

{kind=link}
Once you’re working with information evaluation, you usually face the problem of successfully correlating real-time information with historic information to realize actionable insights. This turns into significantly crucial if you’re coping with eventualities like e-commerce order processing, the place your real-time choices can considerably affect enterprise outcomes. The complexity arises when it’s worthwhile to mix streaming information with static reference info to create a complete analytical framework that helps each your speedy operational wants and strategic planning
To deal with this problem, you’ll be able to make use of stream processing applied sciences that deal with steady information flows whereas seamlessly integrating dwell information streams with static dimension tables. These options allow you to carry out detailed evaluation and aggregation of knowledge, supplying you with a complete view that mixes the immediacy of real-time information with the depth of historic context. Apache Flink has emerged as a number one stream computing platform that provides strong capabilities for becoming a member of real-time and offline information sources via its intensive connector ecosystem and SQL API.
On this submit, we present you implement real-time information correlation utilizing Apache Flink to hitch streaming order information with historic buyer and product info, enabling you to make knowledgeable choices based mostly on complete, up-to-date analytics.
We additionally introduce an optimized answer to robotically load Hive dimension desk information into Alluxio Common Flash Storage (UFS) via the Alluxio cache layer. This allows Flink to carry out temporal joins on altering information, precisely reflecting the content material of a desk at particular time limits.
Answer structure
In relation to becoming a member of Flink SQL tables with stream tables, the lookup be a part of is a go-to technique. This method is especially efficient when it’s worthwhile to correlate streaming information with static or slowly altering information. In Flink, you should use connectors just like the Flink Hive SQL connector or the FileSystem connector to archive the situation.
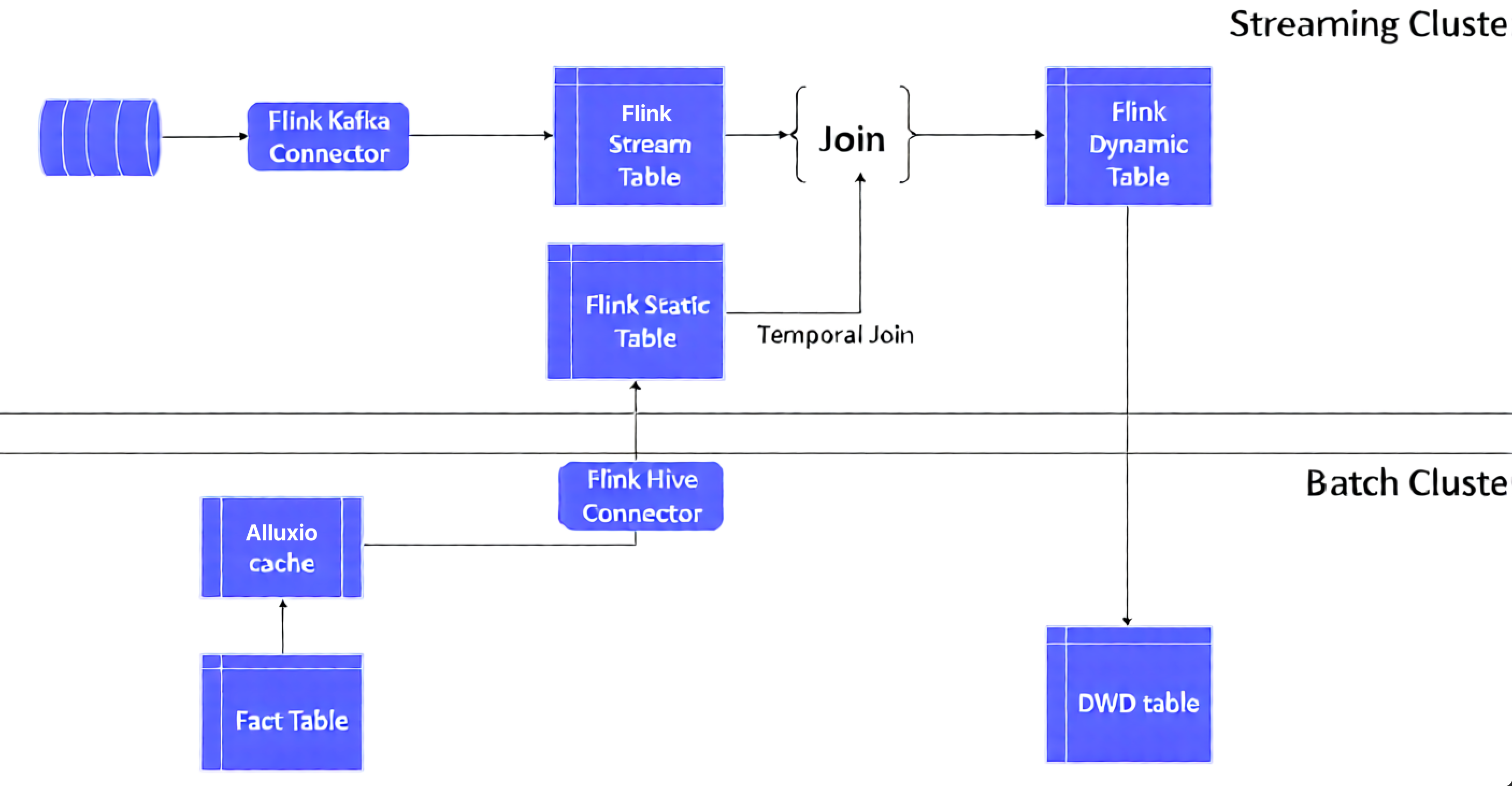
The next structure reveals normal method which we describe forward:
Right here’s how we do that:
- We use offline information to assemble a Flink desk. This information may very well be from an offline Hive database desk or from recordsdata saved in a system like Amazon S3. Concurrently, we are able to create a stream desk from the info flowing in via a Kafka message stream
- Use a batch cluster for offline information processing. On this instance, we use an Amazon EMR cluster which creates a reality desk in it. It additionally gives a Element Large Information (DWD) desk which has been used as a Flink dynamic desk to carry out consequence processing after a lookup be a part of
