

{kind=link}
Advertising groups face main challenges creating campaigns in at present’s digital surroundings. They need to navigate via advanced knowledge analytics and quickly altering client preferences to supply partaking, personalised content material throughout a number of channels whereas sustaining model consistency and dealing inside tight deadlines. Utilizing generative AI can streamline and speed up the inventive course of whereas sustaining alignment with enterprise targets. Certainly, in keeping with McKinsey’s “The State of AI in 2023” report, 72% of organizations now combine AI into their operations, with advertising rising as a key space of implementation.
Constructing upon our earlier work of advertising marketing campaign picture technology utilizing Amazon Nova basis fashions, on this publish, we exhibit methods to improve picture technology by studying from earlier advertising campaigns. We discover methods to combine Amazon Bedrock, AWS Lambda, and Amazon OpenSearch Serverless to create a sophisticated picture technology system that makes use of reference campaigns to take care of model pointers, ship constant content material, and improve the effectiveness and effectivity of recent marketing campaign creation.
The worth of earlier marketing campaign data
Historic marketing campaign knowledge serves as a strong basis for creating efficient advertising content material. By analyzing efficiency patterns throughout previous campaigns, groups can establish and replicate profitable inventive parts that constantly drive increased engagement charges and conversions. These patterns would possibly embrace particular coloration schemes, picture compositions, or visible storytelling methods that resonate with goal audiences. Earlier marketing campaign belongings additionally function confirmed references for sustaining constant model voice and visible identification throughout channels. This consistency is essential for constructing model recognition and belief, particularly in multi-channel advertising environments the place coherent messaging is important.
On this publish, we discover methods to use historic marketing campaign belongings in advertising content material creation. We enrich reference photos with helpful metadata, together with marketing campaign particulars and AI-generated picture descriptions, and course of them via embedding fashions. By integrating these reference belongings with AI-powered content material technology, advertising groups can rework previous successes into actionable insights for future campaigns. Organizations can use this data-driven method to scale their advertising efforts whereas sustaining high quality and consistency, leading to extra environment friendly useful resource utilization and improved marketing campaign efficiency. We’ll exhibit how this systematic methodology of utilizing earlier marketing campaign knowledge can considerably improve advertising methods and outcomes.
Resolution overview
In our earlier publish, we carried out a advertising marketing campaign picture generator utilizing Amazon Nova Professional and Amazon Nova Canvas. On this publish, we discover methods to improve this resolution by incorporating a reference picture search engine that makes use of historic marketing campaign belongings to enhance technology outcomes. The next structure diagram illustrates the answer:
The principle structure elements are defined within the following record:
- Our system begins with a web-based UI that customers can entry to begin the creation of recent advertising marketing campaign photos. Amazon Cognito handles person authentication and administration, serving to to make sure safe entry to the platform.
- The historic advertising belongings are uploaded to Amazon Easy Storage Service (Amazon S3) to construct a related reference library. This add course of is initiated via Amazon API Gateway. On this publish, we use the publicly obtainable COCO (Frequent Objects in Context) dataset as our supply of reference photos.
- The picture processing AWS Step Capabilities workflow is triggered via API Gateway and processes photos in three steps:
- A Lambda perform (
DescribeImgFunction) makes use of the Amazon Nova Professional mannequin to explain the photographs and establish their key parts. - A Lambda perform (
EmbedImgFunction) transforms the photographs into embeddings utilizing the Amazon Titan Multimodal Embeddings basis mannequin. - A Lambda perform (
IndexDataFunction) shops the reference picture embeddings in an OpenSearch Serverless index, enabling fast similarity searches.
- A Lambda perform (
- This step bridges asset discovery and content material technology. When customers provoke a brand new marketing campaign, a Lambda perform (
GenerateRecommendationsFunction) transforms the marketing campaign necessities into vector embeddings and performs a similarity search within the OpenSearch Serverless index to establish probably the most related reference photos. The descriptions of chosen reference photos are then included into an enhanced immediate via a Lambda perform (GeneratePromptFunction). This immediate powers the creation of recent marketing campaign photos utilizing Amazon Bedrock via a Lambda perform (GenerateNewImagesFunction). For detailed details about the picture technology course of, see our earlier weblog.
