

{kind=link}
Sport studios generate large quantities of participant and gameplay telemetry, however reworking that information into significant insights is usually sluggish, technical, and depending on SQL experience. With the brand new Amazon Redshift integration for Amazon Bedrock Information Bases, groups can unlock on the spot, AI-powered analytics by asking questions in pure language. Analysts, product managers, and designers can now discover Amazon Redshift information conversationally—no question writing required—and Amazon Bedrock routinely generates optimized SQL, executes it on Amazon Redshift, and returns clear, actionable solutions. This brings collectively the dimensions and efficiency of Amazon Redshift with the intelligence of Amazon Bedrock, enabling sooner selections, deeper participant understanding, and extra partaking recreation experiences.
Amazon Redshift can be utilized as a structured information supply for Amazon Bedrock Information Bases, permitting for pure language querying and retrieval of data from Amazon Redshift. Amazon Bedrock Information Bases can rework pure language queries into SQL queries, so customers can retrieve information straight from the supply with no need to maneuver or preprocess the information. A recreation analyst can now ask, “What number of gamers accomplished all the degrees in a recreation?” or “Checklist the highest 5 gamers by the variety of occasions the sport was performed,” and Amazon Bedrock Information Bases routinely interprets that question into SQL, runs the question towards Amazon Redshift, and returns the outcomes—and even supplies a summarized narrative response.
To generate correct SQL queries, Amazon Bedrock Information Bases makes use of database schema, earlier question historical past, and different area or enterprise data similar to desk and column annotations which can be offered in regards to the information sources. On this submit, we talk about a few of the finest practices to enhance accuracy whereas interacting with Amazon Bedrock utilizing Amazon Redshift because the data base.
Resolution overview
On this submit, we illustrate the most effective practices utilizing gaming trade use instances. You’ll converse with gamers and their recreation makes an attempt information in pure language and get the response again in pure language. Within the course of, you’ll be taught the most effective practices. To comply with together with the use case, comply with these high-level steps:
- Load recreation makes an attempt information into the Redshift cluster.
- Create a data base in Amazon Bedrock and sync it with the Amazon Redshift information retailer.
- Evaluate the approaches and finest practices to enhance the accuracy of response from the data base.
- Full the detailed walkthrough for outlining and utilizing curated queries to enhance the accuracy of responses from the data base.
Stipulations
To implement the answer, you should full the next conditions:
Load recreation makes an attempt and gamers information
To load the datasets to Amazon Redshift, full the next steps:
- Open Amazon Redshift Question Editor V2 or one other SQL editor of your selection and hook up with the Redshift database.
- Run the next SQL to create the information tables to retailer video games makes an attempt and participant particulars:
- Obtain the recreation makes an attempt and gamers datasets to your native storage.
- Create an Amazon Easy Storage Service (Amazon S3) bucket with a novel title. For directions, discuss with Making a basic function bucket.
- Add the downloaded recordsdata into your newly created S3 bucket.
- Utilizing the next COPY command statements, load the datasets from Amazon S3 into the brand new tables you created in Amazon Redshift. Change
<with the title of your S3 bucket and> <together with your AWS Area:>
Create data base and sync
To create a data base and sync your information retailer together with your data base, full these steps:
- Observe the steps at Create a data base by connecting to a structured information retailer.
- Observe the steps at Sync your structured information retailer together with your Amazon Bedrock data base.
Alternatively, you possibly can refer Step 4: Arrange Bedrock Information Bases in Accelerating Genomic Knowledge Discovery with AI-Powered Pure Language Queries within the AWS for Industries weblog.
Approaches to enhance the accuracy
Should you’re not getting the anticipated response from the data base, you possibly can take into account these key methods:
- Present extra info within the Question Era Configuration. The data base’s response accuracy could be improved by offering supplementary info and context to assist it higher perceive your particular use case.
- Use consultant pattern queries. Working instance queries that replicate frequent use instances helps practice the data base in your database’s particular patterns and conventions.
Contemplate a database that shops participant info utilizing nation codes reasonably than full nation names. By working pattern queries that show the connection between nation names and their corresponding codes (for instance, “USA” for “United States”), you assist the data base perceive the right way to correctly translate consumer requests that reference full nation names into queries utilizing the proper nation codes. This strategy helps join pure language requests and your database’s particular implementation particulars, leading to extra correct question era.
