

{kind=link}
AI brokers require persistent reminiscence to take care of context, be taught from previous interactions, and supply constant responses over time. Think about a customer support AI agent deployed at a big ecommerce firm. With out long-term reminiscence, the agent would wish to ask clients to repeat their order numbers, transport preferences, and previous points in each dialog. This creates a irritating expertise the place clients really feel unrecognized and have to continually present context. With long-term reminiscence, the agent can recall earlier interactions, perceive buyer preferences, and preserve context throughout a number of help periods, even when conversations span a number of days or even weeks.
With the Letta Developer Platform, you’ll be able to create stateful brokers with built-in context administration (compaction, context rewriting, and context offloading) and persistence. Utilizing the Letta API, you’ll be able to create brokers which are long-lived or obtain complicated duties with out worrying about context overflow or mannequin lock-in. You possibly can self-host the Letta API in your personal digital personal cloud (VPC) and persist agent state in Amazon Aurora PostgreSQL-Suitable Version. Letta persists all state, together with recollections, instruments, and messages, in normalized tables, so you’ll be able to question information throughout brokers and port state throughout completely different mannequin suppliers.
On this submit, we information you thru establishing Amazon Aurora Serverless as a scalable, extremely accessible PostgreSQL database repository for storing Letta long-term reminiscence. We present create an Aurora cluster within the cloud, configure Letta to hook up with it, and deploy brokers that persist their reminiscence to Aurora. We additionally discover question the database on to view agent state.
Answer overview
Letta runs in a Docker™ container in your native machine and connects to Aurora PostgreSQL over the web. Aurora shops agent configuration, reminiscence, and dialog historical past in PostgreSQL tables. The connection makes use of customary PostgreSQL wire protocol on port 5432.
The next diagram illustrates this structure.
Aurora PostgreSQL
The combination of Aurora PostgreSQL brings a number of capabilities wanted for production-ready AI agent reminiscence programs. Aurora PostgreSQL helps the pgvector extension, enabling environment friendly similarity searches throughout hundreds of thousands of vector embeddings, that are the numerical illustration of previous conversations. This enables AI brokers to shortly retrieve contextually related data.
Aurora PostgreSQL delivers sub-second question latency for reminiscence lookups and helps as much as 15 learn replicas to scale reminiscence retrieval operations effectively. This implies your AI brokers can entry their reminiscence quickly, even beneath heavy masses. The database’s storage capability extends as much as 256 TB, offering ample house for in depth reminiscence archives and long-term dialog historical past.
Aurora gives reliability via its complete sturdiness options. The database maintains six-way replication throughout three Availability Zones, decreasing the danger of information loss. Your brokers’ recollections are additional protected by point-in-time restoration capabilities with as much as 35 days of backup retention. The self-healing storage system constantly performs information integrity checks, sustaining the consistency of your brokers’ reminiscence states.
For value optimization, Aurora Serverless robotically scales primarily based on workload, dealing with 1000’s of concurrent agent connections. Storage scaling can be dynamic, rising from 10 GiB to 256 TB with no downtime, so your brokers don’t run out of reminiscence house as they be taught and work together.
Letta
Letta treats brokers as persistent companies, sustaining state server-side and enabling brokers to run independently, talk with one another, and proceed processing when purchasers are offline. For manufacturing workloads, Letta helps horizontal scaling utilizing Kubernetes, with configurable employee processes and database connection pooling. The background execution mode permits resumable streams that survive disconnects and permit load balancing by selecting up streams began by different situations.
Manufacturing deployments help multi-tenancy with limitless brokers on Professional and Enterprise plans, making Letta appropriate for large-scale customer support and multi-user functions. The platform consists of enterprise options like SAML/OIDC SSO, role-based entry management, and gear sandboxing, with telemetry and efficiency monitoring for monitoring system metrics. Though this submit demonstrates a neighborhood setup, manufacturing deployments usually use cloud platforms with HTTPS entry and safety controls.
Walkthrough overview
Within the following sections, we stroll via the steps to construct the next assets:
- An Aurora serverless cluster with the pgvector extension for embedding storage
- A safety group configuration that permits your IP tackle to attach on port 5432
- A Letta Docker container configured with
LETTA_PG_URIpointing to Aurora - Working AI brokers that persist all state to Aurora as an alternative
Our resolution makes use of Aurora Serverless with minimal capability settings appropriate for growth and testing environments.
