

{kind=link}
Once we run databases in Kubernetes, we shortly be taught one vital fact: issues will fail, and we should be ready for this. Pods are ephemeral; nodes can come and go, storage is abstracted behind PersistentVolumes and will be both native to a node or backed by community storage, and Kubernetes strikes workloads as wanted by deployments, upgrades, and rollouts.
Due to this, replication is not restricted to a database setting. It influences how MySQL survives failures, scales, and performs inside a dynamic Kubernetes setting the place adjustments occur naturally because the platform manages workloads.
Excessive availability for MySQL working in Kubernetes relies upon closely on how the database replicates information throughout nodes. Replication determines how effectively MySQL handles failures and the way reliably an operator can carry out automated failovers. That’s why understanding the distinction between just about synchronous (SYNC) and asynchronous (ASYNC) replication is crucial for working MySQL reliably in cloud-native environments.
In easy phrases, just about synchronous replication implies that all nodes verify a write earlier than it’s thought of profitable, making certain information consistency. However, asynchronous replication commits the write on the first first, and replicas catch up afterwards, which improves efficiency however could introduce minimal lag. These two fashions outline how MySQL clusters behave throughout failures, updates and scaling occasions.
When you want a fast refresher on MySQL replication, we advocate Dimitri Vanoverbeke’s article, “An Introduction to MySQL Replication.” It’s an incredible background earlier than we dive into the cloud-native method.
Let’s speak about what this implies for MySQL in Kubernetes.
Some of the vital choices you make when deploying MySQL in these environments is selecting between just about synchronous (SYNC) and asynchronous (ASYNC) replication. Each are beneficial, each are extensively used, and each make good sense relying on the enterprise downside you are attempting to resolve. On this submit, we clarify these ideas in a easy and pleasant means, making them straightforward to comply with for anybody working with MySQL in Kubernetes.
Replication in a Cloud-Native World
The significance of replication inside the cloud-native ecosystem is paramount. When deploying a database cluster on trendy platforms comparable to Kubernetes, the right architectural perspective is to view the cluster not as a group of distinct nodes, however as a cohesive, singular database service.
This method marks a big divergence from conventional on-premises or digital machine (VM) deployments. In these typical environments, practitioners sometimes deal with and entry every constituent cluster node as a separate, individually operable element. Cloud-native platforms, together with Kubernetes, are basically engineered to ship an summary service layer that inherently manages inner scaling and leverages the underlying pool of cluster nodes for its operational capability.
Consequently, for database programs, the important service goal is to ensure dependable, scalable, and extremely accessible entry to persistent information. Replication is the indispensable mechanism by which this goal is achieved.
Its vital function implies that replication has a a lot greater affect on the general habits of the database. It influences how MySQL responds to updates, failovers, or disruptions within the underlying infrastructure. Many Kubernetes operators already embody safeguards comparable to StatefulSets, readiness checks, PodDisruptionBudgets, and managed failover logic to assist coordinate cluster occasions with the chosen replication technique.
That is the place Nearly SYNC and ASYNC enter; these are varieties of replication, and the one you select will immediately have an effect on how MySQL behaves throughout rolling updates, node disruptions, or failovers.
Nearly Synchronous Replication (SYNC)
Nearly Synchronous replication ensures {that a} transaction is barely confirmed as soon as the complete cluster agrees; it may be safely utilized. This mannequin is utilized in applied sciences like Galera, the place nodes coordinate earlier than committing any change.
When the shopper sends a write, one of many nodes processes the transaction after which shares the ensuing adjustments with the remainder of the cluster. Every node performs a certification verify to confirm that the write doesn’t battle with different in-flight transactions. Solely in any case nodes return a constructive certification does the cluster attain settlement, and the shopper receives the ultimate acknowledgement.
This coordination creates a unified, constant view of information throughout the cluster. Even when a pod restarts, a node is rescheduled, or the underlying platform shifts workloads, each node commits the identical adjustments in the identical order.