Earlier than we dive into extra optimizations choices, let’s discover how one can personalize the question engine to generate queries for a particular question engine. On this walkthrough, we use Amazon Redshift. Amazon Bedrock Information Bases analyzes three key elements to generate correct SQL queries:
- Database metadata
- Question configurations
- Historic question and dialog information
The next graphic illustrates this move.
You possibly can configure these settings to boost question accuracy in two methods:
- When creating a brand new Amazon Redshift data base
- By modifying the question engine settings of an current data base
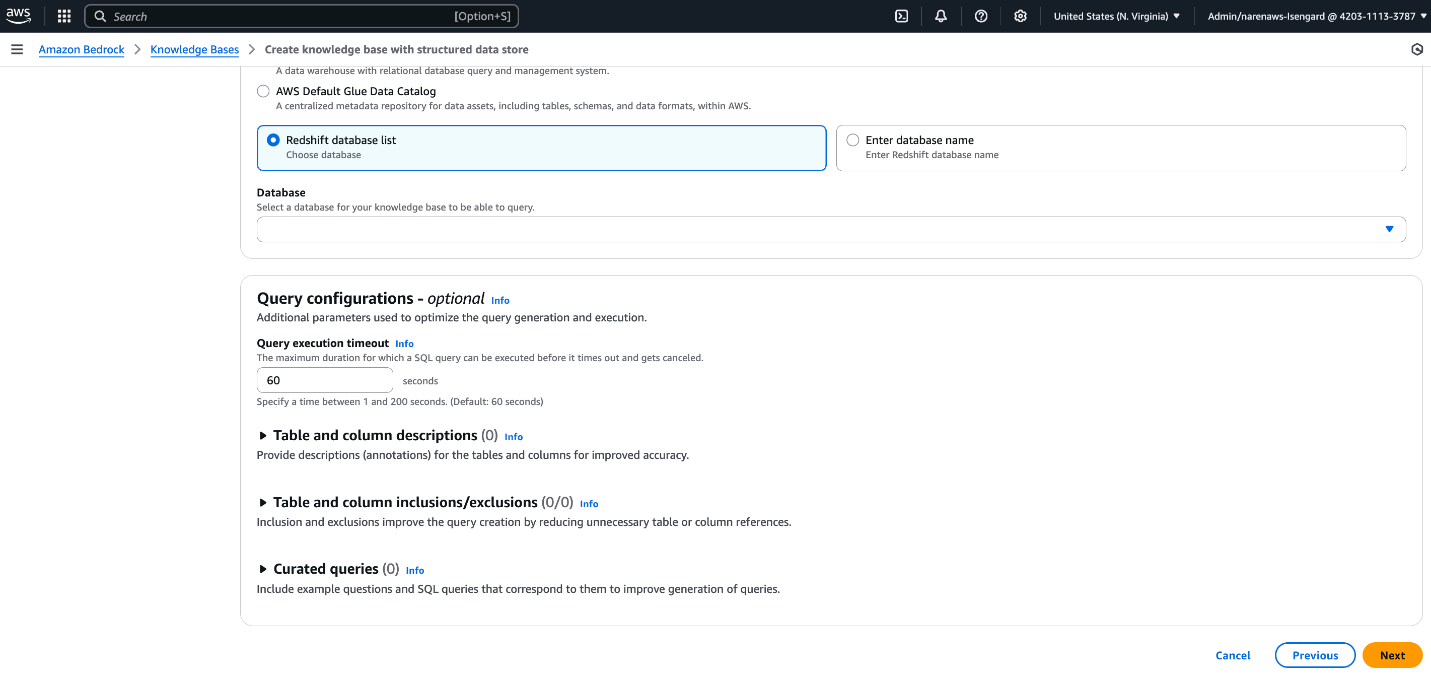
To configure setting when creating new data base, comply with steps on Create a data base by connecting to a structured information retailer and configure under parameters in (Elective) Question configurations part as proven in following screenshot:
- Desk and column descriptions
- Desk and column inclusions/exclusions
- Curated queries
To configure setting when modifying the question engine of an current data base, comply with these steps:
- On the Amazon Bedrock console within the left navigation pane, select Information Bases and choose your Redshift Information Base.