Though we’re utilizing an internet-exposed database for this submit for simplicity, the very best follow in manufacturing is to put it in a personal subnet with a safety group that solely permits connections out of your software.
Stipulations
Earlier than we start, ensure you have the next:
Arrange Aurora Serverless
On this part, we show create an Aurora PostgreSQL cluster configured for exterior entry out of your native machine.
Create the Aurora cluster
To create the Aurora cluster, full the next steps:
- On the Amazon RDS console, within the navigation pane, select Databases.
- Select Create database.
- For Engine choices, choose Aurora (PostgreSQL Suitable).
- For Engine model, choose Aurora PostgreSQL (Suitable with PostgreSQL 17.4).
That is the default for main model 17, or you’ll be able to select your most popular model. - Below Templates, choose Dev/Take a look at to optimize for decrease prices.
- Below Settings, configure the next:
- For DB cluster identifier, enter a reputation, reminiscent of
letta-aurora-cluster. - For Grasp username, preserve the default (
postgres). - For Credentials administration, select Self managed.
- For Grasp password, enter an alphanumeric password.
- For DB cluster identifier, enter a reputation, reminiscent of
- Below Occasion configuration, choose Serverless v2.
- For Capability vary, set the next:
- Minimal capability (ACUs): 0.5
- Most capability (ACUs): 1
Aurora Capability Items (ACUs) are the measurement unit for database compute capability in Aurora Serverless. Every ACU is a mix of roughly 2 GiB of reminiscence, corresponding CPU, and networking capabilities. For instance, 0.5 ACUs gives 1 GiB of reminiscence, whereas 32 ACUs gives 64 GiB of reminiscence with proportional compute assets. Your Aurora database prices are primarily based on the ACU utilization per second. For growth and testing, beginning with 0.5–1 ACU is adequate. Manufacturing workloads usually require larger ACU ranges primarily based in your software’s reminiscence and processing wants. Aurora Serverless robotically adjusts capability inside your specified ACU vary primarily based on precise database load. Aurora can scale to a minimal capability of zero ACUs, which avoids compute prices in durations the place your cluster shouldn’t be getting used.
- Below Connectivity, configure the next:
- For Public entry, select Sure.
- For VPC safety group (firewall), choose Create new.
- For New VPC safety group title, enter a reputation, reminiscent of
letta-aurora-sg.
- Select Create database.
Whereas Aurora creates the cluster, you’ll be able to proceed to configure the safety group.
Configure safety group entry
Aurora clusters require safety group configuration to permit exterior connections. By default, the safety group blocks all incoming site visitors. This resolution creates an Amazon Elastic Compute Cloud (Amazon EC2) safety group.
To configure the safety group, full the next steps:
- On the Amazon EC2 console, within the navigation pane, beneath Community & Safety, select Safety Teams.
- On the Inbound guidelines tab, choose the safety group connected to your Aurora cluster (
letta-aurora-sg). - Select Edit inbound guidelines.
