

{kind=link}
Massive Language Fashions (LLMs) are the center of Agentic methods and RAG methods. And constructing with LLMs is thrilling till the size makes them costly. There’s at all times a tradeoff for price vs high quality, however on this article we’ll discover the ten finest methods based on me that may slash prices for the LLM utilization whereas specializing in sustaining the standard of the system. Additionally be aware I’ll be utilizing OpenAI API for the inference however the methods may very well be utilized to different mannequin suppliers as properly. So with none additional ado let’s perceive the associated fee equation and see methods of LLM price optimization.
Prerequisite: Understanding the Value Equation
Earlier than we begin, it’s higher we get higher versed with about prices, tokens and context window:
- Tokens: These are the small items of the textual content. For all sensible functions you possibly can assume 1,000 tokens is roughly 750 phrases.
- Immediate Tokens: These are the enter tokens that we ship to the mannequin. They’re typically cheaper.
- Completion Tokens: These are the tokens generated by the mannequin. They’re typically 3-4 occasions dearer than enter tokens.
- Context Window: This is sort of a short-term reminiscence (It might embody the outdated Inputs + Outputs). In the event you exceed this restrict, the mannequin leaves out the sooner components of the dialog. In the event you ship 10 earlier messages within the context window, then these rely as Enter Tokens for the present request and can add to the prices.
- Complete Value: (Enter Tokens x Per Enter Token Value) + (Output Tokens x Per Output Token Value)
Observe: For OpenAI you should use the billing dashboard to trace prices: https://platform.openai.com/settings/group/billing/overview
To discover ways to get the OpenAI API learn this article.
1. Route Requests to the Proper Mannequin
Not each process requires the most effective, state-of-the-art mannequin, you possibly can experiment with a less expensive mannequin or attempt utilizing a few-shot prompting with a less expensive mannequin to duplicate a much bigger mannequin.
Configure the API key
from google.colab import userdata
import os
os.environ['OPENAI_API_KEY']=userdata.get('OPENAI_API_KEY') Outline the features
from openai import OpenAI
shopper = OpenAI()
SYSTEM_PROMPT = "You're a concise, useful assistant. You reply in 25-30 phrases"
def generate_examples(questions, n=3):
examples = []
for q in questions[:n]:
response = shopper.chat.completions.create(
mannequin="gpt-5.1",
messages=[{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": q}]
)
examples.append({"q": q, "a": response.selections[0].message.content material})
return examplesThis operate makes use of the bigger GPT-5.1 and solutions the query in 25-30 phrases.
# Instance utilization
questions = [
"What is overfitting?",
"What is a confusion matrix?",
"What is gradient descent?"
]
few_shot = generate_examples(questions, n=3)Nice, we obtained our question-answer pairs.
def build_prompt(examples, query):
immediate = ""
for ex in examples:
immediate += f"Q: {ex['q']}nA: {ex['a']}nn"
return immediate + f"Q: {query}nA:"
def ask_small_model(examples, query):
immediate = build_prompt(examples, query)
response = shopper.chat.completions.create(
mannequin="gpt-5-nano",
messages=[{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt}]
)
return response.selections[0].message.content materialRight here, we’ve got a operate that makes use of smaller ‘gpt-5-nano’ and one other operate that makes the immediate utilizing the question-answer pairs for the mannequin.
reply = ask_small_model(few_shot, "Clarify regularization in ML.")
print(reply)Let’s move a query to the mannequin.
Output:
Regularization provides a penalty to the loss for mannequin complexity to scale back overfitting. Widespread varieties embody L1 (lasso) selling sparsity and L2 (ridge) shrinking weights; elastic web blends.
Nice! We have now used a less expensive mannequin (gpt-5-nano) to get our output, however certainly we are able to’t use the cheaper mannequin for each process.
2. Use Fashions based on the duty
The thought right here is to make use of a smaller mannequin for routine duties, and utilizing the bigger fashions just for advanced reasoning. So how will we do that? Right here we’ll outline a classifier that returns “easy” or “advanced” and route the queries accordingly. That is assist us save prices on routine prices.
Instance:
from openai import OpenAI
shopper = OpenAI()
def get_complexity(query):
immediate = f"Fee the complexity of the query from 1 to 10 for an LLM to reply. Present solely the quantity.nQuestion: {query}"
res = shopper.chat.completions.create(
mannequin="gpt-5.1",
messages=[{"role": "user", "content": prompt}],
)
return int(res.selections[0].message.content material.strip())
print(get_complexity("Clarify convolutional neural networks"))Output:
4
So our classifier says the complexity is 4, don’t fear concerning the further LLM name as that is producing solely a single quantity. This complexity quantity can be utilized to route the duties, like: complexity < 7 then path to a smaller mannequin, else a bigger mannequin.
3. Utilizing Immediate Caching
If the LLM-system makes use of cumbersome system directions or a number of few-shot examples throughout many calls, then ensure to put them on the begin of your message.