- Select your question engine and select Edit,
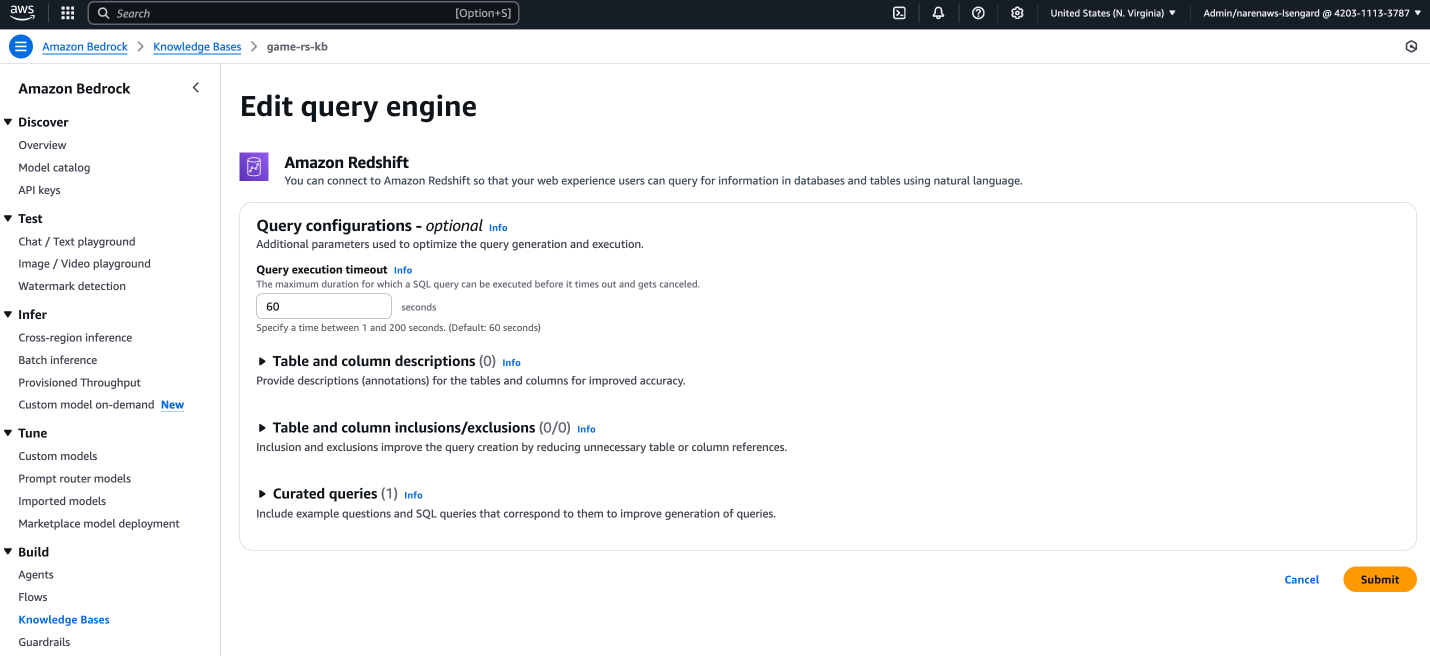
- Configure under parameters in (Elective) Question configurations part as proven in following screenshot:
- Desk and column descriptions
- Desk and column inclusions/exclusions
- Curated queries
Let’s discover the obtainable question configuration choices in additional element to know how these assist the data base generate a extra correct response.
Desk and column descriptions present important metadata that helps Amazon Bedrock Information Bases perceive your information construction and generate extra correct SQL queries. These descriptions can embrace desk and column functions, utilization pointers, enterprise context, and information relationships.
Observe these finest practices for descriptions:
- Use clear, particular names as a substitute of summary identifiers
- Embody enterprise context for technical fields
- Outline relationships between associated columns
For instance, take into account a gaming desk with timestamp columns named t1, t2, and t3. Including these descriptions helps the data base generate acceptable queries. For instance, if t1 is play begin time, t2 is play finish time, and t3 is file creation time, including these descriptions will point out to the data base to make use of t2–t1 for locating the sport length.