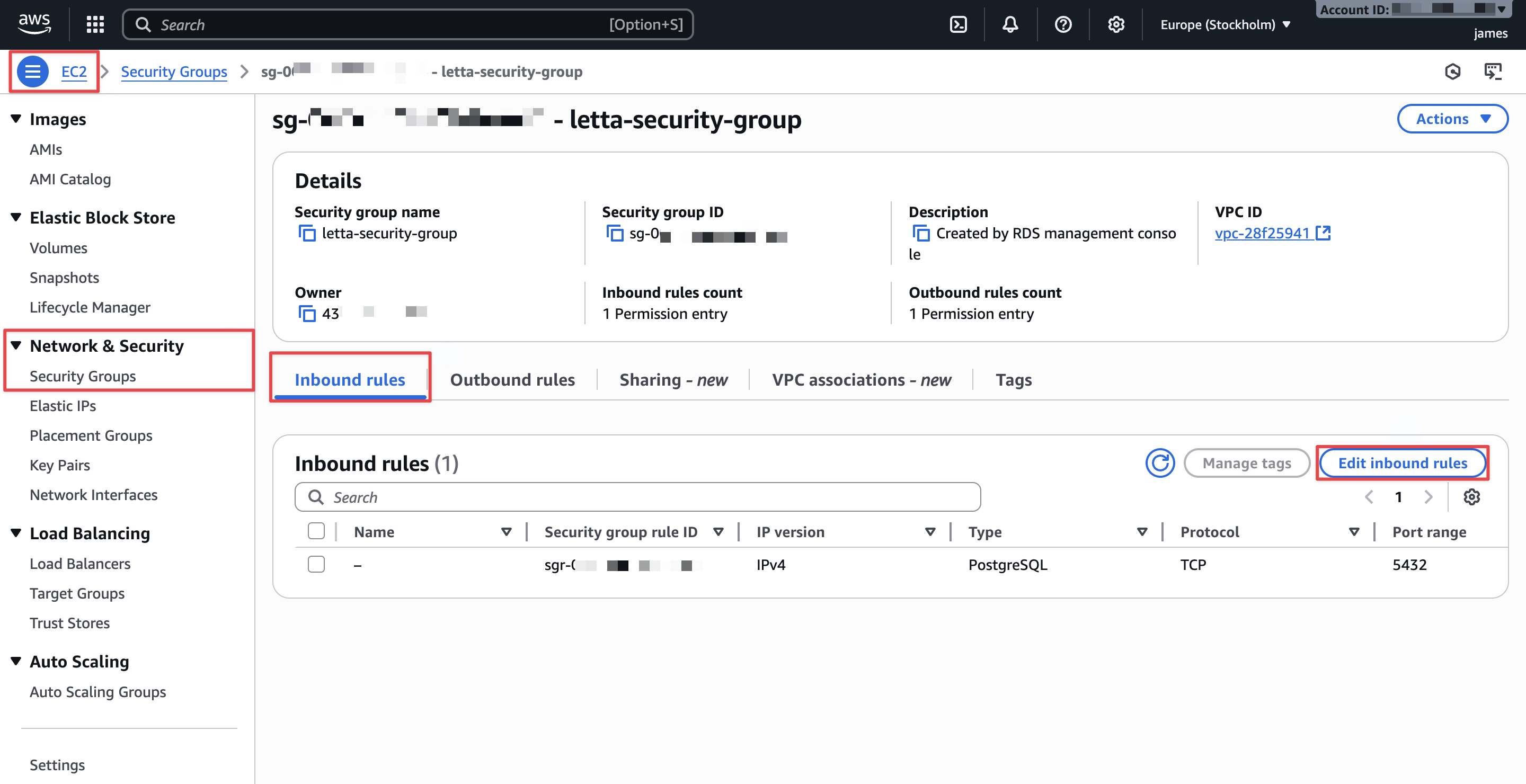
- Select Add rule and configure the next:
- For Sort, select PostgreSQL.
- For Protocol, preserve at default (TCP).
- For Port vary, preserve at default (5432).
- For Supply, select one of many following choices:
- My IP: Robotically detects and permits your present IP tackle (really useful for testing).
- Customized: Enter a particular IP tackle with
/32suffix for single IP entry.
- Select Save guidelines.
