.jdbc.Driver |
|
Endpoint |
card-data.crlz1hrnweup.us-east-1.rds.amazonaws.com:3306/carddata |
|
Username |
readonly_user |
|
Password |
readonly_graphbuild123 |
As soon as linked, insert the next question, and execute:
Question outcomes are robotically restricted by configuration to keep away from issues with massive scale consequence units.
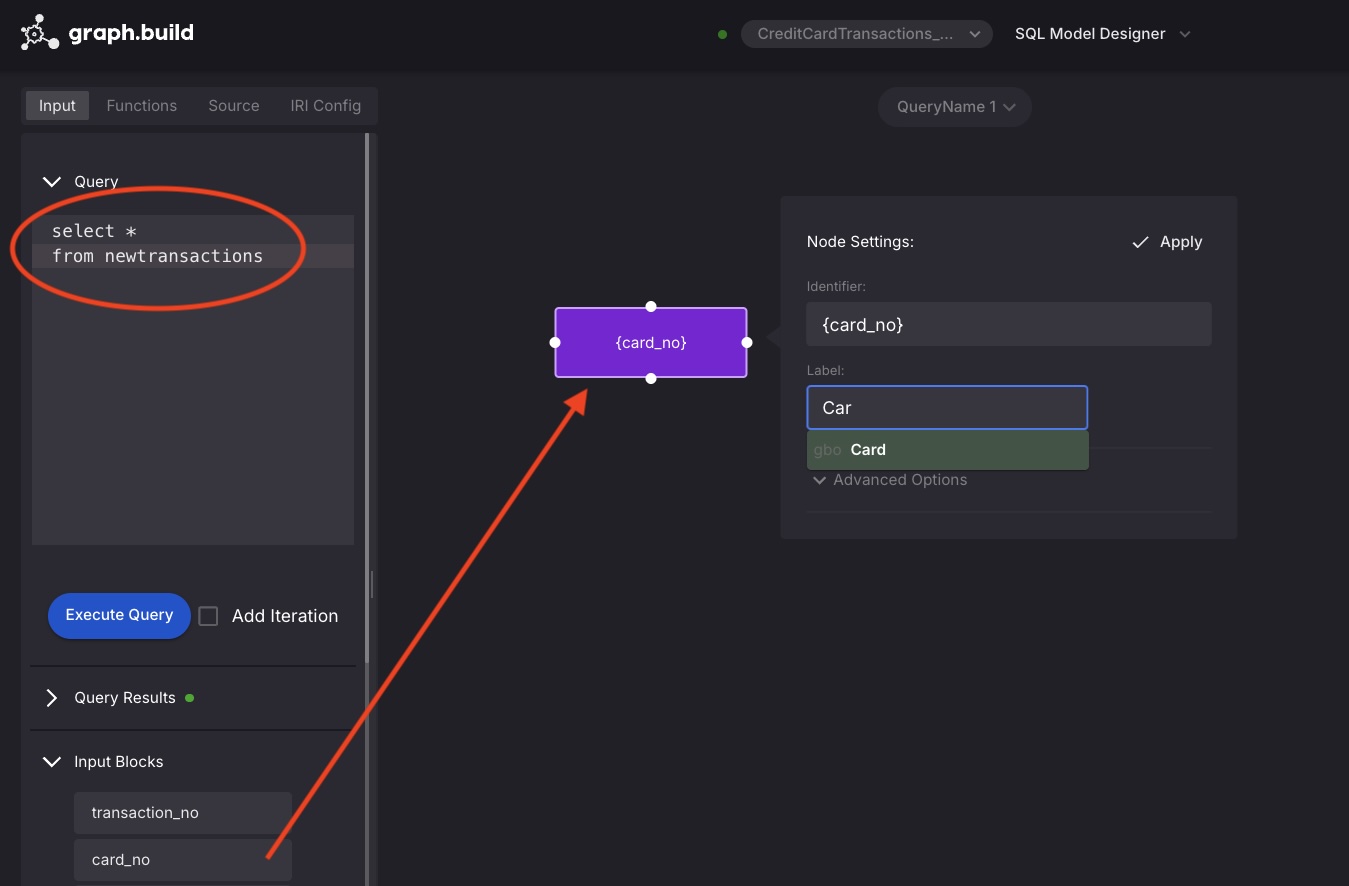
Full a mannequin as beforehand described for the JSON knowledge supply.
As soon as full, choose the execute button (as proven within the JSON instance beforehand) and select execute.
As soon as the transformation is full, you will discover the graph mannequin information within the output listing for the SQL transformer within the S3 bucket created throughout AWS CloudFormation.
As soon as in S3, fashions might be loaded into Amazon Neptune utilizing the majority loader, or Kafka might be configured to robotically insert or replace graph fashions to Amazon Neptune utilizing the graph.construct author.
Cleanup
Navigate to the AWS CloudFormation console.
Select Stacks, flip off view nested, choose your graph.construct stack and Delete.
Conclusion
On this submit, we demonstrated how you can design, check, and construct graph fashions, then load them into Amazon Neptune, with no code.
Utilizing Graph.Construct on AWS vastly reduces the effort and time it takes to iterate on graph options, which means extra time might be spent on perfecting the answer and fewer on code and infrastructure.
Now that you’ve got your knowledge loaded, you’re prepared to start out exploring. Within the subsequent submit on this sequence, we’ll present you the way to hook up with your Neptune cluster with G.V() to question, analyze, and uncover new insights. To start constructing your individual data graph, discover Graph.Construct on the AWS Market.
In regards to the Authors