Our resolution is accessible in GitHub. To deploy this challenge, observe the directions obtainable within the README file.
Process
On this part, we study the technical elements of our resolution, from reference picture processing via last advertising content material technology.
Analyzing the reference picture dataset
Step one in our AWS Step Capabilities workflow is analyzing reference photos utilizing the Lambda Perform DescribeImgFunction. This useful resource makes use of Amazon Nova Professional 1.0 to generate two key elements for every picture: an in depth description and an inventory of parts current within the picture. These metadata elements might be built-in into our vector database index later and used for creating new marketing campaign visuals.
For implementation particulars, together with the entire immediate template and Lambda perform code, see our GitHub repository. The next is the structured output generated by the perform when introduced with a picture:

Producing reference picture embeddings
The Lambda perform EmbedImgFunction encodes the reference photos into vector representations utilizing the Amazon Titan Multimodal Embeddings mannequin. This mannequin can embed each modalities right into a joint area the place textual content and pictures are represented as numerical vectors in the identical dimensional area. On this unified illustration, semantically related objects (whether or not textual content or photos) are positioned nearer collectively. The mannequin preserves semantic relationships inside and throughout modalities, enabling direct comparisons between any mixture of photos and textual content. This permits highly effective capabilities corresponding to text-based picture search, picture similarity search, and mixed textual content and picture search.
The next code demonstrates the important logic for changing photos into vector embeddings. For the entire implementation of the Lambda perform, see our GitHub repository.
with open(image_path, "rb") as image_file:
input_image = base64.b64encode(image_file.learn()).decode('utf8')
response = bedrock_runtime.invoke_model(
physique=json.dumps({
"inputImage": input_image,
"embeddingConfig": {
"outputEmbeddingLength": dimension
}
}),
modelId=model_id
)
json.masses(response.get("physique").learn())The perform outputs a structured response containing the picture particulars and its embedding vector, as proven within the following instance.
Index reference photos with Amazon Bedrock and OpenSearch Serverless
Our resolution makes use of OpenSearch Serverless to allow environment friendly vector search capabilities for reference photos. This course of includes two principal steps: establishing the search infrastructure after which populating it with reference picture knowledge.
Creation of the search index
Earlier than indexing our reference photos, we have to arrange the suitable search infrastructure. When our stack is deployed, it provisions a vector search assortment in OpenSearch Serverless, which robotically handles scaling and infrastructure administration. Inside this assortment, we create a search index utilizing the Lambda perform CreateOpenSearchIndexFn.
Our index mappings configuration, proven within the following code, defines the vector similarity algorithm and the marketing campaign metadata fields for filtering. We use the Hierarchical Navigable Small World (HNSW) algorithm, offering an optimum stability between search pace and accuracy. The marketing campaign metadata consists of an goal subject that captures marketing campaign objectives (corresponding to clicks, consciousness, or likes) and a node subject that identifies goal audiences (corresponding to followers, prospects, or new prospects). By filtering search outcomes utilizing these fields, we may help be certain that reference photos come from campaigns with matching targets and goal audiences, sustaining alignment in our advertising method.
For the entire implementation particulars, together with index settings and extra configurations, see our GitHub repository.
Indexing reference photos
With our search index in place, we are able to now populate it with reference picture knowledge. The Lambda perform IndexDataFunction handles this course of by connecting to the OpenSearch Serverless index and storing every picture’s vector embedding alongside its metadata (marketing campaign targets, target market, descriptions, and different related data). We are able to use this listed knowledge later to rapidly discover related reference photos when creating new advertising campaigns. Under is a simplified implementation, with the entire code obtainable in our GitHub repository:
# Initialize the OpenSearch shopper
oss_client = OpenSearch(
hosts=[{'host': OSS_HOST, 'port': 443}],
http_auth=AWSV4SignerAuth(boto3.Session().get_credentials(), area, 'aoss'),
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection
)
# Put together doc for indexing
doc = {
"id": image_id,
"node": metadata['node'],
"goal": metadata['objective'],
"image_s3_uri": s3_url,
"image_description": description,
"img_element_list": parts,
"embeddings": embedding_vector
}
# Index doc in OpenSearch
oss_response = oss_client.index(
index=OSS_EMBEDDINGS_INDEX_NAME,
physique=doc
)Combine the search engine into the advertising campaigns picture generator
The picture technology workflow combines marketing campaign necessities with insights from earlier reference photos to create new advertising visuals. The method begins when customers provoke a brand new marketing campaign via the online UI. Customers present three key inputs: a textual content description of their desired marketing campaign, its goal, and its node. Utilizing these inputs, we carry out a vector similarity search in OpenSearch Serverless to establish probably the most related reference photos from our library. For these chosen photos, we retrieve their descriptions (created earlier via Lambda perform DescribeImgFunction) and incorporate them into our immediate engineering course of. The ensuing enhanced immediate serves as the muse for producing new marketing campaign photos that align with each: the person’s necessities and profitable reference examples. Let’s study every step of this course of intimately.