Curated queries are a set of predefined query and reply examples. Questions are written as pure language queries (NLQs) and solutions are the corresponding SQL question. These examples assist the SQL era course of by offering examples of the sorts of queries that ought to be generated. They function reference factors to enhance the accuracy and relevance of generative SQL outputs. Utilizing this feature, you possibly can present some instance queries to the data base for it perceive customized vocabulary additionally. For instance, if the nation area within the desk is populated with a rustic code, including an instance question will assist the data base to transform the nation title to a rustic code earlier than working the question to reply questions on the information of gamers in a particular nation. You too can present some instance complicated queries to assist the data base to reply to extra complicated questions. The next is an instance question that may be added to the data base:
With desk and column inclusion and exclusion, you possibly can specify a set of tables or columns to be included or excluded for SQL era. This area is essential if you wish to restrict the scope of SQL queries to an outlined subset of obtainable tables or columns. This selection can assist optimize the era course of by lowering pointless desk or column references. You too can use this feature to:
- Exclude redundant tables, for instance, these generated by copying the unique desk to run a posh evaluation
- Exclude tables and columns containing delicate information
Should you specify inclusions, all different tables and columns are ignored. Should you specify exclusions, the tables and columns you specify are ignored.
Walkthrough for outlining and utilizing curated queries to enhance accuracy
To outline and use curated queries to enhance accuracy, full the next steps.
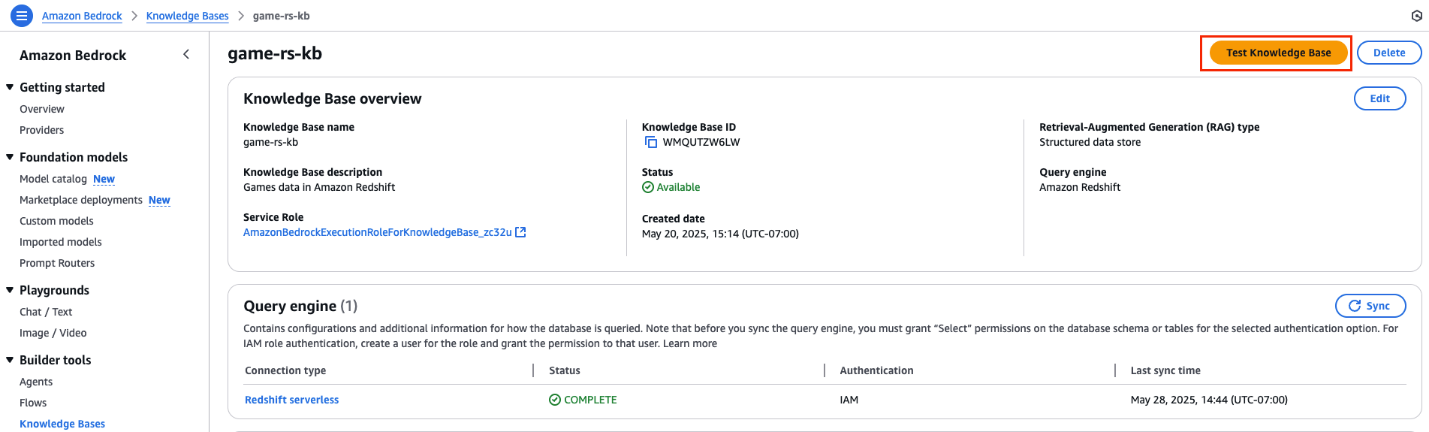
- On the AWS Administration Console, navigate to Amazon Bedrock and within the left navigation pane, select Information Bases. Choose the data base you created with Amazon Redshift.
- Select Take a look at Information Base, as proven within the following screenshot, to validate the accuracy of the data base response.
- On the Take a look at Information Base display beneath Retrieval and response era, select Retrieval and response era: information sources and mannequin.