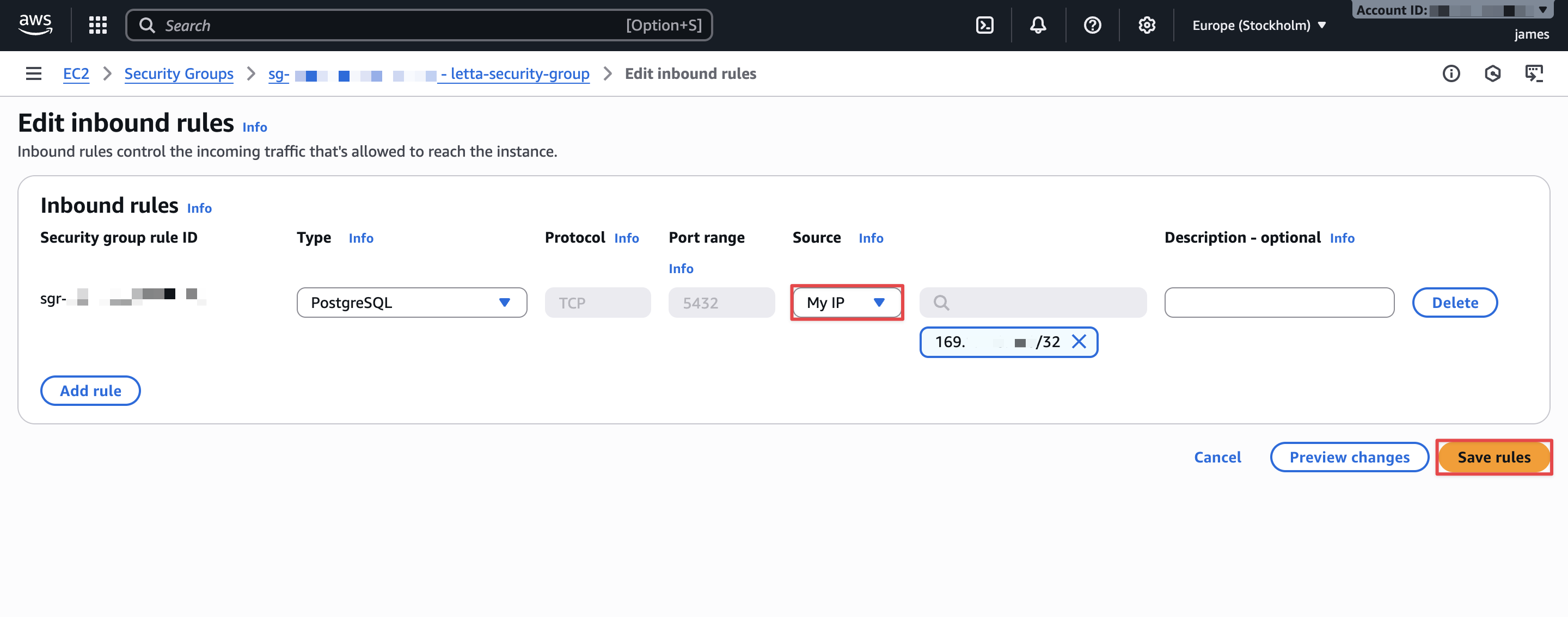
Your safety configuration now permits PostgreSQL connections out of your IP tackle to the Aurora cluster.
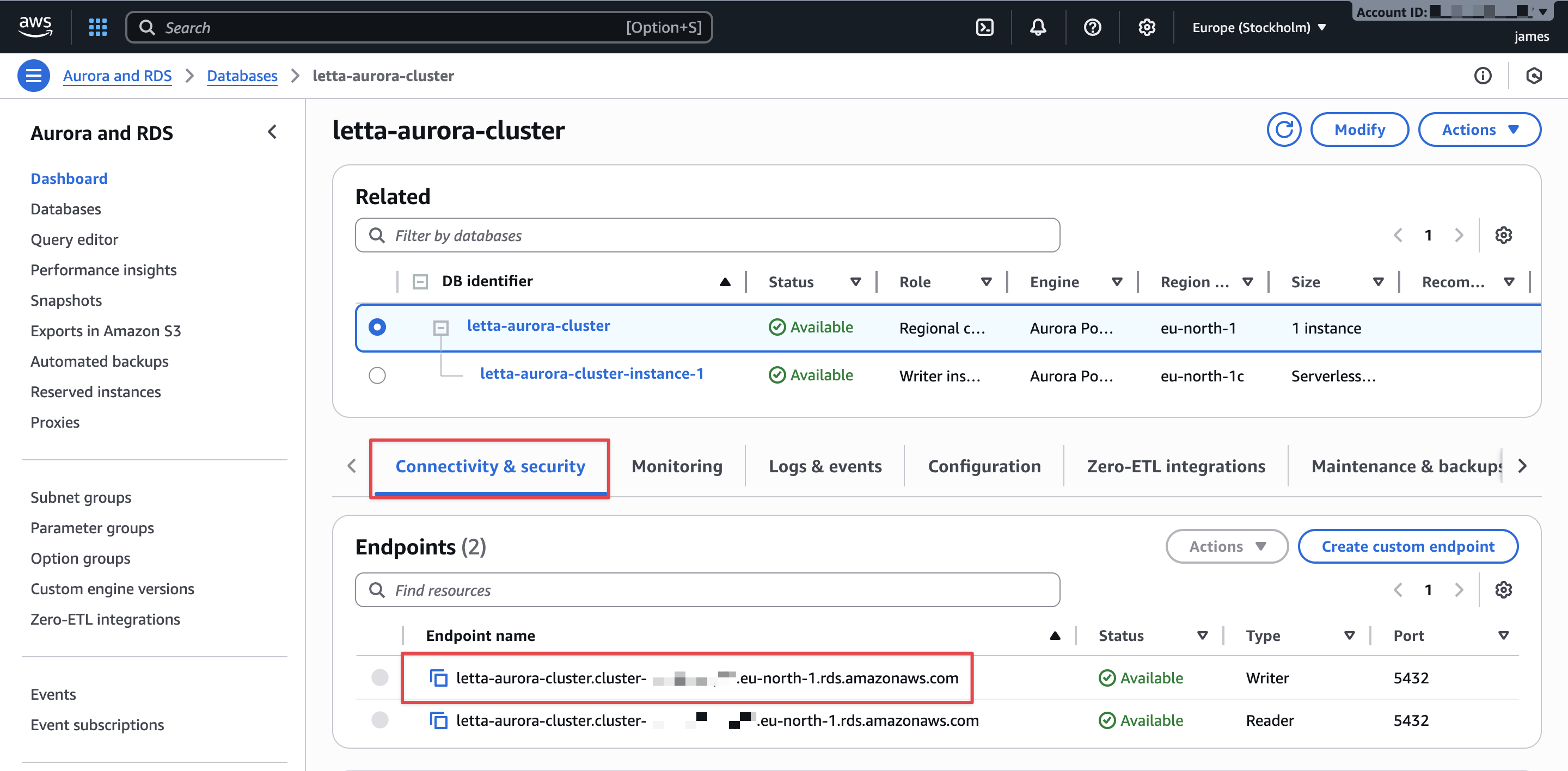
Retrieve cluster endpoint
After the cluster standing reveals as Accessible, retrieve the connection endpoint:
- On the Amazon RDS console, select Databases within the navigation pane.
- Select your cluster.
- On the Connectivity & safety tab, go to the Endpoints part.
- Copy the author occasion endpoint. It appears to be like much like
letta-aurora-cluster.cluster-abc123def456.us-east-1.rds.amazonaws.com. You’ll use this endpoint to assemble the PostgreSQL connection string.
Set up pgvector extension
Letta makes use of the pgvector extension to retailer vector embeddings for agent reminiscence. You have to manually allow this extension earlier than connecting Letta.
To put in pgvector, full the next steps:
- Connect with Aurora utilizing the psql command line device:
- When prompted, enter the first password you configured throughout cluster creation.
After profitable connection, you will notice the PostgreSQL immediate: - Create the pgvector extension:
- Confirm the set up:
- Exit psql:
Your Aurora cluster is now prepared for Letta connections.
Join Letta to Aurora
With Aurora configured, now you can run Letta and join it to your cluster utilizing the LETTA_PG_URI setting variable. Letta’s Docker picture robotically detects the exterior PostgreSQL connection and runs database migrations on startup.
Assemble connection string
The LETTA_PG_URI follows the usual PostgreSQL connection string format:
Utilizing the values out of your Aurora cluster, assemble the string as follows:
Exchange the endpoint and password together with your precise cluster endpoint and password.