Get picture suggestions
When a person defines a brand new marketing campaign description, the Lambda perform GetRecommendationsFunction transforms it right into a vector embedding utilizing the Amazon Titan Multimodal Embeddings mannequin. By reworking the marketing campaign description into the identical vector area as our picture library, we are able to carry out exact similarity searches and establish reference photos that carefully align with the marketing campaign’s targets and visible necessities.
The Lambda perform configures the search parameters, together with the variety of outcomes to retrieve and the ok worth for the k-NN algorithm. In our pattern implementation, we set ok to 5, retrieving the highest 5 most related photos. These parameters might be adjusted to stability outcome variety and relevance.
To assist guarantee contextual relevance, we apply filters to match each the node (target market) and goal of the brand new marketing campaign. This method ensures that advisable photos aren’t solely visually related but additionally aligned with the marketing campaign’s particular objectives and target market. We showcase a simplified implementation of our search question, with the entire code obtainable in our GitHub repository.
physique = {
"measurement": ok,
"_source": {"exclude": ["embeddings"]},
"question":
{
"knn":
{
"embeddings": {
"vector": embedding,
"ok": ok,
}
}
},
"post_filter": {
"bool": {
"filter": [
{"term": {"node": node}},
{"term": {"objective": objective}}
]
}
}
}
res = oss_client.search(index=OSS_EMBEDDINGS_INDEX_NAME, physique=physique)The perform processes the search outcomes, that are saved in Amazon DynamoDB to take care of a persistent report of campaign-image associations for environment friendly retrieval. Customers can entry these suggestions via the UI and choose which reference photos to make use of for his or her new marketing campaign creation.
Enhancing the meta-prompting approach with reference photos
The immediate technology part builds upon our meta-prompting approach launched in our earlier weblog. Whereas sustaining the identical method with Amazon Nova Professional 1.0, we now improve the method by incorporating descriptions from user-selected reference photos. These descriptions are built-in into the template immediate utilizing XML tags (, as proven within the following instance.
The immediate technology is orchestrated by the Lambda perform GeneratePromptFunction. The perform receives the marketing campaign ID and the URLs of chosen reference photos, retrieves their descriptions from DynamoDB, and makes use of Amazon Nova Professional 1.0 to create an optimized immediate from the earlier template. This immediate is used within the subsequent picture technology part. The code implementation of the Lambda perform is accessible in our GitHub repository.
Picture technology
After acquiring reference photos and producing an enhanced immediate, we use the Lambda perform GenerateNewImagesFunction to create the brand new marketing campaign picture. This perform makes use of Amazon Nova Canvas 1.0 to generate a last visible asset that includes insights from profitable reference campaigns. The implementation follows the picture technology course of we detailed in our earlier weblog. For the entire Lambda perform code, see our GitHub repository.
Creating a brand new advertising marketing campaign: An end-to-end instance
We developed an intuitive interface that guides customers via the marketing campaign creation course of. The interface handles the complexity of AI-powered picture technology, solely requiring customers to offer their marketing campaign description and fundamental particulars. We stroll via the steps to create a advertising marketing campaign utilizing our resolution:
- Customers start by defining three key marketing campaign parts:
- Marketing campaign description: An in depth temporary that serves as the muse for picture technology.
- Marketing campaign goal: The advertising goal (for instance, Consciousness) that guides the visible technique.
- Goal node: The particular viewers phase (for instance, Clients) for content material focusing on.