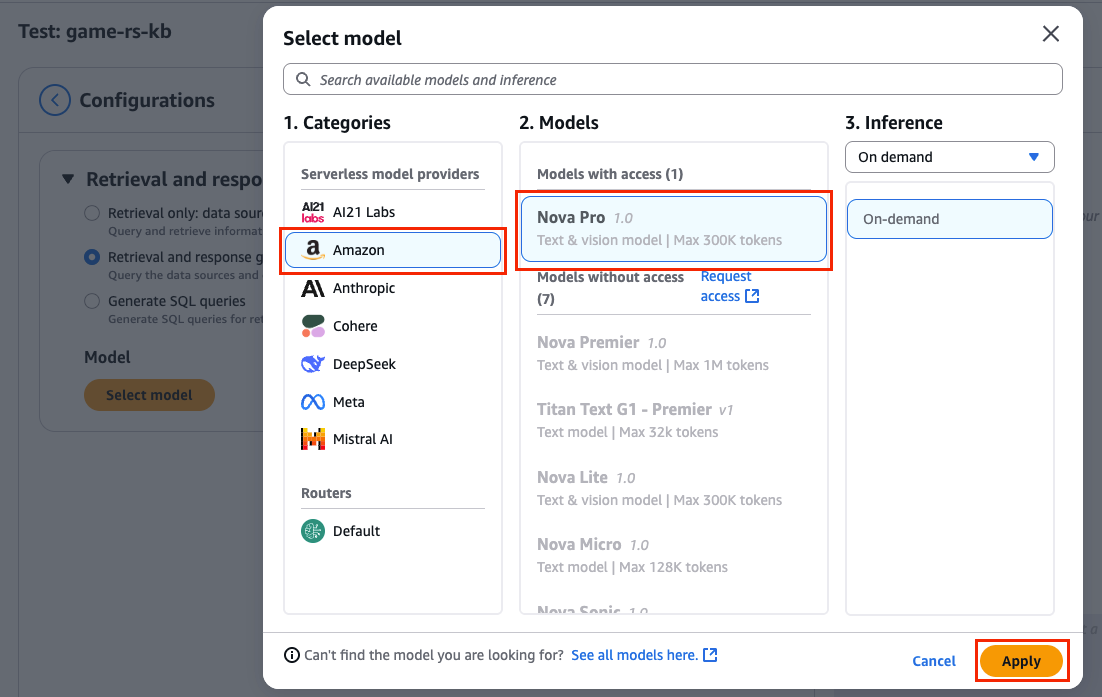
- Select Choose mannequin to choose a massive language mannequin (LLM) to transform the SQL question response from the data base to a pure language response.
- Select Nova Professional within the popup and select Apply, as proven within the following screenshot.
Now you might have Amazon Nova Professional linked to your data base to reply to your queries based mostly on the information obtainable in Amazon Redshift. You possibly can ask some questions and confirm them with precise information in Amazon Redshift. Observe these steps:
- Within the Take a look at part on the fitting, enter the next immediate, then select the ship message icon, as proven within the following screenshot.
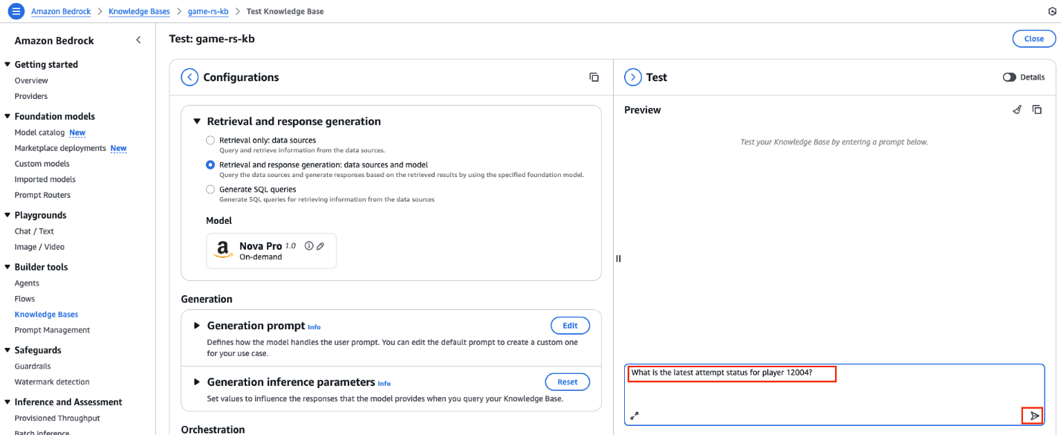
- Amazon Nova Professional generates a response utilizing the information saved within the Redshift data base.
- Select Particulars to see the SQL question generated and utilized by Amazon Nova Professional, as proven within the following screenshot.