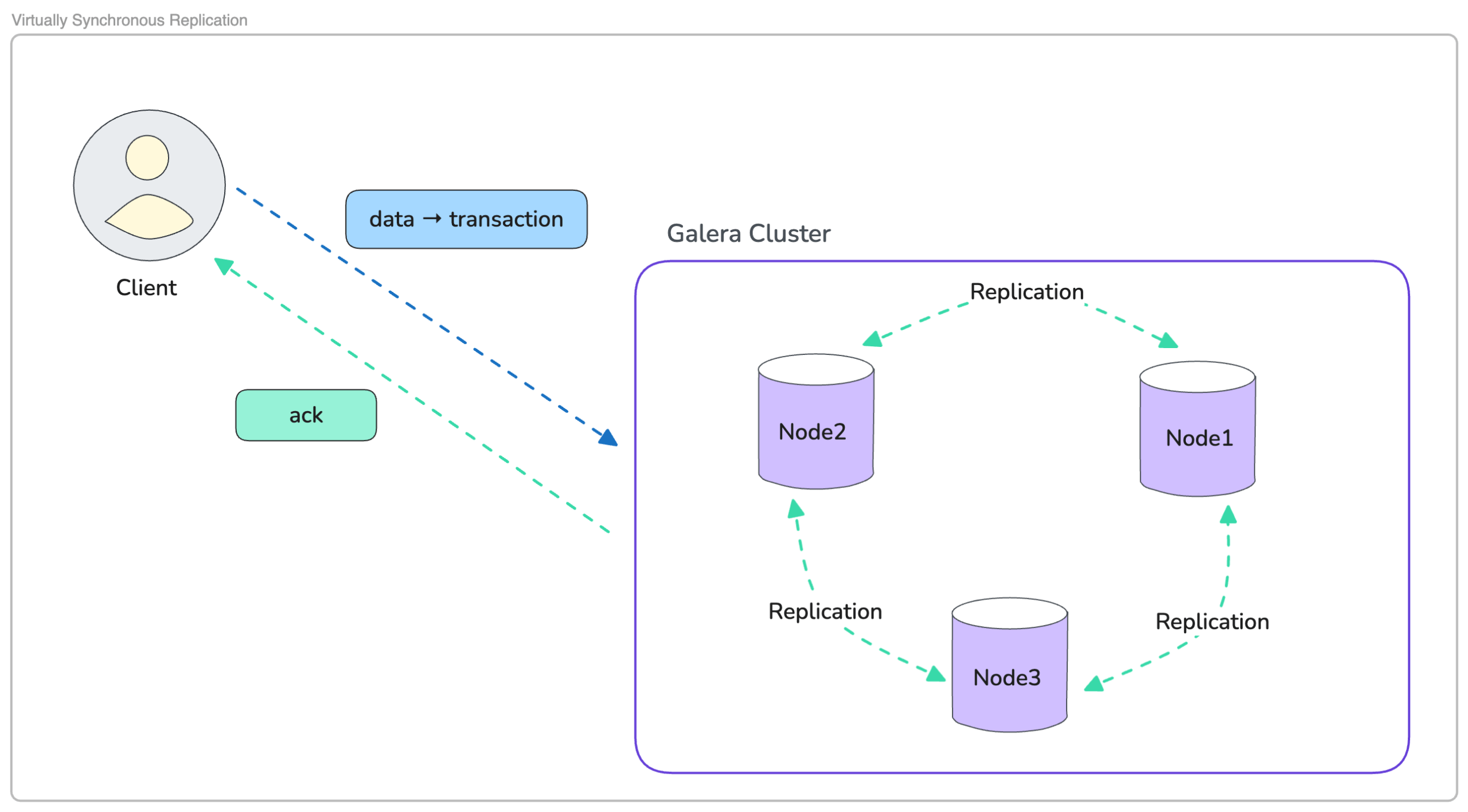
The trade-off is latency; just about synchronous replication relies on the slowest collaborating node. Efficiency can fluctuate with community circumstances or node load. Nonetheless, the profit is powerful sturdiness; as soon as a transaction is acknowledged, it’s safely saved throughout the cluster. This makes just about synchronous replication the popular choice for monetary programs, telecom platforms, reserving engines, and any workload the place correctness is extra vital than uncooked throughput.