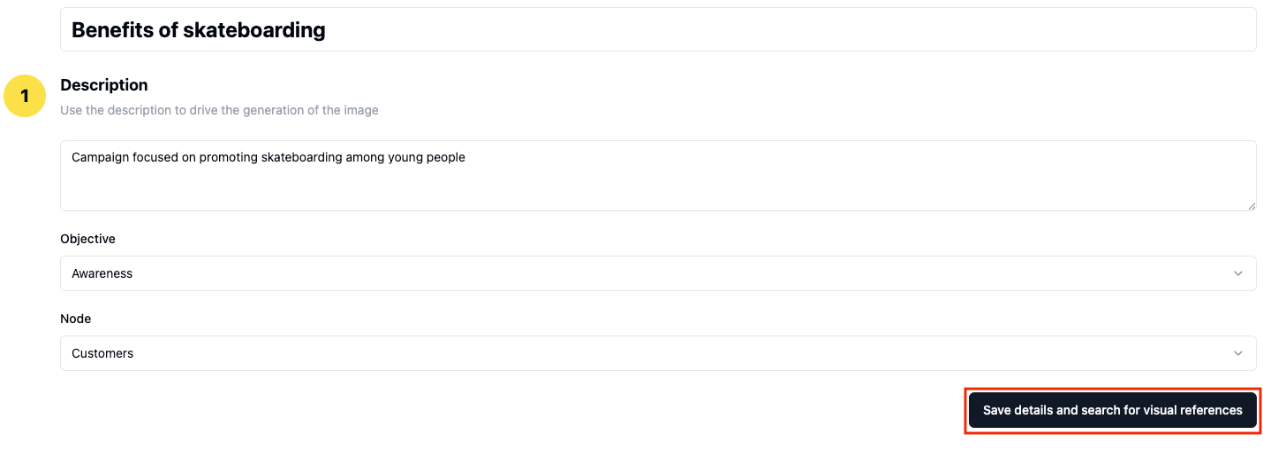
- Primarily based on the marketing campaign particulars, the system presents related photos from earlier profitable campaigns. Customers can evaluation and choose the photographs that align with their imaginative and prescient. These picks will information the picture technology course of.

- Utilizing the marketing campaign description and chosen reference photos, the system generates an enhanced immediate that serves because the enter for the ultimate picture technology step.

- Within the last step, our system generates visible belongings based mostly on the immediate that would probably be used as inspiration for a whole marketing campaign briefing.

How Bancolombia is utilizing Amazon Nova to streamline their advertising marketing campaign belongings technology
Bancolombia, certainly one of Colombia’s main banks, has been experimenting with this advertising content material creation method for greater than a 12 months. Their implementation supplies helpful insights into how this resolution might be built-in into established advertising workflows. Bancolombia has been in a position to streamline their inventive workflow whereas making certain that the generated visuals align with the marketing campaign’s strategic intent. Juan Pablo Duque, Advertising Scientist Lead at Bancolombia, shares his perspective on the affect of this know-how:
“For the Bancolombia workforce, leveraging historic imagery was a cornerstone in constructing this resolution. Our purpose was to instantly sort out three main trade ache factors:
- Lengthy and expensive iterative processes: By implementing meta-prompting methods and making certain strict model pointers, we’ve considerably diminished the time customers spend producing high-quality photos.
- Problem sustaining context throughout inventive variations: By figuring out and locking in key visible parts, we guarantee seamless consistency throughout all graphic belongings.
- Lack of management over outputs: The suite of methods built-in into our resolution supplies customers with a lot larger precision and management over the outcomes.
And that is only the start. This train permits us to validate new AI creations in opposition to our present library, making certain we don’t over-rely on the identical visuals and preserving our model’s look contemporary and fascinating.”
Clear up
To keep away from incurring future prices, you must delete all of the sources used on this resolution. As a result of the answer was deployed utilizing a number of AWS CDK stacks, you must delete them within the reverse order of deployment to correctly take away all sources. Observe these steps to wash up your surroundings:
- Delete the frontend stack:
- Delete the picture technology backend stack:
- Delete the picture indexing backend stack:
- Delete the OpenSearch roles stack:
The cdk destroy command will take away most sources robotically, however there is perhaps some sources that require guide deletion corresponding to S3 buckets with content material and OpenSearch collections. Be certain to examine the AWS Administration Console to confirm that every one sources have been correctly eliminated. For extra details about the cdk destroy command, see the AWS CDK Command Line Reference.