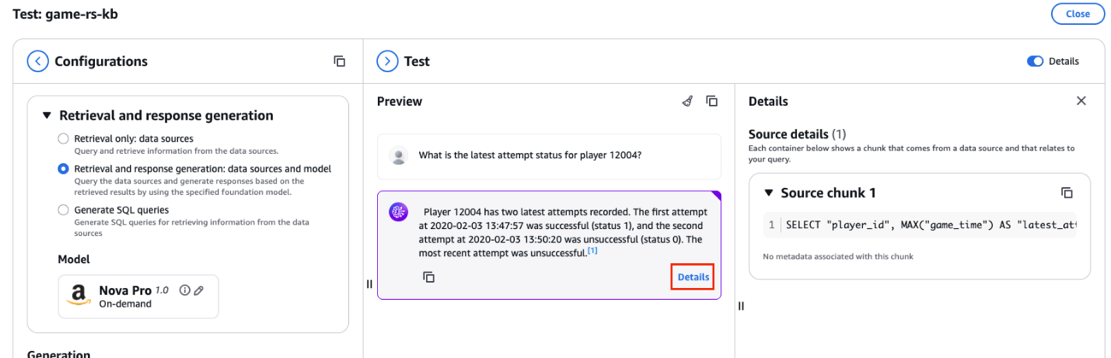
- Copy the question and enter it in question editor v2 of the Redshift data base, as proven within the following screenshot.
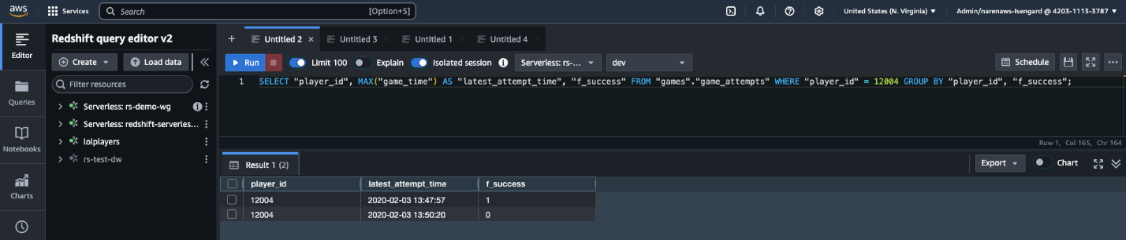
- Confirm that the response generated by Amazon Nova Professional in pure language matches the information in Amazon Redshift and that the generated SQL question can be correct.
You possibly can attempt some extra inquiries to confirm the Amazon Nova Professional response, for instance:
However what if the response generated by the data base isn’t correct? In these instances, you possibly can add extra context the data base can use to offer extra correct responses. For instance, attempt asking the next query:
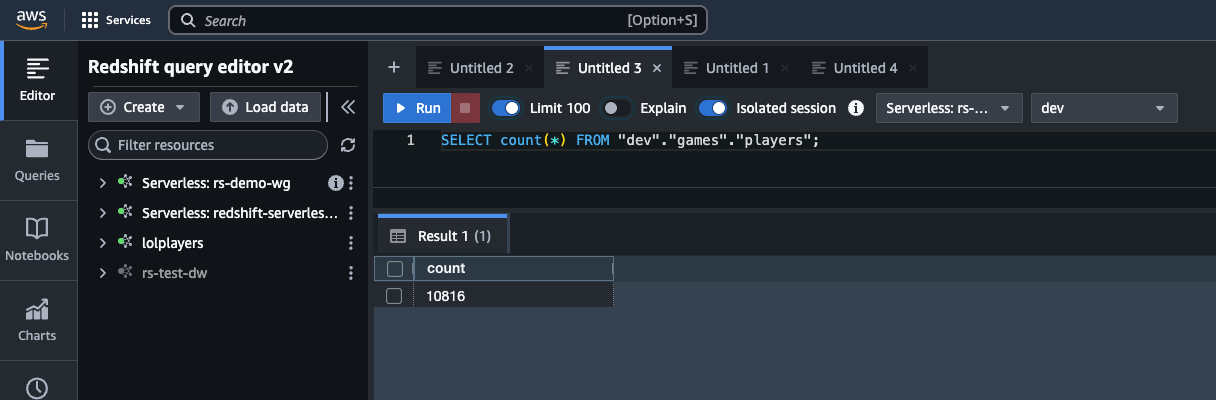
On this case, the response generated by the data base doesn’t match the precise participant rely in Amazon Redshift. The data base reported about 13,589 gamers and generated the next question to get the participant rely:
The next screenshot reveals this query and consequence.