Few necessary factors right here:
- Make sure the prefix is precisely similar throughout requests (together with all of the characters, whitespace included).
- In line with OpenAI the supported fashions will mechanically profit from Caching however the immediate needs to be longer than 1,024 tokens.
- Requests utilizing Immediate Caching have a
cached_tokensworth as part of the response.
4. Use the Batch API for Duties that may wait
Many duties don’t require rapid responses, that is the place we are able to use the asynchronous Batch endpoint for the inference. By submitting a file of requests and giving OpenAI upto 24 hours time to course of them, will scale back 50% prices on token prices in comparison with the standard OpenAI API calls.
5. Trim the Outputs with max_tokens and Stops parameters
What we’re attempting to do right here is cease the untrolled token era, Let’s say you want a 75-word abstract or a particular JSON object, don’t let the mannequin maintain producing pointless textual content. As a substitute we are able to make use of the parameters:
Instance:
from openai import OpenAI
shopper = OpenAI()
response = shopper.chat.completions.create(
mannequin="gpt-5.1",
messages=[
{
"role": "system",
"content": "You are a data extractor. Output only raw JSON."
}
],
max_tokens=100,
cease=["nn", "}"]
)We have now set max_tokens as 100 because it’s roughly 75 phrases.
6. Make Use of RAG
As a substitute of flooding the context window, we are able to use Retrieval-Augmented Technology. This can assist convert the information base into embeddings and retailer them in a vector database. When a consumer queries, then all of the context gained’t be within the context window however the retrieved high few related textual content chunks can be handed for context.
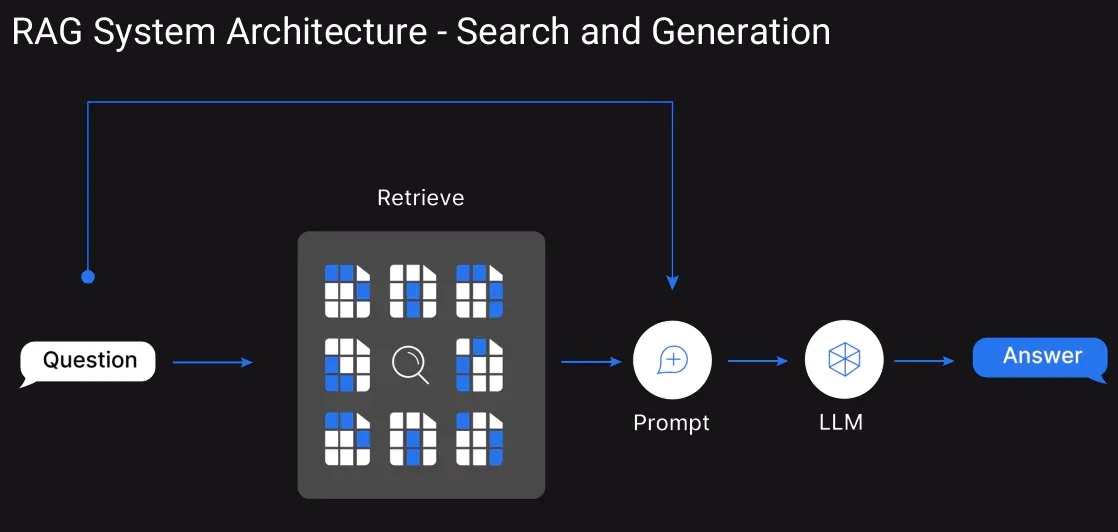
7. At all times Handle the Dialog Historical past
Right here our focus is on the dialog historical past the place we move the older inputs and outputs. As a substitute of iteratively including the conversations we are able to implement a “sliding window” method.
Right here we drop the oldest messages as soon as the context will get too lengthy (set a threshold), or summarize earlier turns right into a single system message earlier than persevering with. Be sure that the energetic context window is just not too lengthy because it’s essential for long-running periods.
Operate for summarization
from openai import OpenAI
shopper = OpenAI()
SYSTEM_PROMPT = "You're a concise assistant. Summarize the chat historical past in 30-40 phrases."
def summarize_chat(history_text):
response = shopper.chat.completions.create(
mannequin="gpt-5.1",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": history_text}
]
)
return response.selections[0].message.content materialInference
chat_history = """
Person: Hello, I am attempting to know how embeddings work.
Assistant: Embeddings flip textual content into numeric vectors.
Person: Can I take advantage of them for similarity search?
Assistant: Sure, that’s a standard use case.
Person: Good, present me easy code.
Assistant: Positive, this is a brief instance...
"""
abstract = summarize_chat(chat_history)Person requested what embeddings are; assistant defined they convert textual content to numeric vectors. Person then requested about utilizing embeddings for similarity search; assistant confirmed and offered a brief instance code snippet demonstrating fundamental similarity search.
We now have a abstract which will be added to the mannequin’s context window when the enter tokens are above an outlined threshold.