Run Letta with Docker
To start out Letta related to Aurora, run the Docker container together with your Aurora connection string and OpenAI API key:
Present your Aurora main password, your cluster endpoint, and your OpenAI key.
Look ahead to the migration output. You must see the next:
This confirms Letta detected the PostgreSQL connection and created the required database schema.
Once you see the next output, the server is prepared:
Letta is now operating and related to Aurora. Agent information will persist to your Aurora cluster as an alternative of native storage.
Create and check an agent
To confirm the connection works, create an agent and ship it a message. Select both Python or TypeScript primarily based in your most popular language.
Utilizing Python
With Python, full the next steps:
- In a brand new terminal, create a Python digital setting and set up the Letta Python shopper:
- Create a Python script referred to as
test_aurora_agent.py: - Run the script:
You must see output much like the next code:
Utilizing TypeScript
With TypeScript, full the next steps:
- Initialize a Node.js mission and set up dependencies:
- Replace your package deal.json to make use of ES modules by including the next:
- Create a TypeScript script referred to as
test_aurora_agent.ts:You may see validation warnings about
tool_return_messagewhen operating this script. These are inner SDK sort validation messages. The warnings don’t have an effect on performance. To suppress these warnings,redirect stderr: npx tsx test_aurora_agent.ts 2>/dev/null. - Run the script:
You must see output much like the next code:
The agent response confirms that Letta efficiently created an agent and processed your message. This information is now saved in Aurora.