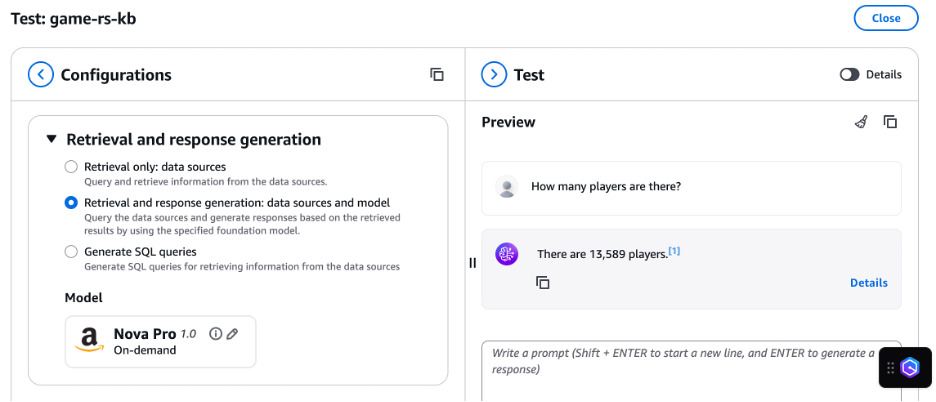
The data base ought to have used the gamers desk in Amazon Redshift to search out the distinctive gamers. The proper response is 10,816 gamers.
To assist the data base, add a curated question for it to make use of the gamers desk as a substitute of the makes an attempt desk to search out the full participant rely. Observe these steps:
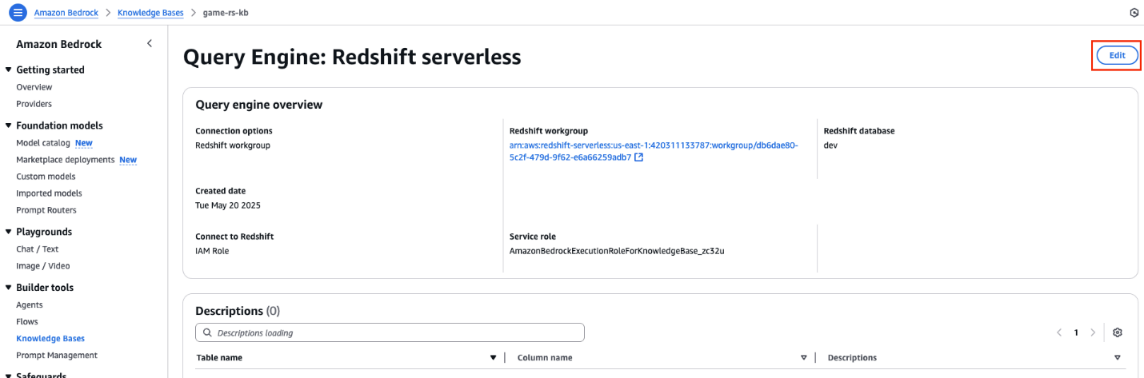
- On the Amazon Bedrock console within the left navigation pane, select Information Bases and choose your Redshift Information Base.
- Select your question engine and select Edit, as proven within the following screenshot.