- It’s usually situated within the center layer of an information warehouse, between the uncooked information contained within the Operational Information Retailer (ODS) and the extremely aggregated information discovered within the Information Warehouse (DW), or Information Mart (DM).
- The first objective of the DWD layer is to assist advanced information evaluation and reporting wants by offering an in depth and complete information view.
- Each the actual fact desk and DWD desk are hive tables on Hadoop
- Use a streaming cluster for the real-time processing. On this instance, we use an Amazon EMR cluster to stream occasion ingestion and analyze it utilizing Flink, utilizing Flink Kafka connector and Hive connector to hitch the streaming occasion information and statics dimension information (reality desk)
One of many key challenges encountered with this method is said to the administration of the lookup dimension desk information. Initially, when the Flink software is began, this information is saved within the activity supervisor’s state. Nevertheless, throughout subsequent operations like steady queries or window aggregations, the dimension desk information isn’t robotically refreshed. Which means that the operator should both restart the Flink software periodically or manually refresh the dimension desk information within the momentary desk. This step is essential to make sure that the be a part of operations and aggregations are all the time carried out with probably the most present dimension information.

One other important problem with this method is needing to drag the complete dimension desk information and carry out a chilly begin every time. This turns into significantly problematic when coping with a big quantity of dimension desk information. As an illustration, when dealing with tables with tens of tens of millions of registered customers or tens of 1000’s of product SKU attributes, this course of generates substantial enter/output (IO) overhead. Consequently, it results in efficiency bottlenecks, impacting the effectivity of the system.
Flink’s checkpointing mechanism processes the info and shops checkpoint snapshots of all of the states throughout steady queries or window aggregations, leading to state snapshots information bloat.
Optimizing the answer
This submit contains an optimized answer to handle the aforementioned challenges, by robotically loading Hive dimension desk information into the Alluxio UFS through the Alluxio cache layer. We be a part of this information with Flink’s temporal joins to create a view on a altering desk. This view displays the content material of a desk at a particular time limit
Alluxio is a distributed cache engine for large information expertise stacks. It gives a unified UFS that may hook up with the underlying Amazon S3 and HDFS information. Alluxio UFS learn and write operations heat up the distributed storage layers on S3 and HDFS and thus considerably improve throughput and lowering community overhead. Deeply built-in with higher degree computing engines akin to Hive, Spark, and Trino, Alluxio is a wonderful cache accelerator for offline dimension information.