Asynchronous Replication (ASYNC)
Asynchronous replication takes a lighter method, engaged on a “commit first, replicate later” mannequin.
When the shopper sends a write, the supply node commits the change instantly and returns an acknowledgement to the applying, even when the replicas haven’t but seen the replace. The replicas obtain the transaction afterwards and apply it on their very own timeline. Their course of doesn’t delay the shopper or decelerate the commit path, which retains write operations quick and predictable. In Kubernetes, this habits works naturally with a platform that continuously shifts workloads round. Writes stay quick even when replicas are catching up or briefly unavailable.
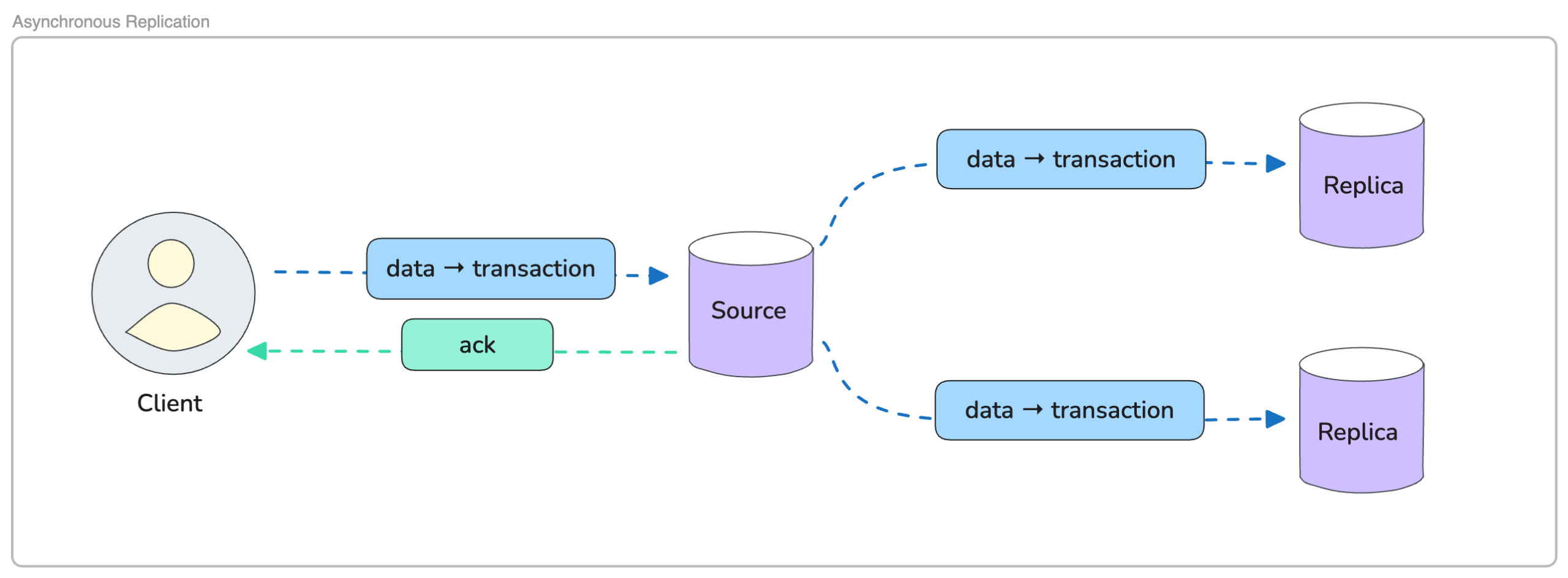
Right here, the trade-off is a variable window of potential information loss if the supply fails earlier than the replicas obtain the newest adjustments. However for a lot of cloud-native purposes, e-commerce websites, reporting dashboards, inner programs, or any workload with out fixed writes, the chance could also be acceptable. Asynchronous replication additionally facilitates scaling reads by including extra replicas, a typical sample in Kubernetes environments.