View agent state in Aurora
Now that you’ve got brokers operating and storing information in Aurora, you’ll be able to join on to the database to examine how Letta organizes agent state, reminiscence, and conversations.
Connect with Aurora
Utilizing the identical psql connection from earlier, connect with Aurora:
Discover the database schema
Letta creates 42 tables to handle brokers, reminiscence, messages, and related metadata. To view all tables, use the next command:
You must see output displaying tables together with brokers, messages, organizations, customers, block, sources, and different particulars:
The important thing tables for understanding agent state are:
- brokers – Shops agent configuration and metadata
- messages – Comprises all dialog messages with full content material as JSON
- organizations and customers – Manages multi-tenant entry management
- block and block_history – Shops reminiscence blocks and their revision historical past
- sources and source_passages – Comprises information sources and their embeddings for retrieval
View agent data
To see all brokers in your database, use the next code:
View agent messages
To see the dialog historical past for a particular agent, use the content material column, which shops messages as JSON (the textual content column is empty in present Letta variations):
The next is an instance of the output:
The messages table stores the complete conversation flow as JSON, so you can trace exactly how agents process and respond to user input.
Examine message content structure
Letta stores message content as JSON. To view the detailed structure of an assistant message, use the following code:
The following is an example of the output:
This reveals the JSON construction of assistant messages. Every message is saved as an array of content material objects with sort, textual content, and non-obligatory signature fields. System messages include the complete agent directions together with reminiscence blocks, and assistant and person messages include the dialog content material.
Understanding the schema for embeddings and information sources
Letta makes use of the pgvector extension to retailer embedding vectors for semantic reminiscence search and Retrieval Augmented Technology (RAG). The database consists of tables particularly designed for vector storage:
For a newly created agent with fundamental dialog historical past, each tables will present 0 information. These tables are populated whenever you take the next actions:
- Connect paperwork or information to an agent as information sources
- Use archival reminiscence options for long-term storage
- Implement RAG workflows
The source_passages desk shops embeddings for exterior information sources, and archival_passages shops embeddings for the agent’s archival reminiscence system. Each use pgvector’s vector information sort for environment friendly similarity search.
Clear up
Once you’ve completed exploring the mixing, delete the Aurora cluster and related assets to keep away from ongoing prices.
Delete the Aurora cluster
To delete your Aurora cluster, full the next steps:
- On the Amazon RDS console, within the navigation pane, select Databases.
- Choose your database inside the cluster (reminiscent of
letta-aurora-cluster-instance-1). - Select Actions, then select Delete.
- Enter
delete mewithin the affirmation discipline. - After the occasion is deleted, you’ll be able to delete the cluster.
- For Create last snapshot, select No (this can be a check setting).
- Enter
delete mewithin the affirmation discipline. - Select Delete.
The deletion course of takes a number of minutes.
Delete the safety group
After the cluster is deleted, full the next steps to delete the safety group:
- On the Amazon EC2 console, within the navigation pane, select Safety Teams.
- Choose the safety group you created (reminiscent of
letta-aurora-sg). - Select Actions, then select Delete safety teams.
- Select Delete.
Conclusion
On this submit, you configured Letta to make use of Aurora PostgreSQL as a managed database backend. You created an Aurora Serverless cluster, configured safety group entry, put in the pgvector extension, and related Letta utilizing the LETTA_PG_URI setting variable. You then created AI brokers that persist their state to Aurora and queried the database to view agent conversations and reminiscence.
This integration permits manufacturing deployments of Letta with the scalability, sturdiness, and excessive availability that Aurora gives. For manufacturing use, take into account implementing further safety measures reminiscent of AWS Id and Entry Administration (IAM) database authentication, encryption at relaxation, and limiting safety group entry to particular IP ranges or VPC configurations.
To be taught extra about Letta, seek advice from the Letta documentation guides. For extra details about Aurora PostgreSQL, see Working with Amazon Aurora PostgreSQL.
In regards to the authors