Moreover, we make the most of Flink’s temporal desk perform to cross a time parameter. This perform returns a view of the temporal desk on the specified time. By doing so, when the principle desk of the real-time dynamic desk is correlated with the temporal desk, it may be related to a particular historic model of the dimension information
Answer implementation particulars
For this submit, we use “person habits” log information in Kafka as real-time stream reality desk information, and person info information on Hive as offline dimension desk information. A demo with Alluxio + Flink temporal be a part of is used to confirm the Flink be a part of optimized answer.
Actual-time reality tables
For this demonstration, we make the most of person habits JSON information simulated by the open-source element json-data-generator. We write the info to Amazon Managed Kafka (Amazon MSK) in real-time. Utilizing the Flink Kafka Connector, we convert this stream right into a Flink stream desk for steady queries. This served as our reality desk information for real-time joins.
A pattern of the person habits simulation information in JSON format is as follows:
It contains person habits info akin to operation time, login system, person signature, behavioral actions, and repair objects, areas, and associated textual content fields. We create a reality desk in Flink SQL with the principle fields as follows:
Caching dimension tables with Alluxio
Amazon EMR gives strong integration with Alluxio. You should utilize the Amazon EMR bootstrap startup script to robotically deploy Alluxio parts and begin the Alluxio grasp and employee processes when an Amazon EMR cluster is created. For detailed set up and deployment steps, seek advice from the article Integrating Alluxio on Amazon EMR.
In an Amazon EMR cluster that integrates Alluxio, it’s possible you’ll use Alluxio to create a cache desk for the Hive offline dimension desk as follows:
As proven within the earlier part, the Alluxio desk location alluxio://ip-xxx-xx:19998/s3/buyer factors to the S3 path the place the Hive dimension desk is situated; writing to the client dimension desk is robotically synchronized to the Alluxio cache.
After creating the Alluxio Hive offline dimension desk, you’ll be able to view the small print of the Alluxio cache desk by connecting to the Hive metadata via the Hive catalog in Flink SQL:
As proven within the previous code, the placement path of the dimension desk is the UFS cache path Uniform Useful resource Identifier (URI). When the enterprise program reads and writes the dimension desk, Alluxio robotically updates the client dimension desk information within the cache and asynchronously writes it to the Alluxio backend storage path of the S3 desk to realize desk information synchronization within the information lake.
Flink temporal desk be a part of
Flink temporal desk can be a sort of dynamic desk. Every document within the temporal desk is correlated with a number of time fields. Once we be a part of the actual fact desk and the dimension desk, we often have to get hold of real-time dimension desk information for the lookup be a part of. Thus, when creating or becoming a member of a desk, we often want to make use of the proctime() perform to specify the time subject of the actual fact desk. Once we be a part of the tables, we use the syntax of FOR SYSTEM_TIME AS OF to specify the time model of the actual fact desk that corresponds to the time of the lookup dimension desk.
For this submit, the client info is a altering dimension desk within the Hive offline desk, whereas the client habits is the actual fact desk in Kafka. We specified the time subject with proctime() within the Flink Kafka supply desk. Then when becoming a member of the Flink Hive desk, we used FOR SYSTEM_TIME AS OF to specify the time subject of the lookup Kafka supply desk to permit us to comprehend the Flink temporal desk be a part of operation
As proven within the following code, a reality desk of person habits is created via the Kafka Connector in Flink SQL. The ts subject refers back to the timestamp when the temporal desk is joined:
The Flink offline dimension desk and the streaming real-time desk are joined as follows:
When the actual fact desk logevent_source joins the lookup dimension desk, the proctime perform ensures real-time joins by acquiring the newest dimension desk model. This dimension information, cached in Alluxio, delivers considerably higher learn efficiency than direct S3 entry.
On the identical time, the dimension desk information is already cached in Alluxio; the learn efficiency is a lot better than offline information learn on S3.