Why Cloud-Native Replication Behaves In another way
The basics of Nearly SYNC and ASYNC don’t change, however their real-world habits inside Kubernetes does. Rescheduling, storage latency, and community fluctuations can all have an effect on how replication performs in actual time. Kubernetes additionally automates failovers and restoration. This implies replication mode impacts how shortly operators can react, how secure a promoted node is, and the way MySQL behaves throughout upgrades or disruptions
In cloud-native environments, replication turns into an infrastructure determination as a lot as a database determination, for instance, when clusters span a number of availability zones, areas, and even a number of clouds, and the workload relies on particular storage or community paths. All of those infrastructure decisions affect how Nearly SYNC and ASYNC replication behave in observe.
Selecting the Proper Method
In case your workload requires robust consistency and can’t lose information, Nearly SYNC is the best alternative. If efficiency is the precedence or the workload tolerates a slight replication lag, ASYNC could supply higher flexibility. In Kubernetes, each replication sorts have distinct behaviors, and each are legitimate, relying on the applying’s wants.
As organisations modernise their infrastructure and transfer to MySQL in Kubernetes, having the liberty to decide on between Nearly SYNC and ASYNC turns into important. Groups want the flexibleness to align replication habits with their enterprise targets and their cloud-native structure.
What Comes Subsequent
MySQL right this moment offers two broad replication paths: Galera-based just about synchronous replication and native MySQL replication (which incorporates asynchronous replication and Group Replication). Each are extensively used, and every gives completely different strengths. Percona now gives operators that help each replication fashions, permitting customers to decide on the tactic that most closely fits their workload.
For instance, the PXC operator offers just about synchronous Galera-based replication, whereas the brand new Percona Operator for MySQL brings native MySQL replication, together with async (tech preview) and Group Replication.
This weblog submit is supposed to shut that information hole. Not too long ago, we introduced an vital milestone for MySQL customers working on Kubernetes: Native MySQL replication into cloud-native environments by the Percona Operator for MySQL. Learn our announcement: Introducing the GA Launch of the New Percona Operator for MySQL: Extra Replication Choices on Kubernetes.
Understanding Nearly Synchronous and Asynchronous replication now will make it simpler to understand what’s new, why it’s important for the neighborhood, and the way it advantages groups constructing resilient MySQL environments in Kubernetes.
Do you might have questions, concepts, or suggestions about MySQL replication on Kubernetes?
Wish to discover the operator, contribute, or comply with improvement? Go to the open supply Percona Operator for MySQL repository on GitHub
- Collectively, we will proceed enhancing the MySQL expertise for everybody within the open supply neighborhood.
In regards to the Authors
 Edith Puclla
Edith PucllaEdith Puclla is a Expertise Evangelist at Percona Company, a CNCF Ambassador, an open supply contributor with a background in DevOps, and a Docker and Kubernetes fanatic.
 Marco Tusa
Marco TusaMarco Tusa had his personal worldwide observe for the previous twenty eight years. His expertise and experience are in all kinds of knowledge know-how and knowledge administration fields, cowl analysis, improvement, evaluation, high quality management, mission administration and crew administration. Marco is at present working at Percona as Excessive Availability Follow Supervisor, beforehand working at Percona as supervisor of the Consulting Fast Response Group on October 2013. He has being working as worker for the SUN Microsystems as MySQL Skilled Service supervisor for South Europe., and beforehand in MySQL AB. He has labored with the Meals and Agriculture Group of the United Nation since 1994, main the event of the Group’s hyper textual setting.Group chief for the FAO company database help. For a number of years he has led the event group within the WAICENT/Faoinfo crew. He has assisted in defining the Group’s pointers for the dissemination of knowledge from the know-how and the administration standpoint. He has participated in discipline missions with the intention to carry out evaluation, opinions and analysis of the standing of native initiatives, offering native help and recommendation. He had collaborates with MIT Media Lab (Massachusetts Institute of Expertise laboratory) and FAO as Sustainable Data Expertise for creating nations Specialist in relation with the FAO’s Particular Program for Meals Safety for Senegal.