Conclusion
This publish has introduced an answer that enhances advertising content material creation by combining generative AI with insights from historic campaigns. Utilizing Amazon OpenSearch Serverless and Amazon Bedrock, we constructed a system that effectively searches and makes use of reference photos from earlier advertising campaigns. The system filters these photos based mostly on marketing campaign targets and goal audiences, serving to to make sure strategic alignment. These references then feed into our immediate engineering course of. Utilizing Amazon Nova Professional, we generate a immediate that mixes new marketing campaign necessities with insights from profitable previous campaigns, offering model consistency within the last picture technology.
This implementation represents an preliminary step in utilizing generative AI for advertising. The whole resolution, together with detailed implementations of the Lambda capabilities and configuration recordsdata, is accessible in our GitHub repository for adaptation to particular organizational wants.
For extra data, see the next associated sources:
In regards to the authors
 María Fernanda Cortés is a Senior Information Scientist on the Skilled Providers workforce of AWS. She’s targeted on designing and creating end-to-end AI/ML options to deal with enterprise challenges for purchasers globally. She’s enthusiastic about scientific information sharing and volunteering in technical communities.
María Fernanda Cortés is a Senior Information Scientist on the Skilled Providers workforce of AWS. She’s targeted on designing and creating end-to-end AI/ML options to deal with enterprise challenges for purchasers globally. She’s enthusiastic about scientific information sharing and volunteering in technical communities.
 David Laredo is a Senior Utilized Scientist at Amazon, the place he helps innovate on behalf of consumers via the appliance of state-of-the-art methods in ML. With over 10 years of AI/ML expertise David is a regional technical chief for LATAM who continually produces content material within the type of blogposts, code samples and public talking periods. He at the moment leads the AI/ML skilled group in LATAM.
David Laredo is a Senior Utilized Scientist at Amazon, the place he helps innovate on behalf of consumers via the appliance of state-of-the-art methods in ML. With over 10 years of AI/ML expertise David is a regional technical chief for LATAM who continually produces content material within the type of blogposts, code samples and public talking periods. He at the moment leads the AI/ML skilled group in LATAM.
 Adriana Dorado is a Pc Engineer and Machine Studying Technical Area Group (TFC) member at AWS, the place she has been for five years. She’s targeted on serving to small and medium-sized companies and monetary providers prospects to architect on the cloud and leverage AWS providers to derive enterprise worth. Outdoors of labor she’s enthusiastic about serving because the Vice President of the Society of Girls Engineers (SWE) Colombia chapter, studying science fiction and fantasy novels, and being the proud aunt of a gorgeous niece.
Adriana Dorado is a Pc Engineer and Machine Studying Technical Area Group (TFC) member at AWS, the place she has been for five years. She’s targeted on serving to small and medium-sized companies and monetary providers prospects to architect on the cloud and leverage AWS providers to derive enterprise worth. Outdoors of labor she’s enthusiastic about serving because the Vice President of the Society of Girls Engineers (SWE) Colombia chapter, studying science fiction and fantasy novels, and being the proud aunt of a gorgeous niece.
 Yunuen Piña is a Options Architect at AWS, specializing in serving to small and medium-sized companies throughout Mexico to rework their concepts into revolutionary cloud options that drive enterprise development.
Yunuen Piña is a Options Architect at AWS, specializing in serving to small and medium-sized companies throughout Mexico to rework their concepts into revolutionary cloud options that drive enterprise development.
 Juan Pablo Duque is a Advertising Science Lead at Bancolombia, the place he merges science and advertising to drive effectivity and effectiveness. He transforms advanced analytics into compelling narratives. Enthusiastic about GenAI in MarTech, he writes informative weblog posts. He leads knowledge scientists devoted to reshaping the advertising panorama and defining new methods to measure.
Juan Pablo Duque is a Advertising Science Lead at Bancolombia, the place he merges science and advertising to drive effectivity and effectiveness. He transforms advanced analytics into compelling narratives. Enthusiastic about GenAI in MarTech, he writes informative weblog posts. He leads knowledge scientists devoted to reshaping the advertising panorama and defining new methods to measure.