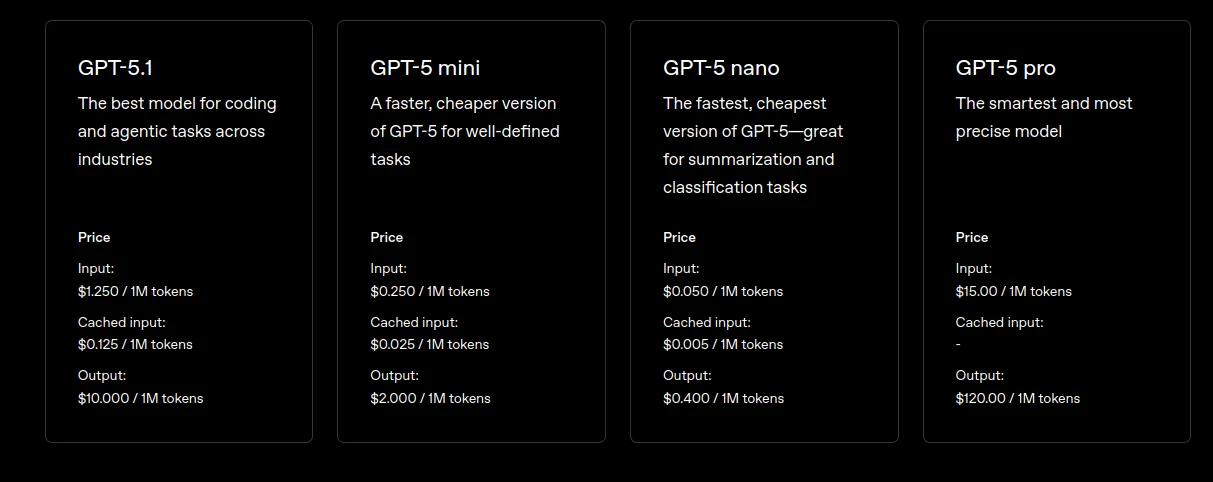
8. Improve to Environment friendly Mannequin Modes
OpenAI regularly releases optimized variations of their fashions. At all times test for newer “Mini,” or “Nano” variants of the newest fashions. These are particularly made for effectivity, typically delivering comparable efficiency for sure duties at a fraction of the associated fee.
9. Implement Structured Outputs (JSON)
While you want knowledge extracted or formatted. Defining a strict schema forces the mannequin to chop the pointless tokens and returns solely the precise knowledge fields requested. Denser responses imply fewer generated tokens in your invoice.
Imports and Construction Definition
from openai import OpenAI
import json
shopper = OpenAI()
immediate = """
You might be an extraction engine. Output ONLY legitimate JSON.
No explanations. No pure language. No further keys.
Extract these fields:
- title (string)
- date (string, format: YYYY-MM-DD)
- entities (array of strings)
Textual content:
"On 2025-12-05, OpenAI launched Structured Outputs, permitting builders to implement strict JSON schemas. This improved reliability was welcomed by many engineers."
Return JSON on this precise format:
{
"title": "",
"date": "",
"entities": []
}
"""Inference
response = shopper.chat.completions.create(
mannequin="gpt-5.1",
messages=[{"role": "user", "content": prompt}]
)
knowledge = response.selections[0].message.content material
json_data = json.masses(knowledge)
print(json_data)Output:
{'title': 'OpenAI Introduces Structured Outputs', 'date': '2025-12-05', 'entities': ['OpenAI', 'Structured Outputs', 'JSON', 'developers', 'engineers']}
As we are able to see solely the required dictionary with the required particulars is returned. Additionally the output is neatly structured as key-value pairs.
10. Cache Queries
In contrast to our earlier thought of caching, that is fairly completely different. If the customers regularly ask the very same questions, cache the LLM’s response in your individual database. Test this database earlier than calling the API. This cached response is quicker for the consumer and is virtually free. Additionally if working with LangGraph for Brokers then you possibly can discover this for Node-level-caching: Caching in LangGraph
Conclusion
Constructing with LLMs is highly effective however the scale can shortly make them costly, so understanding the associated fee equation turns into important.By making use of the correct mix of mannequin routing, caching, structured outputs, RAG, and environment friendly context administration, we are able to considerably slash inference prices. These methods assist keep the standard of the system whereas making certain the general LLM utilization stays sensible and cost-effective. Don’t overlook to take test the billing dashboard for the prices after implementing every method.
Continuously Requested Questions
A. A token is a small unit of textual content, the place roughly 1,000 tokens correspond to about 750 phrases.
A. As a result of output tokens (from the mannequin) are sometimes a number of occasions dearer per token than enter (immediate) tokens.
A. The context window is the short-term reminiscence (earlier inputs and outputs) despatched to the mannequin; an extended context will increase token utilization and thus price.
Captivated with know-how and innovation, a graduate of Vellore Institute of Know-how. At the moment working as a Information Science Trainee, specializing in Information Science. Deeply concerned with Deep Studying and Generative AI, wanting to discover cutting-edge methods to resolve advanced issues and create impactful options.
Login to proceed studying and luxuriate in expert-curated content material.