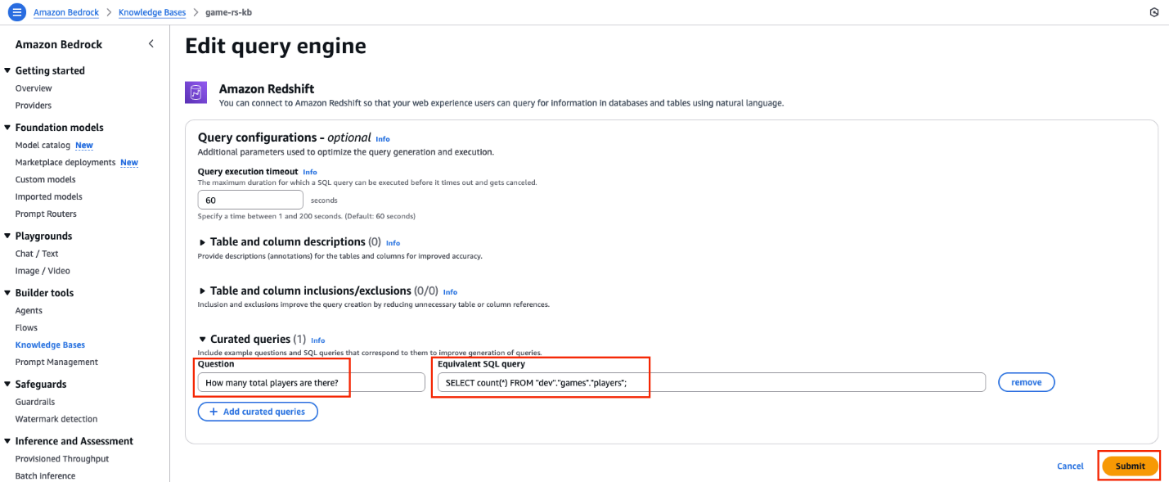
- Increase the Curated queries part and enter the next:
- Within the Questions area, enter
What number of complete gamers are there?. - Within the Equal SQL question area, enter
SELECT rely(*) FROM “dev”,“video games”,“gamers”;. - Select Submit, as proven within the following screenshot.
- Navigate again to your data base and question engine. Select Sync to sync the data base. This begins the metadata ingestion course of in order that information could be retrieved. The metadata permits Amazon Bedrock Information Bases to translate consumer prompts into a question for the linked database. Confer with Sync your structured information retailer together with your Amazon Bedrock data base for extra particulars.
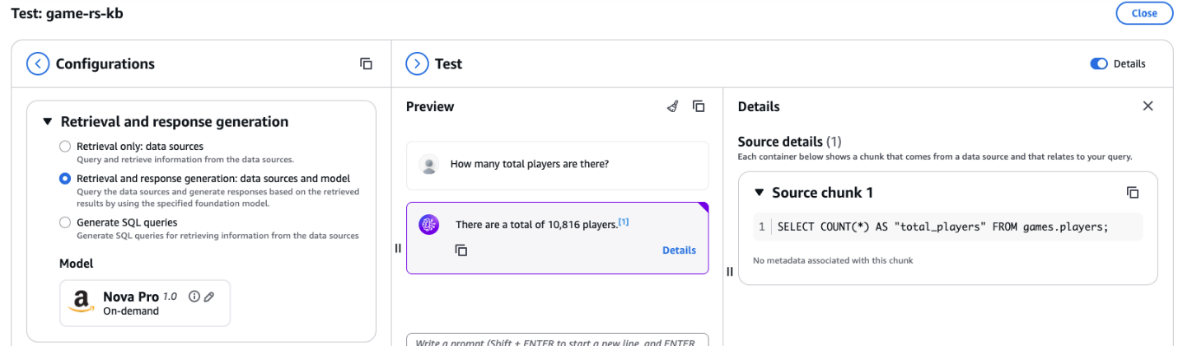
- Return to Take a look at Information Base with Amazon Nova Professional and repeat the query about what number of complete gamers there are, as proven within the following screenshot. Now, the response generated by the data base matches the information in participant desk in Amazon Redshift, and the question generated by the data base makes use of the curated question with the participant desk as a substitute of the makes an attempt desk to find out the participant rely.
Cleanup
For the walkthrough part, we used serverless companies, and your value will likely be based mostly in your utilization of those companies. Should you’re utilizing provisioned Amazon Redshift as a data base, comply with these steps to cease incurring prices:
- Delete the data base in Amazon Bedrock.
- Shut down and delete your Redshift cluster.
Conclusion
On this submit, we mentioned how you need to use Amazon Redshift as a data base to offer extra context to your LLM. We recognized finest practices and defined how one can enhance the accuracy of responses from the data base by following these finest practices.
Concerning the authors

Narendra Gupta
Narendra is a Specialist Options Architect at AWS, serving to clients on their cloud journey with a concentrate on AWS analytics companies. Outdoors of labor, Narendra enjoys studying new applied sciences, watching motion pictures, and visiting new locations.