The comparability take a look at reveals that Alluxio cache brings a transparent efficiency benefit by switching the S3 and Alluxio paths of the client dimension desk via Hive
You’ll be able to simply swap the native and cache location paths with alter desk in hive cli:
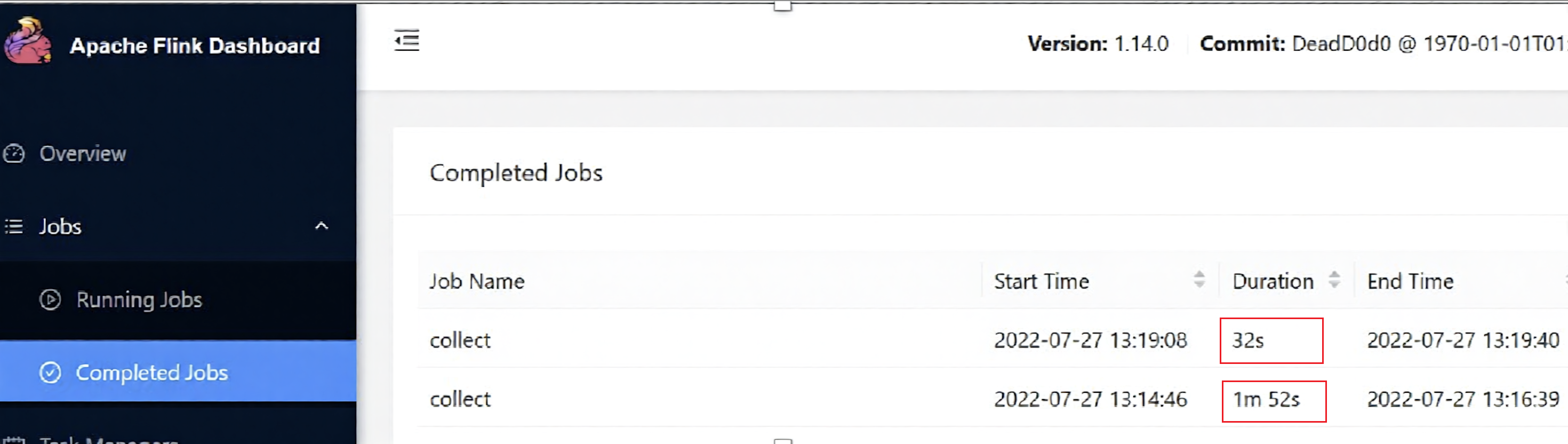
You may also choose the Process Supervisor log from the Flink dashboard for a cut up take a look at.
The efficiency of the actual fact desk load was doubled via the implementation of optimized information processing methods.
- Earlier than caching (S3 path learn): 5s load time
- After caching (Alluxio learn): 2s load time
The timeline on JobManager clearly reveals the distinction in execution length beneath Alluxio and S3 paths.
For single activity question ,we speed up by greater than 1 instances utilizing this answer. The general job efficiency enchancment is much more seen.
Different optimalizations to contemplate
Implementing a steady be a part of requires pulling dimension information each time. Does it result in Flink’s checkpoint state bloat that may trigger Flink TaskManager RocksDB to blow up or reminiscence overflow.
In Flink, the state comes with a TTL mechanism. You’ll be able to set a TTL expiration coverage to set off Flink to scrub up expired state information. Flink SQL may be set utilizing the trace technique.
Flink Desk/Streaming API is analogous:
Restart the lookup be a part of after the configuration. As you’ll be able to see from the Flink TM log, after TTL expires, it triggers clean-up and re-pull the Hive dimension desk information:
As well as, you’ll be able to cut back the variety of checkpoint snapshots by configuring Flink state retention and thereby cut back the quantity of area taken up by state on the time of snapshot.
After the configuration, you’ll be able to see that within the S3 checkpoint path, the Flink job robotically cleans up historic snapshots and retains the newest 5 snapshots, thus making certain that checkpoint snapshots don’t accumulate.
Abstract
Clients implementing Flink streaming framework to hitch dimension and real-time reality tables often encounter efficiency challenges. On this submit, we introduced an optimized answer that makes use of Alluxio’s caching capabilities to robotically load Hive dimension desk information into the UFS cache. By integrating with Flink temporal desk joins, dimension tables are remodeled into time-versioned views, successfully addressing efficiency bottlenecks in conventional implementations.
In regards to the writer